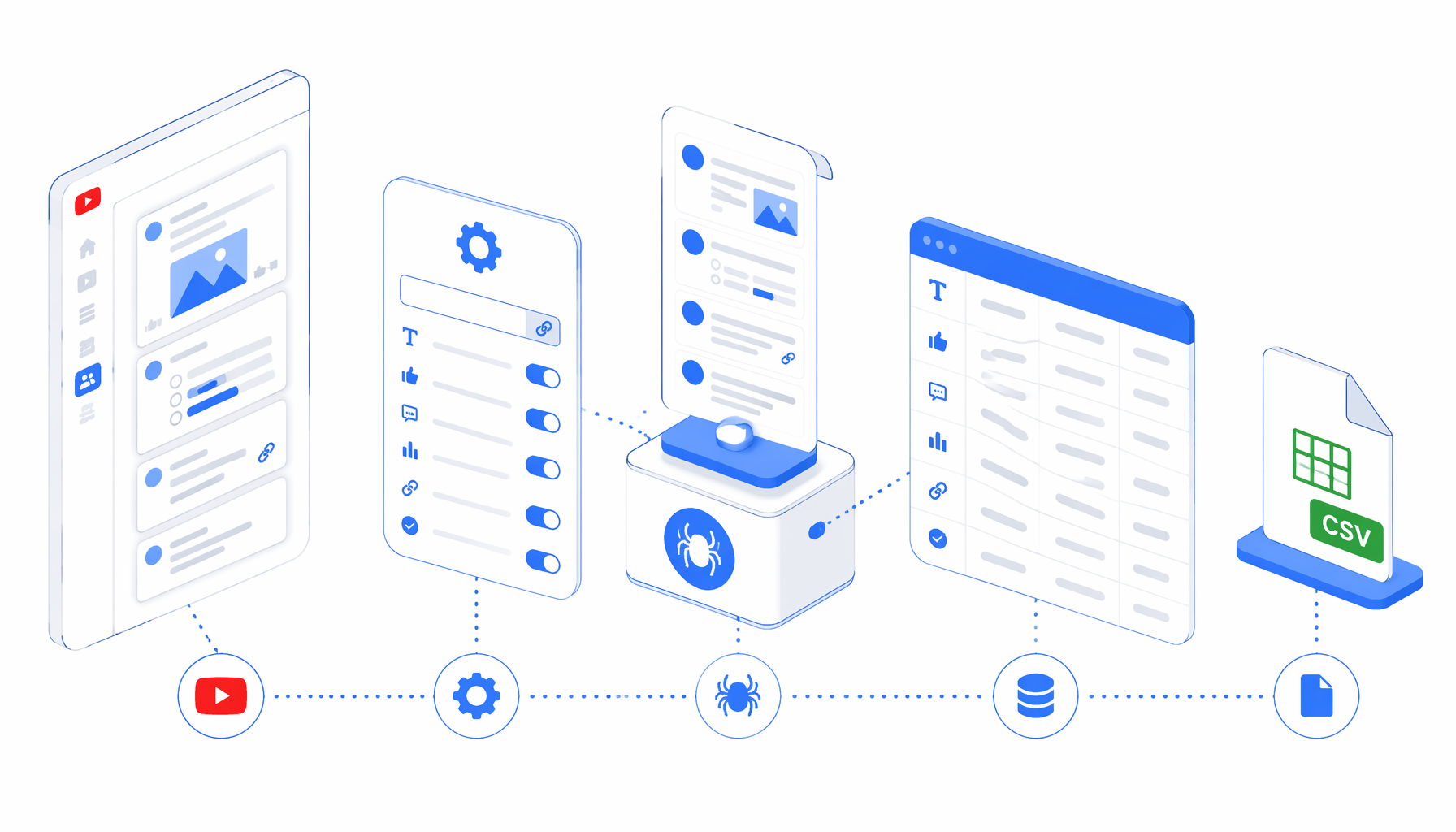
This tutorial shows how to scrape YouTube Community posts into CSV with the YouTube Community Scraper template for UScraper. You will choose input URLs, import the workflow, set the export path, validate the CSV, and handle blocked rows.
Prerequisites
Before you scrape YouTube Community posts
Start with UScraper installed as a local desktop app, a short list of public Community URLs, and a folder for the CSV. Good inputs look like https://www.youtube.com/@example/community or direct links that contain /post/. Test two direct posts and one channel page before scaling.
You also need a documented reason for collecting the data. Public visibility does not automatically mean you can republish, resell, profile, or train models on the export. Read the YouTube Terms of Service and YouTube API Services Terms, keep batches modest, and stop when YouTube shows login, consent, CAPTCHA, age, region, or unusual-traffic prompts.
Treat the first run as a QA run, not a production dataset. If YouTube does not show the post in a normal browser session, the scraper should not try to force it.
Choose a path
YouTube Community API vs scraper vs JavaScript
The official YouTube Data API reference is the right starting point for sanctioned resources such as channels, videos, playlists, captions, comments, and search. Community tab posts are different: there is no simple first-class API route that exports a channel's Community feed like commentThreads.list exports video comments. That is why searches for scrape YouTube Community tab, scrape YouTube Community JavaScript, and YouTube Community posts scraper often lead to scripts, hosted actors, or browser workflows.
| Path | Best for | Trade-off |
|---|---|---|
| UScraper template | Local CSV from approved URLs | Best-effort browser extraction; selectors can drift |
| Official YouTube API | Sanctioned production integrations | Community coverage may not match the visible tab |
| Custom JavaScript or Python | Source-controlled parsing logic | You own retries, blockers, compliance, and exports |
| Hosted scraping actor | Cloud scheduling and managed runtime | URLs and output pass through a third party |
Workflow anatomy
How the YouTube Community scraper works
The template graph is direct: Set Window Size -> Navigate -> Wait for Page Load -> Sleep -> Inject JavaScript -> Wait for Element -> Structured Export -> Loop Continue. Navigate owns the inputs. JavaScript reads the visible post DOM, metadata, links, poll text, and blocker text, then creates one hidden .uscraper-community-post row for Structured Export.
The important design choice is that the workflow does not silently return nothing. If YouTube hides a feed or shows a bot check, the row still carries the source URL and a page_status value for review.
| CSV field group | Example columns | Validation check |
|---|---|---|
| Channel identity | channel_name, account, subscribers, bio | Confirm the handle matches the source channel. |
| Post content | post_date, post_text, post_url, hashtags | Open the post URL and compare the visible copy. |
| Engagement | like_count, comment_count | Treat blanks as optional when YouTube hides counts. |
| Attached assets | links_in_post, attached_video_title, attached_video_link | Check whether linked videos or outbound URLs are relevant to your analysis. |
| Poll and status | poll_options, poll_vote_count, source_url, page_status | Filter blocked rows before reporting totals. |
{
"rowSelector": ".uscraper-community-post",
"fileName": "youtube-community-scraper.csv",
"includeHeaders": true,
"fileMode": "append"
}
Runbook
How to scrape YouTube Community posts to CSV
Import the template
Open the YouTube Community Scraper template, download the JSON workflow, and import it into UScraper.
Replace input URLs
In Navigate, replace the sample links with approved channel Community URLs or direct /post/ URLs. Keep the first run to a few inputs.
Set the export folder
In Structured Export, confirm youtube-community-scraper.csv, headers enabled, append mode, and a project-specific save location.
Run one small batch
Start the workflow and watch the browser. Stop if YouTube asks for login, CAPTCHA, verification, or another blocked-access step.
Validate before scaling
Open the CSV, sort by page_status, spot-check loaded rows against the browser, and only then add more channel or post URLs.
After the first run, check that each input created one row. Direct post URLs usually produce stronger post fields. Channel Community URLs are useful for watchlists, but can show unavailable feeds, regional variation, or sign-in prompts.
Validation
Validate the Community export
Open the CSV before you use the data. Filter page_status first: keep loaded rows for analysis and investigate bot_or_login_prompt or community_unavailable rows separately.
| Symptom | Likely cause | Fix |
|---|---|---|
post_text is blank | Post module did not render or markup changed | Rerun one direct post URL before editing selectors. |
page_status says blocked | Login, consent, verification, or bot prompt appeared | Stop the batch and review permission constraints. |
| Counts are missing | YouTube hid counts or changed labels | Keep counts optional; validate against a visible post. |
| Poll options look noisy | Choice text mixed with surrounding labels | Spot-check one poll post and adjust the rule. |
| Rows repeat | Duplicate URL or resumed loop | Dedupe by source_url, post_url, and post_text. |
Related workflows
Where this fits in your YouTube scraping workflow
Community posts help with creator campaign review, audience research, launch monitoring, and competitive tracking. For a broader YouTube dataset, pair this tutorial with the UScraper template library: use Community exports for creator posts, comments exports for viewer response, and transcript exports for spoken video content.
Browse more tutorials in the UScraper blog, then download the YouTube Community Scraper template when you are ready to run a small CSV test.
FAQ
Frequently asked questions
Automating YouTube can be restricted by terms, API policies, robots directives, copyright rules, privacy law, and local regulations. Use modest runs, do not bypass login or bot checks, and get legal review before commercial reuse.