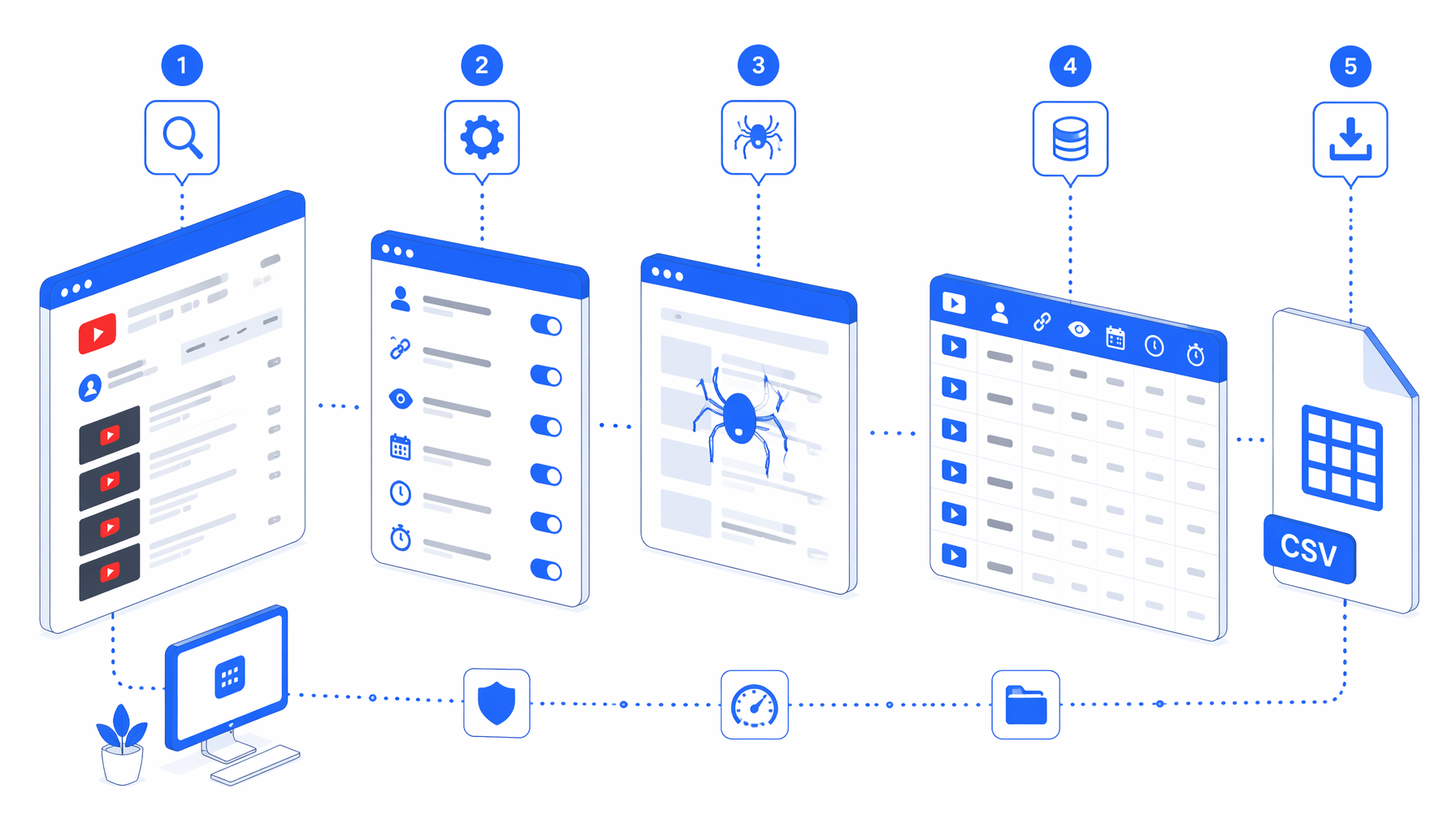
This tutorial shows how to scrape YouTube channel video metadata into CSV with the YouTube Channel Scraper template for UScraper. You will import the workflow, replace sample watch URLs, set the export path, run a short test, and validate the exported fields.
Before you start
Prerequisites and scope
You need UScraper installed as a local desktop app, the current YouTube Channel Scraper template, a short list of YouTube watch URLs, and a CSV folder. Start with three to five URLs from one channel or campaign.
This workflow is for video metadata research. It does not download videos, collect private account data, bypass paid content, scrape comments, or guarantee a complete archive. If you need every upload, first build the watch URL list, then enrich those URLs.
Technical access is not permission. Review YouTube policy, avoid bypassing login or verification, keep collection modest, and use approved API access for sanctioned production data.
API context
YouTube channel scraper vs API
The official YouTube Data API is the structured route for applications. A common API flow is to request channel metadata with channels.list, include contentDetails, read the uploads playlist ID from the channel implementation guide, then page through upload entries with playlistItems.list.
That path fits official schemas, quotas, backend integration, and policy-approved application behavior. It also means project setup, credentials, pagination, and schema mapping.
UScraper is different. It is a YouTube Data API alternative for supervised CSV work: provide known watch URLs, review the browser session, and export metadata an analyst would otherwise copy by hand.
| Approach | Best fit | Trade-off |
|---|---|---|
| UScraper template | No-code CSV export from known watch URLs | Depends on page rendering, selectors, and YouTube response behavior. |
| YouTube Data API | Sanctioned apps, official IDs, quotas, and backend workflows | Requires API setup, keys, pagination, and endpoint-specific fields. |
| Hosted scraper tools | Cloud scheduling, managed workers, and high-volume infrastructure | Targets and outputs usually pass through a vendor runtime. |
Workflow anatomy
What the YouTube channel scraper JSON does
The bundled JSON export is the authoritative workflow definition. Its graph follows:
Navigate -> Wait for Page Load -> Wait for Element
-> Sleep -> Structured Export -> Loop Continue
Navigate owns the watch URL list. The wait blocks give the YouTube watch container time to appear. Sleep allows late metadata to settle. Structured Export writes the row, and Loop Continue advances to the next URL in append mode.
| CSV column | What it captures | Validation check |
|---|---|---|
title | Video title from page metadata, headings, or document title fallback | Compare against the visible watch page title. |
author | Channel or author name from the watch metadata area | Check the channel name under the video. |
url | Clean watch URL with extra query parameters removed | Dedupe by this field. |
publish_time | Relative age, absolute date, or streamed/premiered label | Expect locale and video-type differences. |
view_count | Visible view count text | Treat hidden or delayed counts as optional. |
length | Duration from player metadata, page metadata, or visible player time | Spot-check short videos and livestreams. |
account | Channel handle or account identifier parsed from the channel URL | Compare with the channel link. |
There is no bundled CSV sample, so use the table above plus the JSON workflow as the source of truth. The stock filename is youtube-channel-scraper.csv.
Runbook
How to scrape YouTube channel videos to CSV
Import the template
Open YouTube Channel Scraper, download the JSON workflow, and import it into UScraper.
Replace the watch URLs
In Navigate, replace the sample URLs with approved YouTube watch URLs. Keep standard https://www.youtube.com/watch?v=... links for the first test.
Confirm page waits
Keep the page-load wait, the ytd-watch-flexy element check, and the short sleep before export.
Set the export folder
In Structured Export, confirm youtube-channel-scraper.csv, headers, append mode, and the save location for your project.
Run and inspect
Run one short list, open the CSV, compare rows against the browser, then increase volume only after the output matches your expectations.
Append mode is useful when every input URL should become one row in a single file. For repeat audits, change the filename before each run.
Quality checks
Validate the YouTube video metadata export
Open the CSV beside the browser. Check the first row, one middle row, and the last row. Sort by url to spot duplicates.
| Symptom | Likely cause | Fix |
|---|---|---|
Empty title | The watch page did not render or a prompt blocked it | Resolve prompts, rerun one URL, and confirm ytd-watch-flexy appears. |
Blank publish_time | YouTube hid the date, used a different locale label, or loaded metadata late | Extend the wait and treat publish labels as best-effort. |
Missing length | Player metadata was unavailable or the video is a stream format | Spot-check the player and keep duration optional. |
| Repeated rows | The same URL was supplied twice or the export file was reused | Dedupe by url or start a fresh dated CSV. |
Wrong account | Channel link format changed or multiple channel links appeared | Inspect the watch page and update the account selector if needed. |
Do not skip this step. The best YouTube scraper tool for analysis is the one whose rows you can explain later. Save the source URL list, run date, CSV filename, and selector edits next to the export.
FAQ
Frequently asked questions
Public YouTube pages can still be governed by YouTube terms, robots directives, copyright, privacy laws, and local rules. Use pages you are allowed to access, avoid bypassing gates, keep runs modest, and get legal review before commercial reuse.
Next step
Download the YouTube channel scraper template
Use this tutorial as the runbook and the template page as the source file. Import YouTube Channel Scraper, run a short watch URL list, validate the CSV, and browse the broader UScraper template library or related blog tutorials for comments, transcripts, search results, or channel page exports.