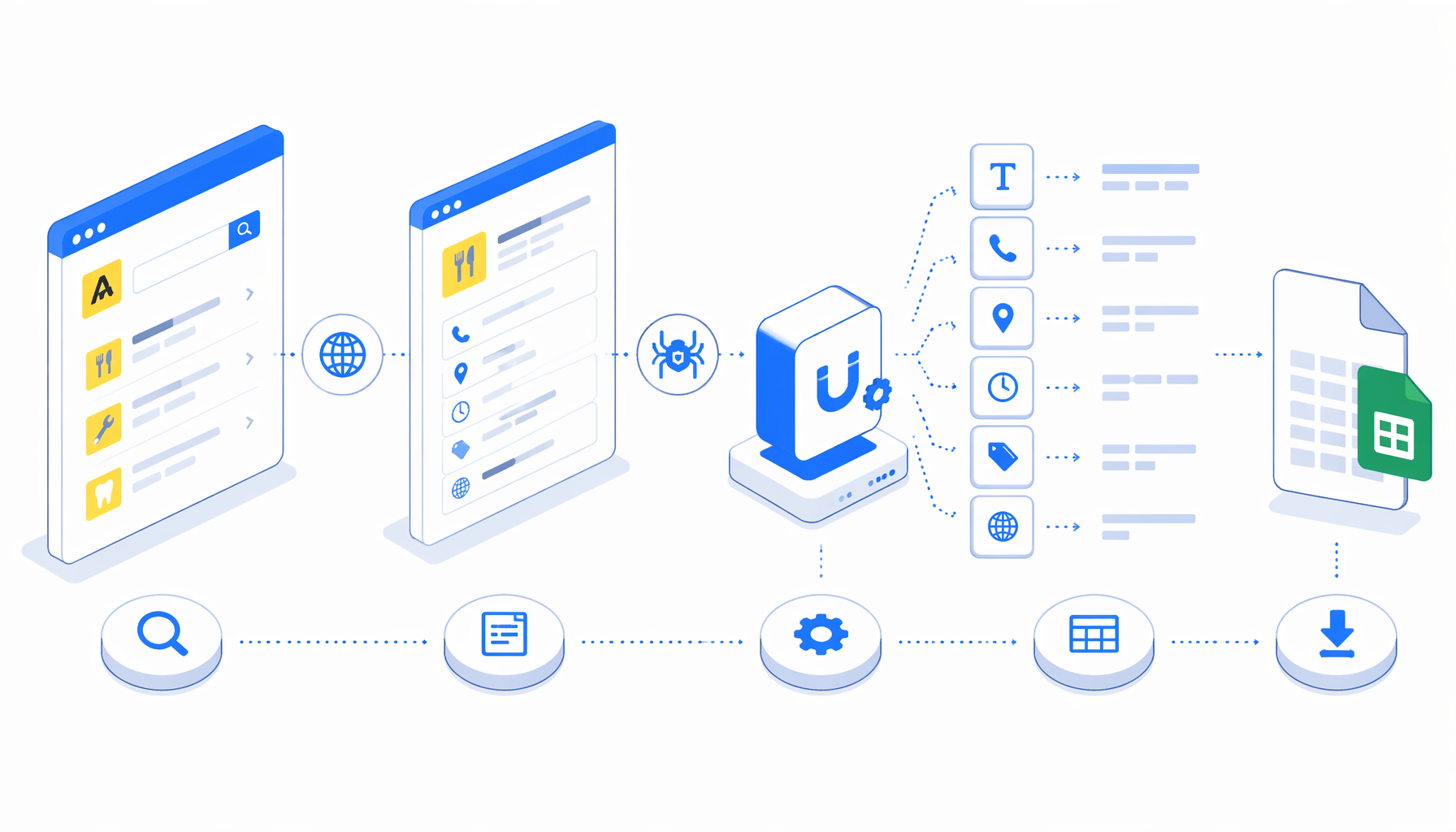
This tutorial shows how to scrape Paginas Amarillas business details from approved detail-page URLs into CSV with the Paginas Amarillas Spain product-details template for UScraper. You will import the workflow, add source URLs, set the export path, run a small validation batch, and fix the common issues that show up in directory scraping.
Before you start
Prerequisites and scope
You need UScraper installed, the Paginas Amarillas scraper template imported, a folder for CSV exports, and a short list of business detail URLs you are allowed to process. Start with three to five URLs. A small first run makes it obvious whether names, phones, addresses, hours, and websites are rendering correctly before you add more pages.
This article covers product-detail style pages, not a broad site crawler. The bundled JSON uses a known URL list in the Navigate block, then loops through each page. If you need source URLs first, build them from a manual shortlist, an approved internal list, the official Paginas Amarillas home page, or directory entry points such as the activity index.
The right first run is not "all of Spain". It is five approved URLs, one CSV, and a field-by-field check against the browser.
Review the source site's current terms, robots.txt, privacy duties, and outreach rules before collecting or reusing contact data. Public visibility does not automatically mean unrestricted automated use.
Workflow shape
How the Paginas Amarillas scraper works
The template is intentionally compact: Navigate -> Wait for Page Load -> Wait for Element -> Structured Export -> Loop Continue. Navigate stores the detail URL list. The wait blocks give the page time to render and confirm that an h1 business title exists. Structured Export reads the page and appends the row. Loop Continue moves to the next URL.
The JSON export in the template is the authoritative workflow definition. In practical terms, it says:
{
"input": "known paginasamarillas.es/f/... detail URLs",
"waitFor": ["page load", "h1"],
"outputFile": "paginas-amarillas-detalles-scraper.csv",
"mode": "append",
"columns": [
"nombre",
"pagina_url",
"categoria",
"telefono",
"ubicacion",
"horario",
"informacion_y_servicio",
"actividades",
"descripcion",
"sitio_web",
"hora_actual"
]
}
That shape matters because it avoids guessing through search pagination during the detail export. You decide which business profiles belong in the run, and the scraper focuses on turning those selected pages into consistent CSV rows.
paginas-amarillas-detalles-scraper.csvColumn
nombre
Business name from the page title.
Column
pagina_url
Source detail URL without a hash fragment.
Column
categoria
Visible category or breadcrumb-derived category text.
Column
telefono
Phone number from visible tel links when present.
Column
ubicacion
Address or nearby location block from the profile.
Column
horario
Opening-hours text when the weekly schedule is visible.
Column
sitio_web
External website link exposed by the profile.
Runbook
How to scrape Paginas Amarillas business details to CSV
Import the template
Open the Paginas Amarillas Spain product-details template, download the JSON, and import it into UScraper.
Replace the sample URLs
In Navigate, replace the two sample Madrid detail pages with approved paginasamarillas.es/f/... URLs. Keep one city or category per first batch so validation stays simple.
Confirm the export path
In Structured Export, check the save folder, paginas-amarillas-detalles-scraper.csv, headers, and append mode. Use a new folder for each client, campaign, or test batch.
Run one URL first
Disable the rest of the list or keep only one URL, run the workflow, then compare every exported field against the browser page.
Scale only after QA
Restore the remaining URLs, run the loop, and inspect rows from the beginning, middle, and end of the CSV before importing the file elsewhere.
Validation
Validate names, phones, addresses, and websites
Do not treat the first CSV as final. Directory pages can omit fields, change labels, delay sections, or show different content by location and consent state. The fastest QA method is to keep the source page open beside the spreadsheet and check one row at a time.
| Symptom | Likely cause | Fix |
|---|---|---|
Empty nombre | The page did not reach a visible h1 state | Extend the wait, handle prompts, and rerun one URL. |
Blank telefono | No visible phone link, hidden contact UI, or layout drift | Confirm the phone is visible in the browser and update the selector if needed. |
Weak categoria | Category text moved or breadcrumb markup changed | Compare several pages in the same category and adjust the extraction rule. |
Missing sitio_web | The profile does not expose an external website link | Keep the blank cell and use pagina_url as the traceable source. |
| Duplicate rows | The same URL was supplied twice or a batch was rerun | Deduplicate by pagina_url before CRM import. |
Alternatives
UScraper vs Octoparse, Thunderbit, and Apify
If you are comparing the best Paginas Amarillas scraper for a one-off business-detail export, decide on custody and workflow control first. UScraper is strongest when you want a supervised local desktop workflow, a visible browser session, and a CSV you can validate before it leaves your machine.
Octoparse and Thunderbit are useful when your team already works in their no-code scraping environments. Apify actors are useful when you want cloud execution, APIs, scheduling, or a hosted dataset pipeline. Those trade-offs can be worth it for production automation, but they also change pricing, account setup, and where the data is processed.
| Option | Better fit | Trade-off |
|---|---|---|
| UScraper template | Local CSV, visible QA, detail URLs you already selected | You manage the desktop run and selector maintenance. |
| Octoparse-style template | Teams already using a hosted no-code scraper | Project setup and vendor workflow rules vary. |
| Apify actor | API-driven cloud jobs and scheduled datasets | Data processing and billing follow the actor platform. |
| Custom Python scraper | Engineers who need full control | You own parsing, retries, compliance review, and maintenance. |
FAQ
Paginas Amarillas scraper tutorial FAQ
Public directory pages can still be governed by site terms, robots directives, anti-abuse systems, privacy law, copyright, and outreach rules. Review the current source policies, use modest pacing, avoid bypassing access controls, and collect only fields you have a lawful reason to process.
Next step
Download the Paginas Amarillas product-details scraper
Use the Paginas Amarillas Spain product-details template as the download path and keep this tutorial open for setup and QA. For related workflows, browse the UScraper template library or read more CSV export guides on the UScraper blog.