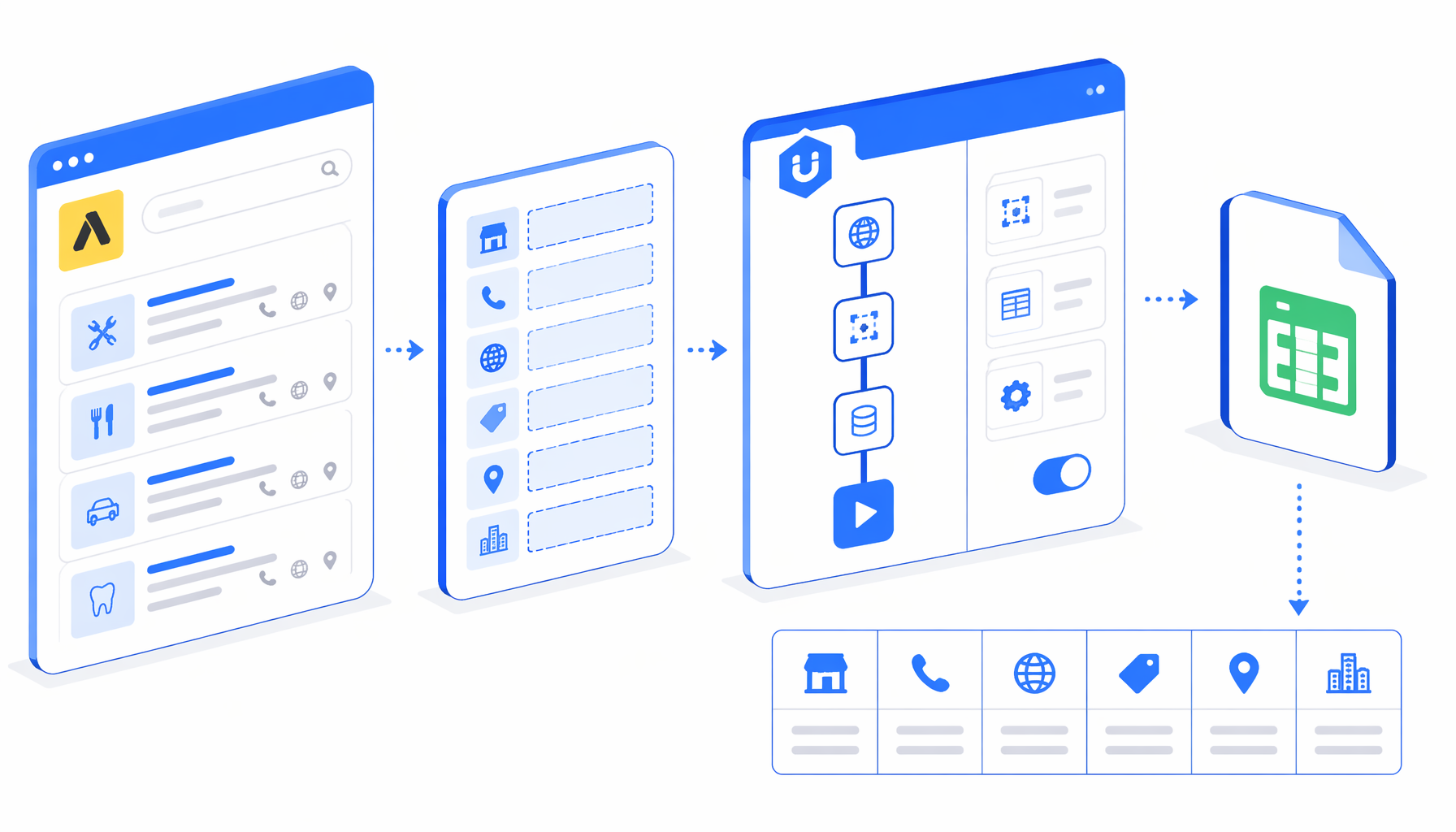
This tutorial shows how to scrape Paginas Amarillas listings from Spain search result pages into CSV with the Paginas Amarillas Scraper for Spain Listings template for UScraper. You will import the workflow, replace the sample URLs, choose an export path, validate rows, and troubleshoot empty exports.
Before you start
Prerequisites, scope, and policy checks
You need UScraper installed as a local desktop app, a Paginas Amarillas search you are allowed to process, and a folder where the CSV can be saved. Start with one query and one location before expanding to more categories, cities, or result pages.
This tutorial covers visible search and listing result pages, not account areas, hidden data, CAPTCHA bypassing, or pages you cannot access in a normal browser session. Before running a batch, review the current source policies, the official robots.txt, and the privacy or marketing rules that apply to your use case.
Compliance is part of the workflow: use pages you have permission to access, keep pacing modest, do not defeat access controls, and document why each exported field is needed.
Workflow anatomy
What the Paginas Amarillas scraper template does
The JSON workflow is intentionally simple: Navigate -> Wait for Page Load -> Inject JavaScript -> Sleep -> Wait for Element -> Structured Export -> Loop Continue. Navigate contains the result page URLs. The JavaScript step handles common consent UI when possible, then marks one unique listing card per business with data-pa-* attributes. Structured Export reads those attributes and appends the CSV row.
The template uses predictable numbered result URLs instead of clicking a next button. The sample bundle includes pages 1 through 10 for one search. If your search has more pages, extend the urls[] list after validating the first run.
| Export column | Meaning |
|---|---|
titulo, url | Business name and unique profile URL. |
horario | Visible opening or closing status when present. |
categoria, descripcion | Category text and listing description fallback. |
telefono, sitio_web | Visible phone value and external website link when present. |
calle, codigo_postal, ciudad | Parsed street, postal code, and city. |
hora_actual | Scrape timestamp for repeated exports. |
Runbook
How to scrape Paginas Amarillas listings to CSV
Import the template
Open Paginas Amarillas Scraper for Spain Listings, download the JSON, and import it into UScraper.
Choose one search
Build a normal PaginasAmarillas.es search. Keep the query, location, filters, and page number visible in the URL.
Replace the Navigate URLs
In Navigate, replace the sample pages with your approved numbered result URLs. Start with page 1 only, then add pages 2 through 10 after validation.
Set the export folder
In Structured Export, keep paginas-amarillas-listados-scraper.csv or rename it for the market. Replace the default save folder.
Run and handle prompts
Run one page. If a cookie notice or verification appears, handle it manually, rerun, and confirm that .uscraper-pa-card rows are found.
Validate, then expand
Compare five exported rows against the browser. When title, URL, phone, address, and city look correct, add the remaining result page URLs and run the batch.
After the first successful run, sort the CSV by url. One business should create one row. If you see stale rows or repeats, clear the CSV or test with a new filename.
Validation
Validate the export before using the data
Treat validation as part of the scraping process. Directory cards vary, and fields such as phone, website, status, and address can be missing or formatted differently across categories.
| Symptom | Likely cause | Fix |
|---|---|---|
| No rows exported | Consent UI, verification, or layout change | Resolve prompts, rerun one URL, and inspect preprocessing. |
| Title is an action label | Selector matched a contact, map, or opinion link | Update the title filter and rerun. |
| Phone is blank | No visible phone or hidden tel: link | Verify the card and consider a detail-page workflow. |
| Website is blank | No external site link on the card | Keep the blank value. |
| City or street is merged | Address order changed | Tune parsing and test several cities. |
| CSV has old rows | Append mode is enabled | Use a new filename or clear the file. |
Alternatives
UScraper vs Octoparse, Apify, and scripts
Octoparse-style templates fit hosted visual scraping. Apify actors fit hosted execution, datasets, API calls, and usage-based scaling. Python or Scrapy scripts give engineers control, but push rendering, pagination, consent handling, and exports into code.
UScraper is a better fit when the job is an analyst-owned CSV: you can inspect the browser, edit the workflow graph, keep the run local, and export to a folder your team controls. The trade-off is validation. If PaginasAmarillas.es changes its markup, the JavaScript preprocessing and export columns may need adjustment.
For neighboring local workflows, browse the UScraper template library. For more tutorials and comparisons, use the UScraper blog.
FAQ
Paginas Amarillas scraper FAQ
Public directory pages can still be governed by site terms, robots directives, anti-abuse systems, privacy law, and marketing rules. Review current policies, avoid bypassing access controls, collect only needed fields, and keep volume modest.
Next step
Download the Paginas Amarillas scraper template
Use the Paginas Amarillas Scraper for Spain Listings template as the download path, then keep this tutorial open while you validate the first CSV. When page 1 checks out, extend the Navigate URL list and run the batch.