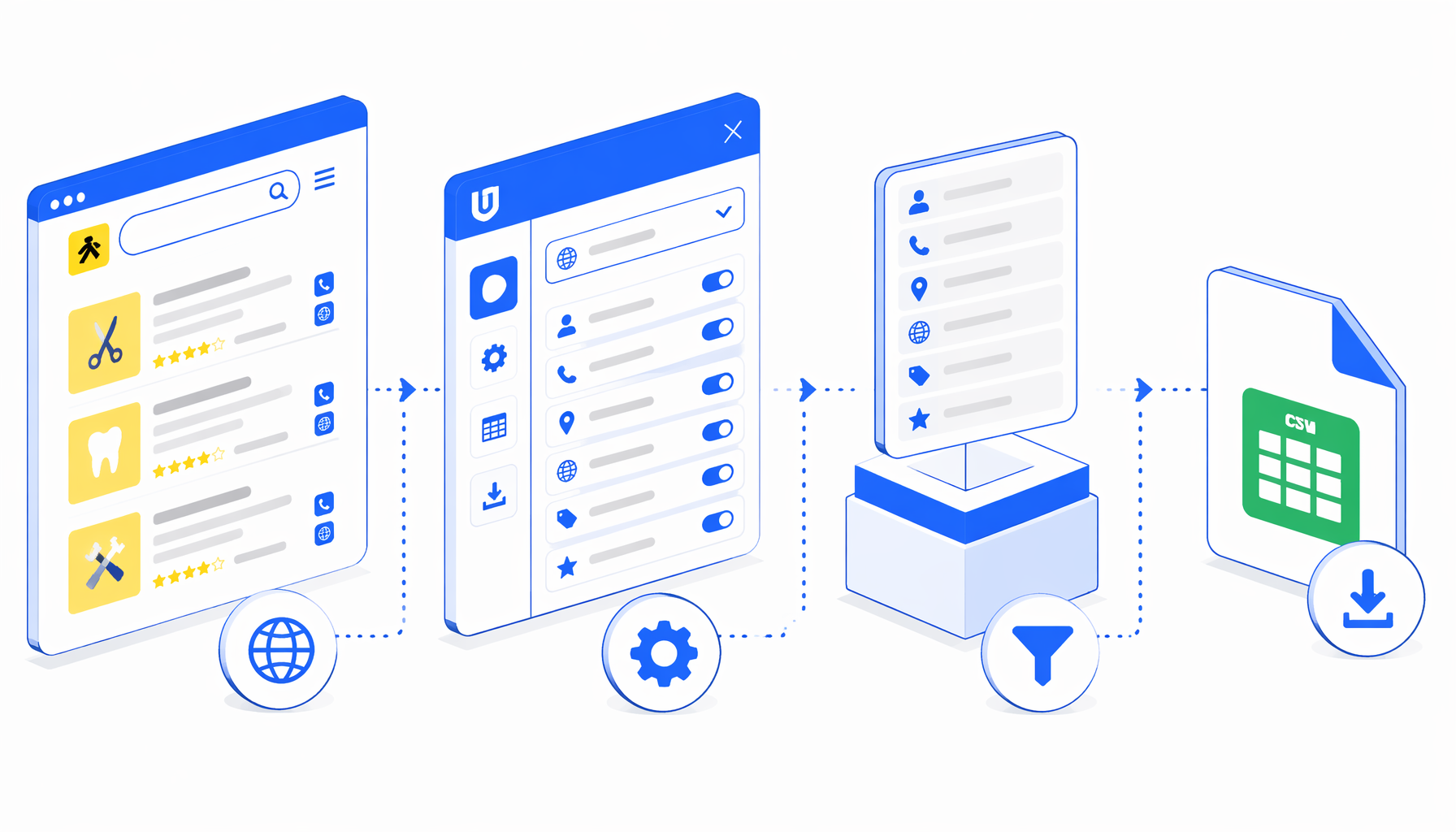
This Yellow Pages scraper tutorial shows how to turn a YellowPages.com search result into a CSV lead list with the Yellow Pages Scraper template for UScraper. You will set the URL, export path, pagination loop, and validation checks.
Before you start
Prerequisites and policy checks
You need UScraper installed as a local desktop app, a YellowPages.com search URL for a category and location you are allowed to review, and a folder where the CSV can be written. Start with one narrow query; broad national searches create noisier rows and harder QA.
This guide covers visible business search result pages. It does not cover account areas, CAPTCHA bypassing, rate-limit evasion, profile-detail crawling, email discovery, or bulk outbound messaging. Review the current YellowPages.com terms, the site's robots.txt, and Google's plain-language robots.txt overview before automation. Technical access is not permission to collect, reuse, resell, enrich, or contact businesses.
Treat this as a supervised research workflow: keep volumes modest, avoid access controls, preserve source URLs, and get legal review before production or outreach use.
Workflow anatomy
What the Yellow Pages scraper template does
The bundled JSON is intentionally simple: Navigate -> Wait for Page Load -> Wait for Element -> Structured Export -> Element Exists -> Click -> Sleep -> Wait for Element -> Structured Export. Navigate contains the search URL. The wait blocks look for .result cards. Structured Export writes the current page into CSV. Element Exists checks for a next-page link and loops when one is available.
The sample workflow starts from:
https://www.yellowpages.com/search?search_terms=restaurants&geo_location_terms=New%20York%2C%20NY
Replace search_terms and geo_location_terms with your approved category and market. Keep the URL specific enough that the output is usable.
| Workflow block | What to check | Why it matters |
|---|---|---|
| Navigate | Search term and location URL | Defines the market and lead category. |
| Wait for Element | .result visible within the timeout | Prevents exporting before listing cards render. |
| Structured Export | File name, folder, headers, append mode | Writes one CSV across all pages. |
| Element Exists | .pagination a.next[href], a.next.ajax-page[href] | Controls whether the loop continues. |
| Click and Sleep | Next-page click and short delay | Gives the next result page time to update. |
Output
What the Yellow Pages CSV includes
There is no bundled CSV sample for this post, so use the export shape as the preview. The workflow captures listing-level fields from search results, not deep profile-page fields. Email, opening hours, secondary phones, and richer descriptions may require a separate detail-page workflow.
| CSV column | Source intent |
|---|---|
business_name | Business name from the result card. |
listing_url | Full YellowPages.com listing URL for audit and dedupe. |
primary_category, all_categories | First category and all visible categories joined into one cell. |
phone | Primary visible phone number from the search result. |
street_address, locality, full_address | Address parts and a combined address field. |
website | Outbound website link when the card exposes one. |
rating_text, rating_class | Visible rating text and supporting rating class. |
years_in_business | Years-in-business label when present. |
description | Short result-card snippet or summary text. |
extra_links | Visible links on the card, joined for manual QA. |
This shape works well for spreadsheet review, local market research, CRM prep, supplier discovery, and lead-list QA. For contractual delivery, freshness guarantees, or stable schemas across many markets, compare a scraper API, licensed data vendor, or approved partner route.
Runbook
How to scrape Yellow Pages leads to CSV
Edit the search URL
In Navigate, replace the sample restaurants and New York query with the YellowPages.com category and city you are allowed to process.
Confirm the export path
In Structured Export, check yellow-pages-scraper.csv, headers, append mode, and the local folder for this project.
Run one page
Run a one-page sample first. Open the CSV beside the browser and compare names, phones, addresses, websites, and categories.
Run the pagination loop
If the first page checks out, let the Next-link branch continue until the template reaches the false branch and ends the workflow.
After the run, sort by listing_url and remove duplicates before enrichment. If you plan outreach, separate scraping QA from compliance review.
Troubleshooting
Common issues when scraping YellowPages.com
| Symptom | Likely cause | Fix |
|---|---|---|
| Empty CSV | The page did not load result cards or the selector changed | Reopen the search URL, check for .result cards, then refresh the selector. |
| Only the first page exported | The next-page selector did not match or pagination ended | Inspect the Next link and update the Element Exists and Click selectors together. |
Blank website cells | Some listings do not show an outbound website link | Treat website as optional and enrich later only when allowed. |
| Duplicated rows | The run restarted with append mode on | Clear the output file or use a new filename before rerunning. |
| Ratings look inconsistent | YellowPages.com may expose rating text and classes differently by listing | Keep rating_text and rating_class, then normalize after export. |
Alternatives
Yellow Pages scraper alternatives and APIs
UScraper is a good fit when you want a local, inspectable CSV workflow without writing Python or maintaining a scraper API. Hosted scraping tools such as Octoparse, Apify, and Web Scraper help with cloud scheduling and managed infrastructure. Python tutorials from providers such as ScrapFly, ScrapeHero, ScrapingBee, Scrapingdog, and Oxylabs fit developers who need code-level control.
| Option | Best fit | Trade-off |
|---|---|---|
| UScraper template | Supervised local CSV export | Validate selectors and policy fit. |
| Hosted no-code tool | Cloud runs and scheduling | Usually usage-based. |
| Python scraper | Custom parsing and retries | Requires code maintenance. |
| Licensed data source | Contractual delivery | Less flexible for ad hoc research. |
If you searched for "best Yellow Pages scraper" or "Yellow Pages scraper alternative," decide on custody and control first. For one-off lead research, UScraper is direct. For data products or resale, approved data access is usually more durable.
FAQ
Yellow Pages scraper FAQ
This tutorial is technical guidance, not legal advice or permission. Review current terms, robots rules, privacy law, marketing law, and contract limits before collection, enrichment, resale, or outreach.
Next step
Download the Yellow Pages scraper template
When ready, download the workflow from Yellow Pages Scraper and keep this guide open for validation. For adjacent workflows, browse the UScraper template library or read more UScraper tutorials.