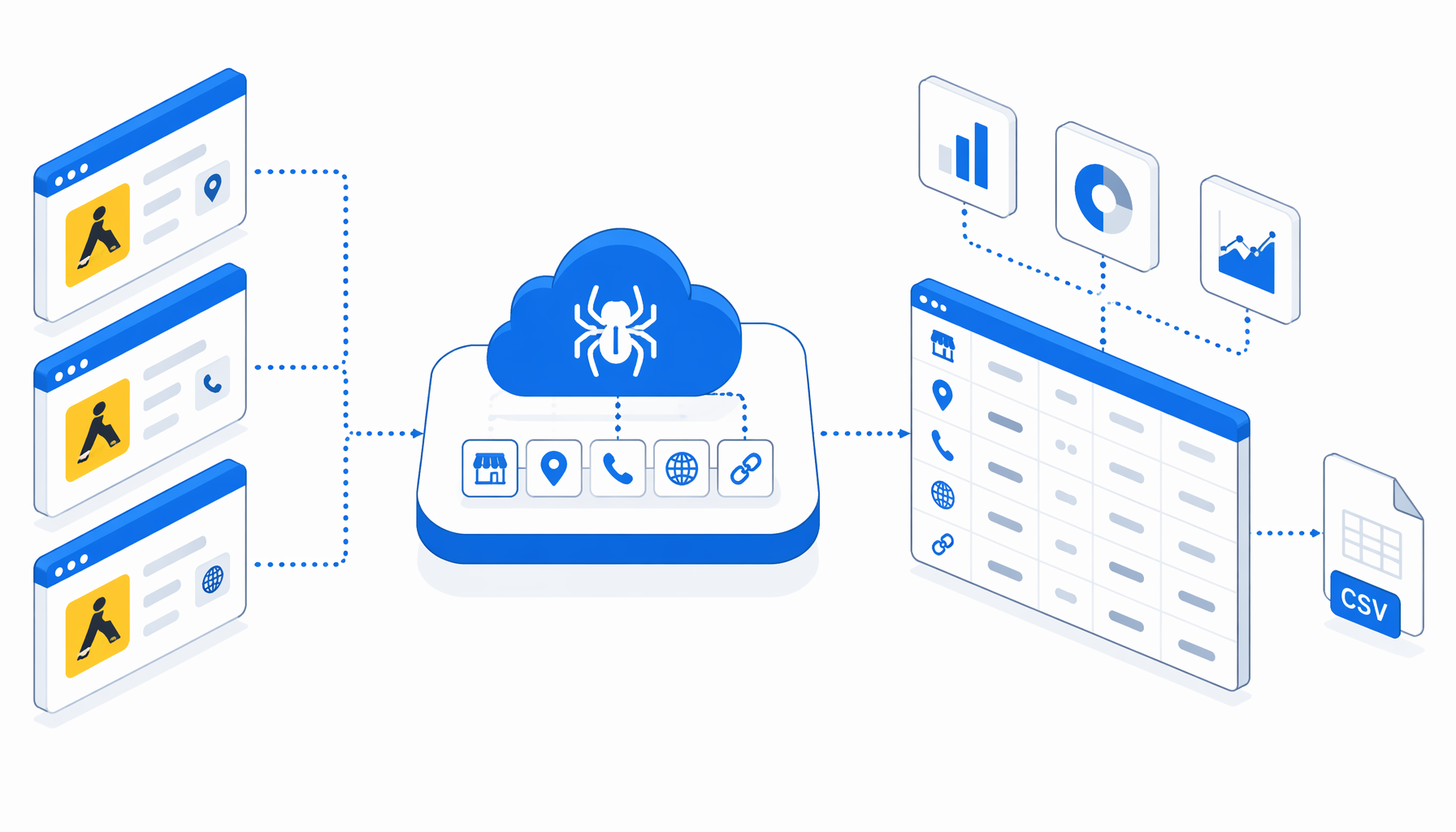
Yellow Pages lead scraping is useful when a team needs a defensible research file, not another pile of browser tabs. The Yellow Pages Scraper for CSV Export template turns visible YellowPages.com search-result cards into a CSV with business title, address, phone, website, listing URL, search name, and location.
Problem
Why Yellow Pages lead scraping breaks in browser tabs
Manual Yellow Pages research usually starts with a simple question: "Who are the battery suppliers in Detroit?" or "Which plumbers show up across these five suburbs?" The first page is easy. By page three, the notes are inconsistent. One person copied the business name and phone. Another pasted only the website. Someone forgot the search term, city, or run date.
That is the practical pain behind searches like how to scrape Yellow Pages, yellow pages lead scraping, and yellow page scraper. The job is rarely "collect every possible record." More often, the job is "turn this specific directory search into rows we can audit."
A lead list is only useful when the team can explain the search that produced it, the fields collected, and the checks performed before anyone acts on it.
Personas
Who uses a Yellow Pages scraper for structured research?
| Persona | Pain | CSV outcome |
|---|---|---|
| Market researchers | Local category coverage is hard to compare city by city when notes live in separate tabs. | Export titles, addresses, phones, websites, listing URLs, search terms, and locations for side-by-side review. |
| Newsrooms | Local business stories need sourceable examples, not screenshots without context. | Preserve listing URLs beside visible business details so editors can verify the source trail. |
| SEO agencies | Local landing pages need real category language, competitor examples, and business-density signals. | Analyze business names, locations, website availability, and directory coverage before writing briefs. |
| Monitoring teams | Supplier, franchise, or competitor lists change slowly and are easy to miss manually. | Re-run the same query and compare new, removed, or changed rows by listing URL. |
| Sales operations | Raw directory data needs cleanup before CRM import or outreach qualification. | Dedupe by URL, enrich websites separately, and route only reviewed rows to the next step. |
Workflow
How the template turns directory pages into rows
The JSON workflow is intentionally plain. It opens a YellowPages.com search URL, waits for the result page, waits for visible business-name links, exports configured columns, checks whether an enabled Next link exists, clicks it when available, waits again, and loops until pagination ends.
Navigate -> Wait for Page Load -> Wait for business rows
-> Structured Export -> check Next -> Click -> Wait -> export again -> End
The default example uses a battery-business search in Detroit, MI. Replace that URL with the category and location your team is allowed to collect. The export block writes yellow-page-scraper-cloud.csv with headers enabled and append mode on, so each paginated result page stacks into the same file.
yellow-page-scraper-cloud.csvColumn
name
Configured search term, such as battery.
Column
location
Configured city or metro, such as Detroit.
Column
title
Business title from the YellowPages.com result card.
Column
address
Street and locality text when visible.
Column
phone
Visible phone number from the result card.
Column
website
Business website link when Yellow Pages exposes one.
Column
url
Full YellowPages.com listing URL for source review and deduping.
Use cases
Concrete Yellow Pages lead scraping workflows
Local market map
Research
A researcher exports electricians across three cities, keeps one CSV per city, and compares business density, website coverage, and address clusters before building a market memo.
Newsroom source index
Reporting
An editor builds a source list for a local-services story, then verifies several listing URLs manually before assigning interviews or citing examples.
SEO content brief
Planning
An SEO team studies business names, service categories, and website availability in a metro before writing local landing pages or competitor notes.
Vendor discovery
Operations
Procurement exports candidate suppliers, removes duplicate listings, checks websites, and sends a reviewed shortlist to the team that owns qualification.
These workflows are deliberately narrower than a full enrichment pipeline. If you need scheduled cloud runs, API delivery, or managed datasets, compare options such as Octoparse's Yellow Page Scraper, Apify's Yellow Pages actor, or Web Scraper marketplace sitemaps. If you need an inspectable local CSV workflow, UScraper is the better fit.
Decision
Yellow Pages scraper cloud vs local desktop workflow
People searching for yellow pages scraper cloud or an Octoparse Yellow Pages alternative are usually comparing execution models. A hosted scraper can be right for teams that need scheduling, cloud storage, APIs, shared dashboards, retries, and vendor-managed infrastructure. A local desktop app is stronger when the operator needs to watch the browser, keep the workflow visible, and write the CSV to a chosen folder.
| Option | Best fit | Main trade-off |
|---|---|---|
| UScraper template | Supervised CSV export for research, monitoring, or qualification. | You own validation and selector maintenance. |
| Hosted no-code scraper | Cloud scheduling and team dashboards. | Data runs through a vendor platform and plan limits matter. |
| Scraper API or actor | Backend jobs, datasets, APIs, and larger recurring workloads. | Usage metering and parser ownership need review. |
| Python script | Engineering-controlled collection and storage. | Requires code, tests, retries, and ongoing maintenance. |
The correct choice depends on the deliverable. A newsroom CSV, a sales-ops source file, and a production lead API should not be evaluated with the same scorecard.
Runbook
A practical research workflow
Choose one narrow search
Pick a category, city, and purpose. Record why the data is being collected and who will review it.
Import the template
Open the Yellow Pages Scraper for CSV Export template, download the JSON, and import it into UScraper.
Edit the search URL
Replace the default search_terms and geo_location_terms values with the approved query.
Run one page first
Check that the first page exports the expected titles, addresses, phones, websites, and listing URLs before turning on the full pagination loop.
Review before reuse
Dedupe by url, spot-check rows against the browser, suppress known records, and document any selector or workflow edits.
For setup details, read the Yellow Pages scraper tutorial. For tool trade-offs, use the Yellow Pages scraper cloud alternatives comparison. The broader template library and UScraper blog cover adjacent directory, search, and contact-detail workflows.
FAQ
Yellow Pages lead scraping FAQ
Yellow Pages lead scraping fits teams that need a documented CSV for local market research, source lists, SEO analysis, vendor discovery, monitoring, or internal qualification. It is not a substitute for legal review, an approved data license, or a production lead vendor.