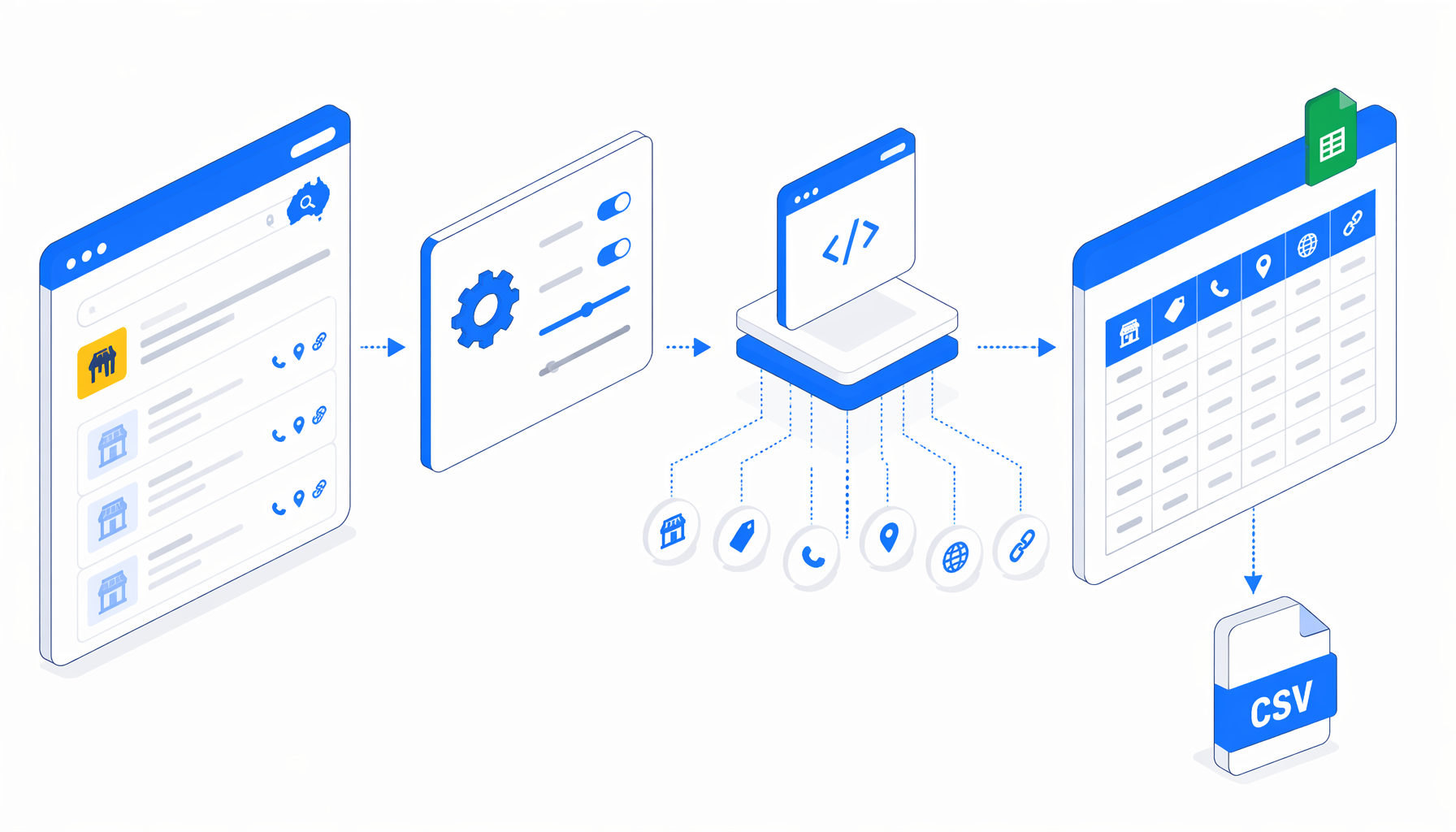
This tutorial shows how to scrape Yellow Pages Australia listing pages into CSV with the Yellow Pages Australia Scraper template for UScraper. You will review prerequisites, import the workflow, set the export path, run a small batch, and validate the rows before using the data.
CSV
12
8 URLs
Included
Local
Before you start
Prerequisites and source checks
You need UScraper installed as a local desktop app, a small list of Yellow Pages Australia detail pages you are allowed to process, and a folder where CSV exports can be written. Start small because directory pages can redirect, change layout, or omit fields such as ratings and websites.
Before automation, open the official Yellow Pages Australia site, review its terms and conditions, check the current robots.txt, and use the contact page for source policy questions. This is a technical workflow, not legal advice.
Compliance first: collect only pages you have permission to access, keep volume modest, do not bypass sign-in walls or verification prompts, and document why each dataset is being collected.
Workflow anatomy
What the Yellow Pages Australia scraper template does
The companion JSON is direct: Navigate -> Wait for Page Load -> Sleep -> Wait for Element -> Inject JavaScript -> Structured Export -> Loop Continue. Navigate owns the URL list, wait blocks let each listing render, JavaScript maps the page to a normalized record, Structured Export writes one row, and Loop Continue advances.
The bundled workflow is based on a sample search for battery around ACT 2914. It uses pre-enumerated listing URLs because live search-result pages can time out and older preview URLs can redirect. The benefit is auditability: every row keeps its source detail page.
| Workflow block | Role in the run | What to check |
|---|---|---|
Navigate | Loops over listing URLs | Replace sample pages with approved URLs for your keyword and location. |
Wait for Page Load and Wait for Element | Prevents early export | Keep waits in place when pages are slow or prompts appear. |
Inject JavaScript | Normalizes fields into one record | Update when the live listing layout changes. |
Structured Export | Appends rows to CSV | Confirm filename, headers, append mode, and save folder. |
Runbook
How to scrape Yellow Pages Australia listings to CSV
Import the template
Open Yellow Pages Australia Scraper, download the JSON, and import it into UScraper.
Review the sample scope
The bundled workflow targets a small battery listing sample near ACT 2914. Read the note on the canvas so you understand why the sample uses detail URLs.
Replace the URL list
Paste your approved Yellow Pages Australia listing URLs into Navigate. Keep batches small until selectors and output quality are confirmed.
Set the export path
In Structured Export, confirm yellow-pages-australia-scraper-product-listing.csv, headers, append mode, and the folder where the file should be saved.
Run and validate
Run one URL, compare the CSV row against the browser, then run the rest of the batch if title, category, phone, website, and source URL look correct.
After the run, sort by detail_page. One configured URL should create one row. Repeats usually mean a duplicated URL or a restarted loop.
Output
What the Yellow Pages Australia CSV includes
yellow-pages-australia-scraper-product-listing.csvColumn
keyword
Search topic preserved with the row, such as battery.
Column
location
Sample location and page context, such as ACT 2914 - Page 2.
Column
title
Business name from the listing.
Column
category
Visible Yellow Pages category.
Column
current_status
Open or closed text when present.
Column
rating
Visible rating text when present.
Column
telephone
Primary phone number from the listing.
Column
website
Outbound business website when available.
Column
detail_page
Source Yellow Pages Australia detail URL.
Sample rows
2 of many
| keyword | location | title | category | current_status | rating | telephone | website | detail_page |
|---|---|---|---|---|---|---|---|---|
| battery | ACT 2914 - Page 2 | The Battery Terminal | Auto Electrician Services | Open until 6:00pm | 5 Stars | (02) 6251 6627 | ||
| battery | ACT 2914 - Page 2 | Bob Jane T-Marts | Tyres | Open until 5:15pm | (02) 6253 4256 |
The full export also includes rating_count, subtitle, and address. Keep blank values rather than forcing guesses; a missing website or rating can still be useful when the row keeps the source URL.
| Column group | Fields | Why it matters |
|---|---|---|
| Search context | keyword, location | Keeps each business tied to the query and page batch that produced it. |
| Business profile | title, category, subtitle, address | Helps reviewers qualify, group, and dedupe listings. |
| Contact and proof | telephone, website, detail_page | Separates outreach fields from the source URL used for audit checks. |
Validation
Validate the export before using the data
Treat validation as part of the scraper. Keep the browser beside the CSV and verify one row from the start, middle, and end of the batch. For lead research, dedupe by phone, website, and title.
| Symptom | Likely cause | Fix |
|---|---|---|
Empty title | Page did not load or the URL redirected | Open the detail page manually, then rerun that URL. |
Missing website | Listing has no visible website field | Keep the blank cell and avoid inventing a domain. |
Wrong location | Sample context was not updated | Edit the normalization value before running a new keyword or postcode. |
| Duplicate rows | URL appears twice or loop resumed mid-run | Sort by detail_page, remove duplicates, and reset the input list. |
| Many blank fields | Layout changed or the record map is stale | Refresh the JavaScript block against the live page. |
Guardrails for reliable directory exports
Avoid aggressive unattended batches
Keep waits in place, avoid parallel loops against the same site, and pause when pages slow down or return unusual responses.
Directory data still has usage rules
Review source terms, robots rules, privacy requirements, and marketing rules before using exported phone numbers or addresses.
Listings can move or change shape
Redirects, retired pages, and layout changes are normal maintenance issues for directory data extraction.
Alternatives
How to choose the best Yellow Pages Australia scraper
The best Yellow Pages Australia scraper depends on custody, scale, and maintenance appetite. UScraper fits local CSV exports and visible browser QA. Apify fits hosted runs and APIs. Octoparse fits managed no-code extraction. Open-source scripts fit teams that can maintain parsing, throttling, and retries.
| Option | Best fit | Trade-off |
|---|---|---|
| UScraper template | Local CSV exports, supervised QA, editable workflow blocks | You maintain URL lists and update selectors when pages change. |
| Apify scraper | Cloud jobs, API workflows, scheduled extraction | Data runs through a hosted platform and pricing is usage-based. |
| Octoparse template | Managed no-code extraction setup | Less direct control over local custody and workflow internals. |
| Open-source script | Custom code and full implementation control | Requires developer time for parsing, throttling, and fixes. |
If you are comparing an Octoparse Yellow Pages Australia scraper or hosted actor against this workflow, decide first where the CSV should be produced and who should maintain the scraper.
FAQ
Frequently asked questions
Yellow Pages Australia listings may be publicly visible, but automated collection can still be limited by the site's terms, robots rules, privacy law, database rights, and marketing regulations. Review the current rules, use modest pacing, avoid bypassing access controls, and get legal review before resale, enrichment, or outbound campaigns.
For more workflows, browse the UScraper blog and template library.