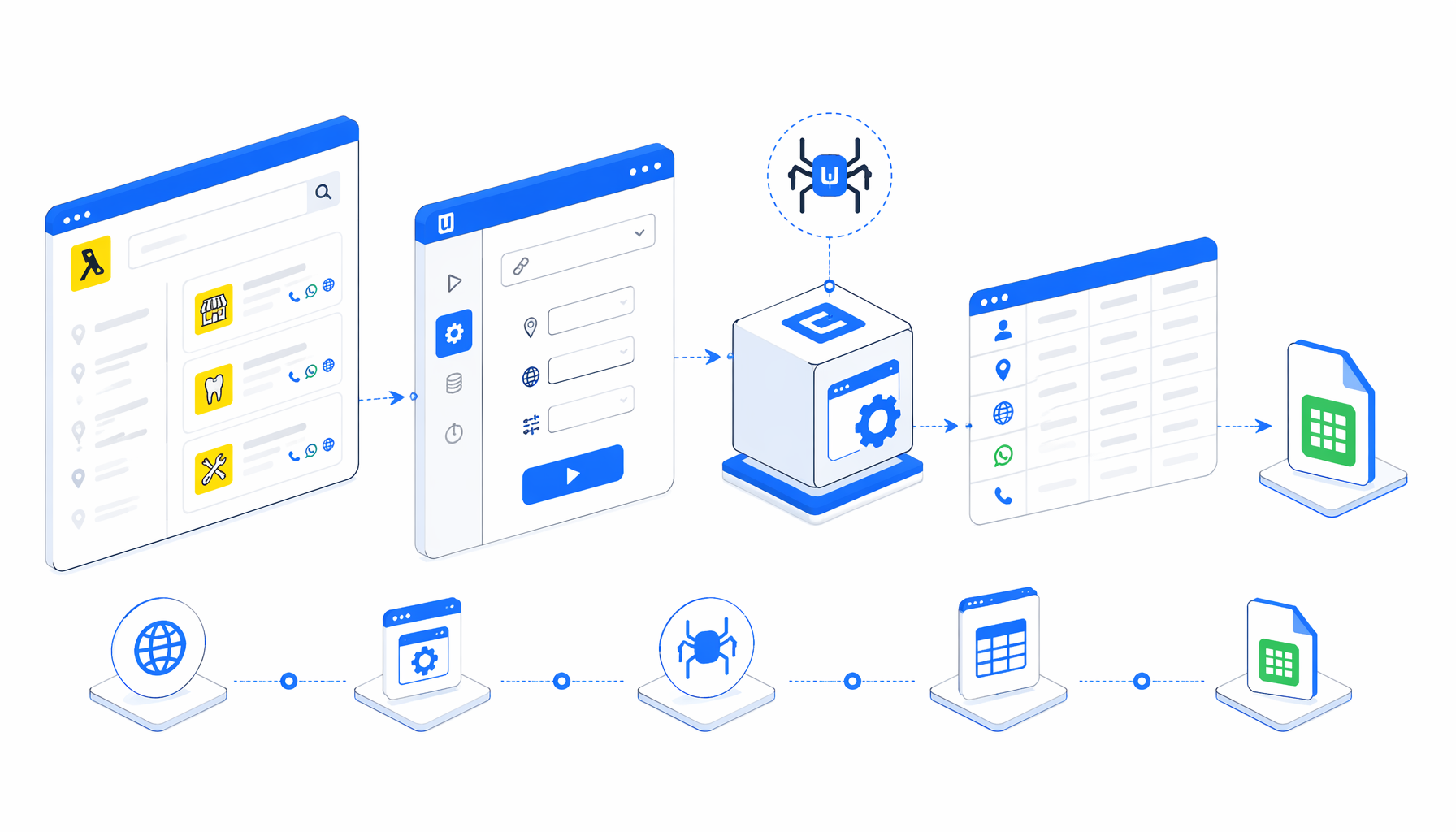
This tutorial shows how to scrape Paginas Amarillas Latin business details into CSV with the Paginas Amarillas Latin product-details template for UScraper. You will import the workflow, adjust the keyword and city, validate the first rows, and fix common issues before scaling.
Before you start
Prerequisites for scraping Paginas Amarillas
You need UScraper installed, the Yellow Pages Latin scraper template imported, and one approved keyword and city pair. The bundled workflow uses Farmacia and Buenos Aires as a narrow test case for pagination, addresses, phone fields, and WhatsApp detection.
Start with the original workflow before editing selectors. If the stock run works, change one thing at a time: keyword, city, output folder. That makes empty CSV troubleshooting much easier.
The right first run is not every LATAM country. It is one keyword, one city, a small CSV, and a browser-side check against the visible result cards.
Review the source site's current terms, robots rules, privacy obligations, and outreach rules before collecting or reusing contact data.
Workflow shape
How the Yellow Pages Latin scraper works
The JSON workflow is the authoritative definition. At a high level, it follows: Navigate -> wait for page load -> accept cookies if present -> wait for detail links -> mark matching rows -> Structured Export -> check next page -> click next -> wait -> repeat.
The important design choice is the row-marking step. The script finds business detail paths, skips utility links, deduplicates by detail path, and marks cards whose name, URL, or card text contains farmac. When you change category, update that filter too.
{
"startUrl": "https://www.paginasamarillas.com.ar/buscar/farmacia/buenos-aires",
"rowSelector": "a[data-uscraper-business-row=\"1\"]",
"fileName": "paginas_amarillas_latin_detalles_scraper_farmacia.csv",
"fileMode": "append",
"pagination": "click enabled Siguiente or next control until none remains"
}
paginas_amarillas_latin_detalles_scraper_farmacia.csvColumn
Sitio_web
Source directory origin.
Column
Palabra_clave
Configured keyword, such as Farmacia.
Column
Ciudad
Configured city, such as Buenos Aires.
Column
Nombre
Business name from the marked detail link.
Column
Pagina_URL
Source origin for review.
Column
Detalles_URL
Business detail path.
Column
Domicilio
Address text from the result card.
Column
Pagina_web
External website when present.
Column
Contacto_WhatsApp
WhatsApp contact when present.
Column
Telefono
Visible phone number.
Runbook
How to scrape Yellow Pages LATAM results to CSV
Import the template
Open the Paginas Amarillas Latin product-details template, download the JSON, and import it into UScraper.
Run the bundled sample
Keep Farmacia and Buenos Aires first. Confirm that detail links render and the CSV includes visible contact fields.
Edit keyword, city, and filter
Replace the Navigate URL, then update the row-marking keyword stem so the scraper keeps the right cards.
Confirm the export path
In Structured Export, check the save folder, file name, headers, and append mode.
Run and validate
Let pagination continue until no next control remains. Spot-check rows from the first, middle, and last page.
Quality checks
Validate Paginas Amarillas business details
The export is useful only if each row can be traced back to the source card. Keep Detalles_URL, Palabra_clave, and Ciudad in the CSV even if your CRM does not need them.
| Symptom | Likely cause | Fix |
|---|---|---|
| Empty CSV | Links did not render, a prompt blocked the page, or the filter matched nothing | Run the bundled sample, confirm visible /fichas/ links, and loosen the filter for one page. |
| Only first page exports | The Siguiente or next selector no longer matches the pagination control | Inspect the next control and update the Element Exists and Click selectors together. |
Missing Domicilio | The card lacks a clear address line or the pattern needs tuning | Compare several cards and adjust the extraction rule. |
Blank Pagina_web | The listing does not show an external website | Keep the blank cell and use Detalles_URL as the traceable source. |
| Duplicate businesses | The same detail path appeared across pages or the CSV was rerun in append mode | Deduplicate by Detalles_URL before importing the file elsewhere. |
Do not hide blank cells during QA. A blank phone or website can be valid, but a blank name or detail URL usually means the selector needs attention.
Alternatives
UScraper vs Octoparse, Apify, and other options
People searching for an Octoparse Paginas Amarillas alternative or an Apify Paginas Amarillas scraper are usually choosing between local CSV work and a hosted scraping platform. UScraper fits visible browser runs, local file custody, and direct workflow edits before the CSV reaches sales, operations, or research teams.
Hosted tools can fit cloud scheduling, APIs, managed datasets, or team execution outside a desktop session. Custom Python can fit strict parsing and deployment needs, but it adds maintenance and policy review.
| Option | Better fit | Trade-off |
|---|---|---|
| UScraper template | Supervised local CSV exports from a keyword and city | You manage the run, validation, and selector edits. |
| Octoparse-style template | Teams already using a no-code scraping workspace | Vendor setup, credits, and execution mode vary. |
| Apify actor | Cloud jobs, APIs, scheduled datasets, and developer pipelines | Data processing, billing, and limits follow the actor platform. |
| Custom scraper | Engineering teams with strict parsing and deployment needs | You own compliance review, retries, blocking, and maintenance. |
FAQ
Paginas Amarillas Latin scraper FAQ
Public business directory pages can still be limited by terms of service, robots rules, privacy law, database rights, anti-abuse systems, and outreach regulations. Review the current source policies, keep volumes modest, avoid restricted pages, and collect only fields you have a lawful reason to process.
Next step
Download the Yellow Pages Latin scraper template
Use the Paginas Amarillas Latin product-details template as the download path and keep this tutorial open while you configure the first run. For adjacent workflows, browse the UScraper template library or read more scraping tutorials on the UScraper blog.