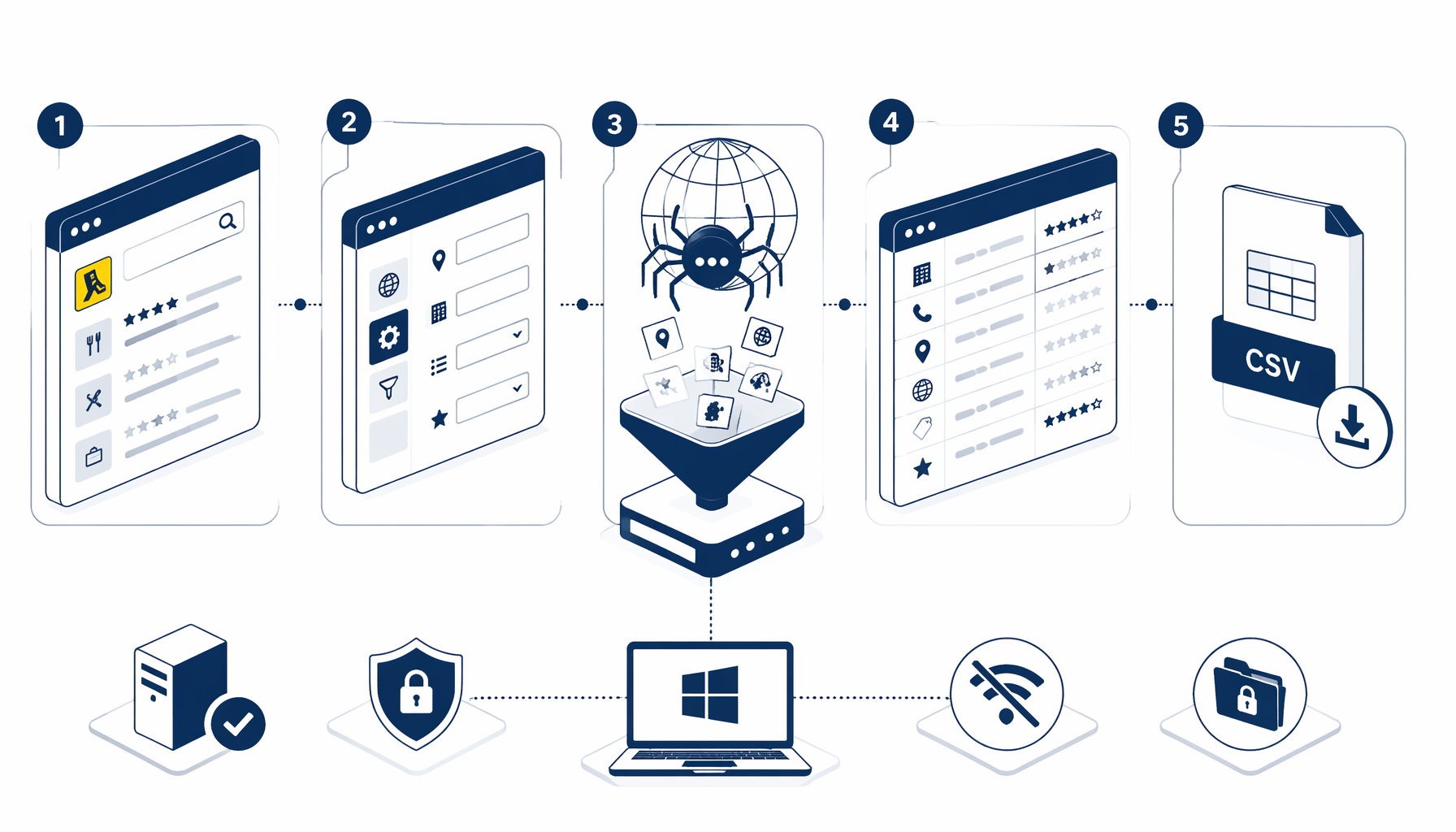
This tutorial walks you through turning Yellow Pages directory rows—business names, phones, addresses, websites, categories, and rating chips—into a CSV you can filter in Excel or load into your CRM stack without standing up a cloud scraping pool first. You will see how Yellow Pages Listing CSV Scraper wires Structured Export, AJAX pagination, and scroll injection so each appended page lands in the same file with predictable columns.
Before you start
Prerequisites, scope, and how this differs from DIY code
You need UScraper on Desktop (Windows 10+ or macOS M1 or later), an approved Yellow Pages URL your team is allowed to automate for the stated purpose, disk headroom for a growing CSV, and willingness to revalidate CSS selectors whenever the directory refreshes markup. Favor the same searches you already run manually—territory scans, category audits, partner discovery—not bulk republication of listings.
Python tutorials (ScrapeHero walks through lxml field passes; Scrapfly covers pagination and bot friction) optimize throughput in notebooks. No-code tools (ParseHub, Octoparse, the Web Scraper extension) trade visual workflows for project files. Yellow Pages Listing CSV Scraper targets analysts who want JSON import, local custody, and Structured Export columns they can diff like infrastructure-as-code.
Pair this guide with the operator’s terms hub—platform policies and robots guidance belong in your compliance checklist, not in marketing copy pretending to be legal advice.
Understand the payload
Export shape summarized from the published workflow JSON
The companion yellow_pages_export.json encodes a looped automation graph, not a one-shot scrape. Structured Export anchors on .srp-listing rows and maps child selectors into spreadsheet columns.
| Column (bundle intent) | Selector hint | Typical capture |
|---|---|---|
| Name | .business-name | Listing title text |
| Phone Number | .phone | Dial string as rendered |
| Address | .adr | Street + locality line |
| Website | .track-visit-website | href outbound link |
| Categories | .categories | Taxonomy chips |
| Tripe Advisor Rating | .ta-count | Adjacent rating snippet |
| Rating | .count | Directory rating count |
Append mode (**fileMode: append**), includeHeaders: true, and a default filename of yellow-pages.csv mean multi-page runs stack beneath a single header row—as long as you do not delete the file between sessions you intend to merge.
Best fit when marketing or sales ops wants lineage—the CSV row should match what the analyst saw in Edge or Chrome seconds earlier.
Strengths track the wedge this site emphasizes: runs locally, no per-row cloud meter, and selector edits inside the same desktop UI that executes the flow.
Honest friction: selectors rot whenever Yellow Pages ships layout experiments; budget short maintenance windows the way you would for any internal macro.
Start from Templates → Yellow Pages Listing CSV Scraper so Navigate, Sleep, and Structured Export blocks arrive pre-wired.
Operational flow
Run the CSV export with confidence
Dry-run a single results page before you unleash pagination—confirm counts, spot-check phones, and ensure Website cells carry the anchors you expect (directories often wrap clicks through track URLs you may need to normalize later). Only then lengthen sleeps and loop Next.
Validation checklist before you scale pages
- Open DevTools on one
.srp-listingand verify.business-name,.phone, and.adrstill nest where the JSON assumes. - Export five rows, compare against on-screen typography, and watch for truncation that hides secondary phones.
- Decide whether raw
hrefvalues are acceptable evidence or whether you must resolve redirects in Python afterward. - Scroll manually once; if ratings load late, keep the Inject JavaScript block that calls
window.scrollTotowarddocument.body.scrollHeightbefore Structured Export. - After a paginated session, deduplicate on Name + Phone or Name + Address—append mode will faithfully capture duplicates if the UI repeats sponsored units.
Download JSON from the template
Open Yellow Pages Listing CSV Scraper and import yellow_pages_export.json into UScraper so blocks, connectors, and baseline selectors appear without manual wiring.
Point Navigate at your approved URL
Replace the sample https://example.com placeholder with the Yellow Pages search URL your compliance story covers—category plus geography, branded query, or partner benchmark.
Tune sleeps to real-world latency
Stretch the shipped sleep durations until cards stabilize on your network; boring waits beat CAPTCHA recovery and keep robots-friendly pacing.
Export page one and audit the CSV
Open yellow-pages.csv, confirm headers, and verify numeric and phone formats before you rely on append for multi-page runs.
Let pagination branch safely
Keep Element Exists watching a.next.ajax-page; when true, run scroll injection, click Next, sleep, and loop back into Structured Export; when false, fall through to End without another click.
Trust & policy
Compliance posture you should not skip
Treat directories like any other networked dataset: read robots.txt, published terms, and your counsel’s interpretation of telemarketing or privacy obligations before you contact exported leads.
Local UScraper vs hosted marketplace scrapers
| Dimension | Yellow Pages Listing CSV Scraper | Typical cloud actor |
|---|---|---|
| Data residency | Stays on your Desktop disk | Processed in vendor regions |
| Cost curve | Desktop license mindset | Usage-based or subscription credits |
| Selector control | You edit blocks directly | Depends on actor configuration |
| Best for | Audits, territory scans, proofs | Always-on pipelines with SLAs |
FAQ
Frequently asked questions
Automating directory pages can conflict with Yellow Pages terms, robots directives, copyright in listing text, telemarketing rules, or local privacy law—even when listings look public. Use low volume, respectful pacing, documented internal purposes, and legal review before commercial redistribution. Running UScraper locally does not replace those obligations. Review the operator terms at yellowpages.com/about/legal before you scale.
Related links and next steps
- Import Yellow Pages Listing CSV Scraper—fastest path from reading to a working pagination loop on your machine.
- Browse Templates for adjacent directory and marketplace exports that reuse Structured Export patterns.
- Return to Blog for comparison pieces and deep dives on selector maintenance.
Stable columns mean you can rerun the flow whenever territories shift—still local, still CSV-first.