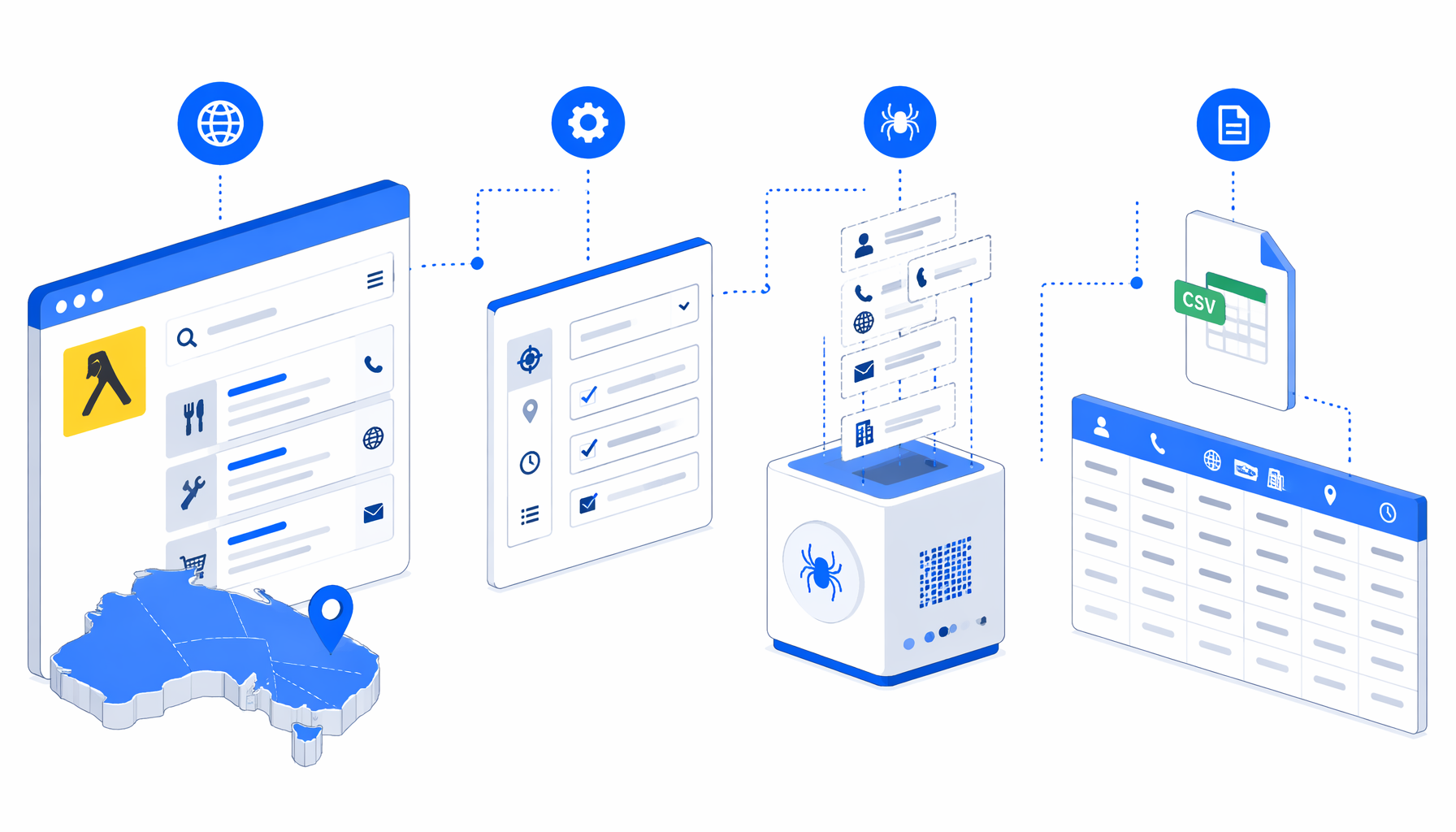
This tutorial shows how to scrape Yellow Pages Australia detail pages into CSV with the Yellow Pages Australia Details Scraper for UScraper. You will prepare source URLs, import the workflow, set the export path, run a small batch, and validate the records.
CSV
16
URLs
Built in
Local
Before you start
Prerequisites for Yellow Pages Australia business data
You need UScraper installed as a local desktop app, a short list of Yellow Pages Australia pages you are allowed to process, and a folder where the CSV export can be saved. This details workflow expects URLs in the Navigate block and appends one row for each page it opens.
Before automation, open the official Yellow Pages Australia site, review the current terms and conditions, check robots.txt, and use the contact page for data-use guidance. This is technical guidance, not legal advice.
Start with a tiny approved batch. If the first two rows are wrong, a larger run only creates more cleanup.
Workflow
How the Yellow Pages Australia details scraper works
The template path is simple: Set Window Size -> Navigate -> Wait for Page Load -> Inject JavaScript -> Sleep -> Wait for Element -> Structured Export -> Loop Continue. Navigate stores the input URLs. Wait blocks let each page render. JavaScript clicks common reveal controls, reads JSON-LD where available, and falls back to visible page text. Structured Export writes the row, then Loop Continue advances.
Use the maintained JSON from the Yellow Pages Australia Details Scraper template. Recreating the blocks manually is slower, and the template page is the download path for the current workflow definition.
| Block | What it does | What to check |
|---|---|---|
Navigate | Opens every URL in the input list | Replace the sample URLs with pages you are permitted to collect. |
Inject JavaScript | Builds a normalized page object | Re-test this block if names, phones, or addresses return blank. |
Structured Export | Appends one CSV row per page | Confirm filename, headers, append mode, and save location. |
Loop Continue | Moves to the next input URL | Make sure it stays at the end of the loop body. |
Runbook
How to scrape Yellow Pages Australia details to CSV
Import the template
Open the Yellow Pages Australia Details Scraper, download the JSON, and import it into UScraper.
Review the sample URLs
The bundled workflow includes two example Yellowpages.com.au listing pages. Run them once before replacing anything so you know the expected CSV shape.
Replace Navigate inputs
Paste your approved detail or listing URLs into the Navigate block. Keep the first production batch small enough to validate manually.
Set the export path
In Structured Export, confirm yellow-pages-australia-scraper-product-details.csv, enable headers, keep append mode, and choose the folder you control.
Run and validate
Run one or two URLs, compare the CSV against the live browser page, then continue the batch when business name, phone, website, address, and source URL are correct.
For the first run, change only the input URLs and export folder. After the output is stable, adjust columns or tune JavaScript fallbacks for a specific category.
Output
What the Yellow Pages Australia CSV includes
yellow-pages-australia-scraper-product-details.csvColumn
Listing_ID
Numeric identifier parsed from the source URL or page metadata.
Column
Business_name
Business name from structured data, the H1, or itemprop markup.
Column
Department
Category, department, or visible service label when present.
Column
Address
Street, locality, region, and postcode merged into one field.
Column
Telephone
Primary phone number from structured data or tel links.
Column
Mailto address or visible email pattern when available.
Column
Website
Outbound business website after filtering directory and social links.
Column
Source_URL
Original Yellowpages.com.au URL for audit and QA.
Sample rows
2 of many
| Listing_ID | Business_name | Department | Address | Telephone | Website | Source_URL | |
|---|---|---|---|---|---|---|---|
| 1000002663303 | Bridgestone Select | Tyres | Mitchell ACT 2911 | (02) 6241 0900 | |||
| 14502099 | Paul Whyte Automotive | Mechanics & Motor Engineers | Gungahlin ACT 2912 | (02) 6242 7033 |
The full export also includes Latitude, Longitude, Opening_hours, ABN, ACN, Number_of_employees, Established, and Also_trade_as. Blank cells are expected when a listing does not publish a field. Do not infer emails, ABNs, or employee counts without documenting another source.
| Field group | Columns | Why it matters |
|---|---|---|
| Identity | Listing_ID, Business_name, Department, Also_trade_as | Helps reviewers dedupe and keep the directory context. |
| Location | Address, Latitude, Longitude | Supports suburb coverage, mapping, and territory review. |
| Contact | Telephone, Email, Website | Gives the fields most teams check before outreach or enrichment. |
| Audit trail | Source_URL | Lets anyone reopen the original listing and verify the row. |
Validation
Validate the Yellow Pages Australia export
Open the CSV beside the browser and inspect one row from the start, middle, and end of the batch. Sort by Source_URL to find duplicate inputs, then by Business_name or Telephone to catch repeated branches. Missing optional fields are fine; missing names, addresses, or source URLs need investigation.
| Symptom | Likely cause | Fix |
|---|---|---|
Empty Business_name | Page did not load, redirected, or changed layout | Open the URL manually, then rerun a single page. |
Missing Website | No visible external website or reveal step changed | Verify in the browser and keep the blank if no site is published. |
Wrong Address | Structured data and visible text disagree | Prefer the value visible on the live detail page for QA. |
| Duplicate rows | Reused URL or restarted append run | Dedupe by Source_URL, then reset the input list. |
| Many blank fields | JavaScript fallback is stale | Refresh the extraction script against the current page markup. |
Guardrails for reliable Yellow Pages Australia scraping
Avoid aggressive unattended batches
Keep waits in place, do not run parallel loops against the same directory, and pause when pages slow down or return unusual responses.
Directory data has usage rules
Review source terms, robots rules, privacy requirements, and marketing rules before using exported contact data.
Pages can change over time
Empty fields usually mean a page moved, a reveal control changed, or the extraction logic needs maintenance.
Alternatives
UScraper, Octoparse, Apify, or a custom script?
If you are comparing the best Yellow Pages Australia scraper options, start with where the data should run and who will maintain it. UScraper fits local CSV workflows with visible browser QA. Octoparse fits hosted no-code extraction. Apify fits API-driven cloud jobs. A custom script fits teams that can maintain selectors, pacing, retries, and compliance checks.
| Option | Best fit | Trade-off |
|---|---|---|
| UScraper details template | Local CSV export, supervised QA, editable workflow blocks | You maintain URL lists and update extraction logic if the site changes. |
| Octoparse alternative | Managed no-code scraper templates | Less direct control over local custody and workflow internals. |
| Apify actor | Cloud automation, API access, scheduled jobs | Runs through a hosted platform with usage-based operations. |
| Custom script | Full implementation control | Requires developer time for parsing, pacing, and fixes. |
For a two-step workflow, collect candidate source pages with the Yellow Pages Australia listing scraper, then pass qualified URLs into the details template when you need deeper business data.
FAQ
Frequently asked questions
Yellow Pages Australia pages may be publicly visible, but automated collection can still be limited by the site's terms, robots rules, privacy law, database rights, and marketing regulations. Review the current source rules, keep volume modest, and get legal advice before resale, enrichment, or outreach use.
For more tutorials and workflow ideas, browse the UScraper blog and the template library.