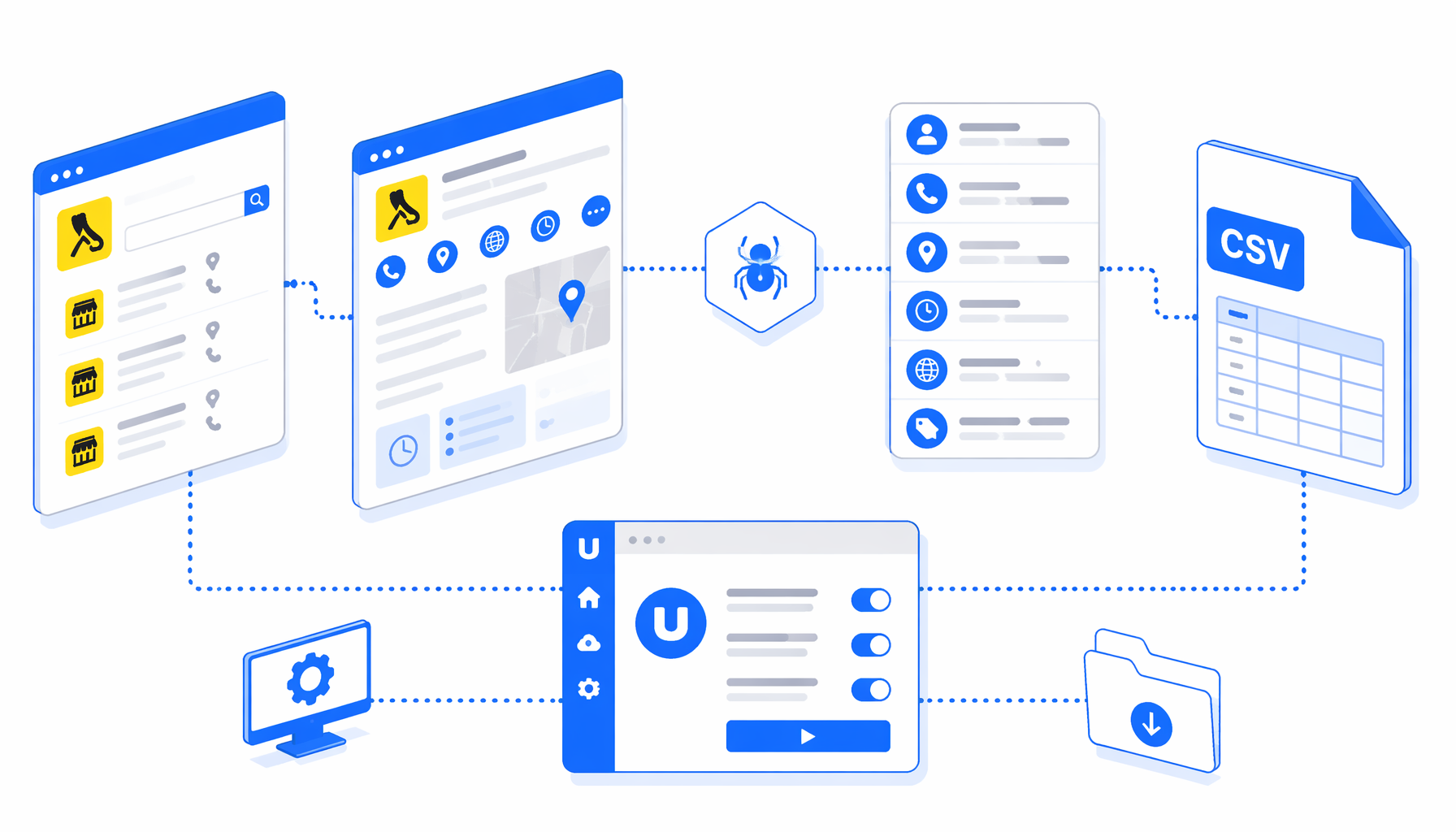
This tutorial shows how to scrape Yellow Pages Canada business detail pages into CSV with the YellowPages.ca Scraper for Product Details CSV template for UScraper. You will import the workflow, replace the sample detail URLs, confirm the export path, run a small batch, and validate the exported business fields before scaling.
Before you start
Prerequisites and source checks
You need UScraper installed as a local desktop app, the free template, a short list of YellowPages.ca business detail URLs, and a folder where the CSV can be written. The bundled workflow starts with two sample URLs; replace them with pages you can open manually and are allowed to process.
Review Yellow Pages Canada's current terms of use and robots.txt before automation. This guide is for supervised exports from visible business pages, not account-only data, CAPTCHA bypassing, private customer information, or resale of a copied directory.
Technical access is not permission. Keep runs modest, respect access controls, document the purpose, and get legal review before commercial use.
Workflow shape
What the Yellow Pages Canada scraper does
The JSON export is the authoritative workflow definition. In plain English, the flow is:
Navigate detail URLs -> wait for page load -> dismiss visible cookie consent
-> short pause -> wait for body -> Structured Export -> Loop Continue
This is a detail-page scraper. The input is a list of known YellowPages.ca /bus/ URLs, not a keyword like plumbers Toronto. If you need candidate URLs first, use a listing workflow, then pass detail URLs into this template.
| Workflow part | What it handles | Why it matters |
|---|---|---|
| URL loop | Visits each supplied business detail page | Keeps the run controlled and auditable. |
| Page waits | Waits for load, consent handling, and visible body content | Reduces blank rows caused by early export. |
| Structured Export | Reads JSON-LD first where possible, then visible page text | Handles common business profile variations. |
| Append CSV | Writes rows into one local CSV file | Makes small batches easy to merge and review. |
Output
Yellow Pages Canada business data fields
The template exports one row per loaded detail page. Some columns support identity and deduplication; others depend on the profile.
| Column group | Fields | Validation check |
|---|---|---|
| Business identity | name, source_url, editor_s_pick | Does the source URL open the same profile named in the row? |
| Contact and location | address, latitude, longitude, phone, website | Are phone and website values visible or present in structured page data? |
| Operating context | rating, current_status, opening_hours | Do blank values reflect missing page content rather than a failed scrape? |
| Profile detail | description, language, products_and_services, brands_carried, specialities | Are long text fields clean enough for CRM notes, QA, or enrichment? |
Because the file mode is append, clear old test files or rename the export before a production run.
Runbook
How to scrape Yellow Pages Canada detail pages to CSV
Import the template
Open YellowPages.ca Scraper for Product Details CSV, download the JSON, and import it.
Replace the sample URLs
In the Navigate block, replace the bundled restaurant pages with your approved YellowPages.ca /bus/ detail URLs. Keep one URL per input item.
Confirm the export path
In Structured Export, check yellow-pages-canada-scraper-product-details.csv, headers, append mode, and the local save folder.
Run a small batch
Start with two to five pages. Watch for redirects, consent prompts, empty sections, or stale business pages.
Validate the rows
Compare name, address, phone, website, hours, services, and source URL against the browser before adding more input URLs.
Scale carefully
Add URLs in batches, keep dated exports, and dedupe by source URL, phone number, and business name.
Troubleshooting
Common issues and fixes
| Symptom | Likely cause | Fix |
|---|---|---|
| Zero rows exported | The page redirected, blocked content, or did not finish rendering before export | Open the URL manually, rerun one page, and extend waits only after confirming access is allowed. |
| Missing phone or website | The business profile does not publish it, or the link is hidden behind a redirect | Keep the row and mark the field as missing rather than inventing a value. |
| Blank hours | Hours are absent, collapsed, category-specific, or rendered in a different layout | Validate a few profiles from the same category before editing selectors. |
| Mixed old and new rows | Append mode reused a previous CSV | Start each final run with a clean file or dated filename. |
| Search results instead of details | A supplied detail URL redirected to a listing or search page | Replace stale URLs and keep source URL validation in the review step. |
Alternatives
UScraper vs Python and hosted Yellow Pages scrapers
Use UScraper for an inspectable local desktop workflow over a finite list of YellowPages.ca detail URLs.
For market context, compare Octoparse's Yellow Pages Canada product details template, Apify actors like Automation Lab's scraper, PhantomBuster's Yellow Pages Business Scraper guide, and GitHub examples like yellowpages.ca-scraper.
For adjacent workflows, browse templates or the blog.
FAQ
Yellow Pages Canada scraper FAQ
YellowPages.ca pages may be visible in a browser, but automated collection can still be restricted by terms, robots directives, privacy law, database rights, and marketing rules. Review the source rules and get legal review before commercial use.
Next step
Download the YellowPages.ca scraper template
Download the JSON from YellowPages.ca Scraper for Product Details CSV, import it, and keep this tutorial open for the first validation pass. After the CSV matches the visible pages, expand the URL list or create a dated copy for recurring research.