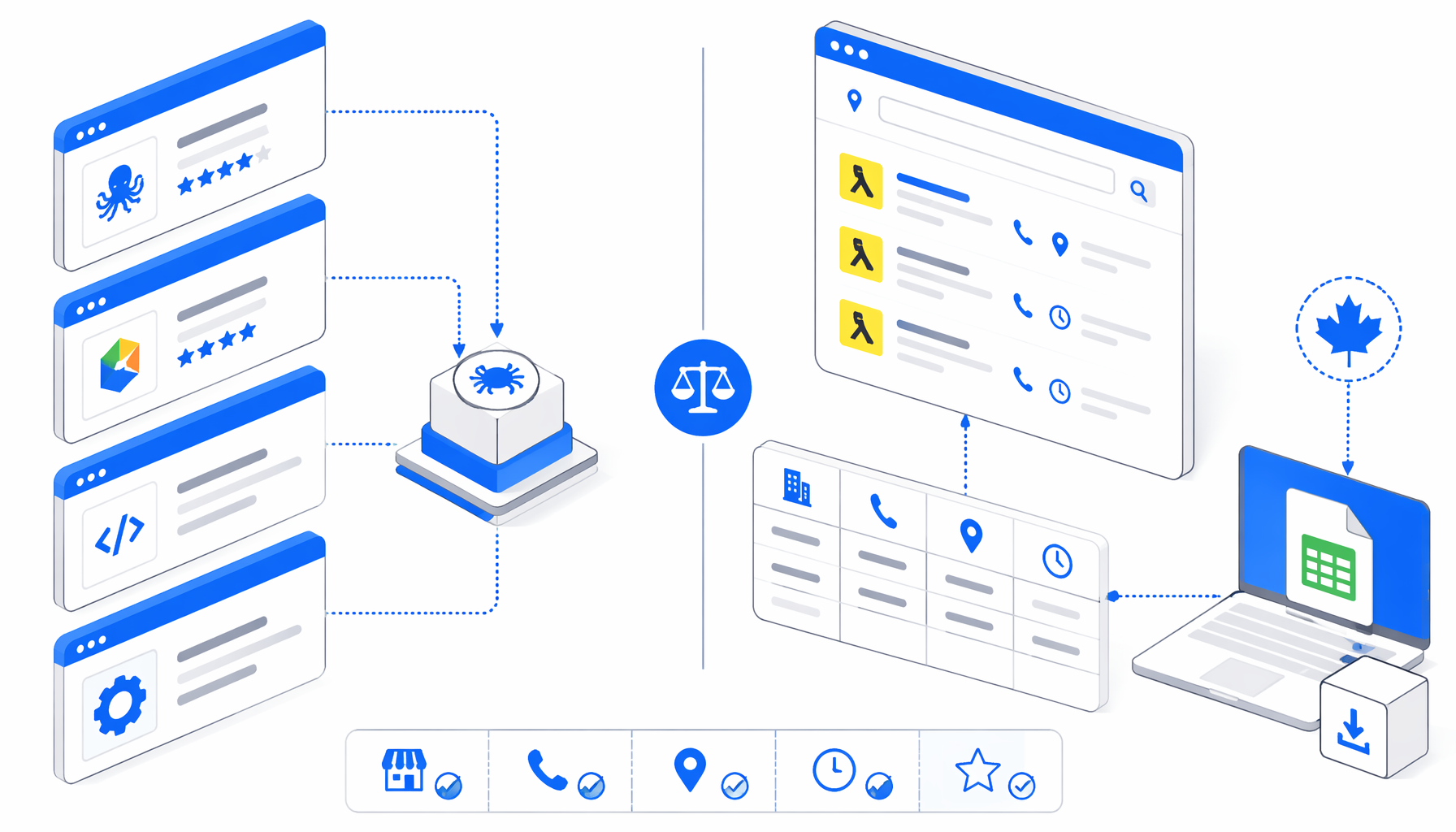
The best YellowPages.ca scraper depends on the job. A sales team exporting verified business profiles, a growth agency collecting city/category leads, and a developer building a scheduled pipeline all need different trade-offs. This comparison looks at Octoparse, Apify, Browse AI, PhantomBuster, GetOdata, scripts, and UScraper's YellowPages.ca Scraper for Product Details CSV.
Comparison frame
YellowPages.ca scraper alternatives compared
Most Yellow Pages scraper alternatives fall into four groups. No-code SaaS tools such as Octoparse, Browse AI, ParseHub, and PhantomBuster help non-engineers configure extraction. Marketplace actors on Apify run in vendor cloud infrastructure and expose datasets or APIs. Hosted data tools such as GetOdata package extraction as a lead-generation workflow. Custom Python, Playwright, Scrapy, or LXML scripts give engineers control, but also maintenance.
UScraper sits in a narrower lane: a visual local desktop app workflow that you can import, inspect, run against a known URL list, and export as CSV. That matters when the deliverable is a spreadsheet, not a permanent cloud crawler.
The right question is not "can this scrape YellowPages.ca?" It is "where does the browser run, who stores the data, what format do we get, and who fixes the workflow when the page changes?"
Side-by-side
Best YellowPages.ca scraper tools by workflow
| Option | Best fit | Hosting | Code needed | Output shape | Pricing shape | Main trade-off |
|---|---|---|---|---|---|---|
| UScraper + YellowPages.ca Product Details template | Known business detail URLs to local CSV | Local desktop app | Low | CSV with detail fields and source URL | Free template; app plan applies for broader use | Best for supervised batches, not always-on cloud crawling |
| Octoparse Yellow Pages Canada templates | No-code users who want listing and detail templates | Vendor platform | Low | Tables, CSV, Excel | SaaS plan and task limits | Convenient hosted workflow, less local custody |
| Apify YellowPages Canada actors | Cloud runs, datasets, API access, and developer handoff | Vendor cloud | Low to medium | Dataset, JSON, CSV, API | Platform usage, actor pricing, compute, or result metering | Strong orchestration, more cloud moving parts |
| Browse AI and PhantomBuster | Sales ops automations and spreadsheet-style inputs | Vendor cloud | Low | Tables, Sheets, CSV, automation outputs | Credits, slots, execution time, or plan limits | Fast for ops teams, less parsing control |
| GetOdata and hosted scraper tools | Packaged YellowPages.ca extraction for lead generation | Vendor cloud | Low | Lead tables, CSV, JSON, or delivered files | Subscription, credit, or tool-specific usage | Simple procurement, vendor controls workflow details |
| Python, LXML, Playwright, Scrapy scripts | Engineering teams owning parsing, retries, tests, and storage | Your infrastructure | High | Whatever you build | Engineering time plus proxy/rendering cost | Maximum control, maximum upkeep |
Searches like best yellowpages.ca scraper, octoparse yellow pages scraper, and apify yellowpages canada scraper mix these lanes together. A fair comparison has to separate hosted pipelines from local CSV workflows.
Where UScraper wins
When UScraper is the better YellowPages.ca scraper alternative
UScraper is strongest when the input is clear: you have YellowPages.ca /bus/ detail URLs and need one row per profile. The companion YellowPages.ca Scraper for Product Details CSV opens each URL, waits for the page, tries to dismiss visible cookie consent, extracts business fields, appends a CSV row, then continues the loop.
The workflow is deliberately readable:
Navigate URL list -> Wait for Page Load -> Cookie consent JavaScript
-> Sleep -> Wait for body -> Structured Export -> Loop Continue
That makes UScraper useful for local SEO agencies, B2B researchers, franchise analysts, vendor discovery teams, and operations teams that need a reviewable Yellow Pages CSV. If a row is blank, the operator can inspect the page, check for redirects, and adjust the flow.
| CSV field group | Examples | Why it matters |
|---|---|---|
| Identity | name, description, source_url | Keeps every row tied to the business profile that produced it |
| Contact | phone, website, address | Supports CRM staging, lead review, and local citation QA |
| Location | latitude, longitude | Helps map prospects, service areas, and regional coverage |
| Business context | opening_hours, current_status, products_and_services | Adds qualification detail before outreach or analysis |
| Profile qualifiers | language, brands_carried, specialities, editor_s_pick | Captures niche fields when the profile publishes them |
Where competitors win
When Octoparse, Apify, Browse AI, or scripts make more sense
Choose Octoparse when your team wants a no-code scraping platform with prebuilt Yellow Pages Canada listing and detail workflows, cloud task management, and table exports.
Choose Apify when the project needs hosted actors, run history, datasets, API access, webhooks, and handoff to engineering.
Choose Browse AI or PhantomBuster when the task belongs inside sales operations: monitoring a page, enriching a spreadsheet, or passing rows into another automation.
Choose custom scripts when your team needs versioned parsing logic, test fixtures, queues, retries, and direct integration. Scripts are powerful, but page changes become your responsibility.
UScraper wins when the goal is a supervised local export from reviewed YellowPages.ca detail URLs.
Hosted actors and scraper APIs win when the job needs remote schedules, queues, datasets, webhooks, and programmatic delivery.
Octoparse and visual SaaS tools are strong for managed no-code workflows. UScraper is stronger when local custody and editable block logic matter more.
Scripts win when developers want to own extraction logic, retries, storage, monitoring, and schema evolution.
Policy
Review YellowPages.ca rules before scraping
YellowPages.ca business pages may be public in a browser, but automated collection can still be limited by the current Yellow Pages Canada terms of use, YellowPages.ca robots.txt, privacy law, database rights, marketing rules, and your downstream use.
Avoid bypassing CAPTCHA, login walls, access controls, rate limits, or technical restrictions. Keep batches modest, preserve source_url for auditability, and get legal review before resale, enrichment, or outbound marketing at scale.
Decision guide
Which YellowPages.ca scraper should you pick?
Pick UScraper when the job is detail-page extraction from a controlled URL list and the output needs to be a local CSV. Pick Octoparse for hosted no-code scraping, Apify for cloud datasets and API delivery, Browse AI or PhantomBuster for sales ops automation, and custom scripts when engineering wants to own selectors, retries, storage, and maintenance.
For the local workflow, start with the YellowPages.ca Scraper for Product Details CSV. For adjacent directory workflows, browse the full UScraper template library, compare related guides on the UScraper blog, or pair detail extraction with a listing scraper when you need to discover candidate business URLs first.
FAQ
The best choice depends on the workflow: hosted actors or scraper APIs for recurring cloud pipelines, no-code SaaS for managed visual scraping, scripts for engineering control, and UScraper for local CSV exports from approved YellowPages.ca detail URLs.
Next step
Try the YellowPages.ca product details template
Import YellowPages.ca Scraper for Product Details CSV into UScraper, replace the two sample Toronto URLs with approved business detail pages, confirm the save folder, and run a small validation batch before scaling your Yellow Pages Canada export.