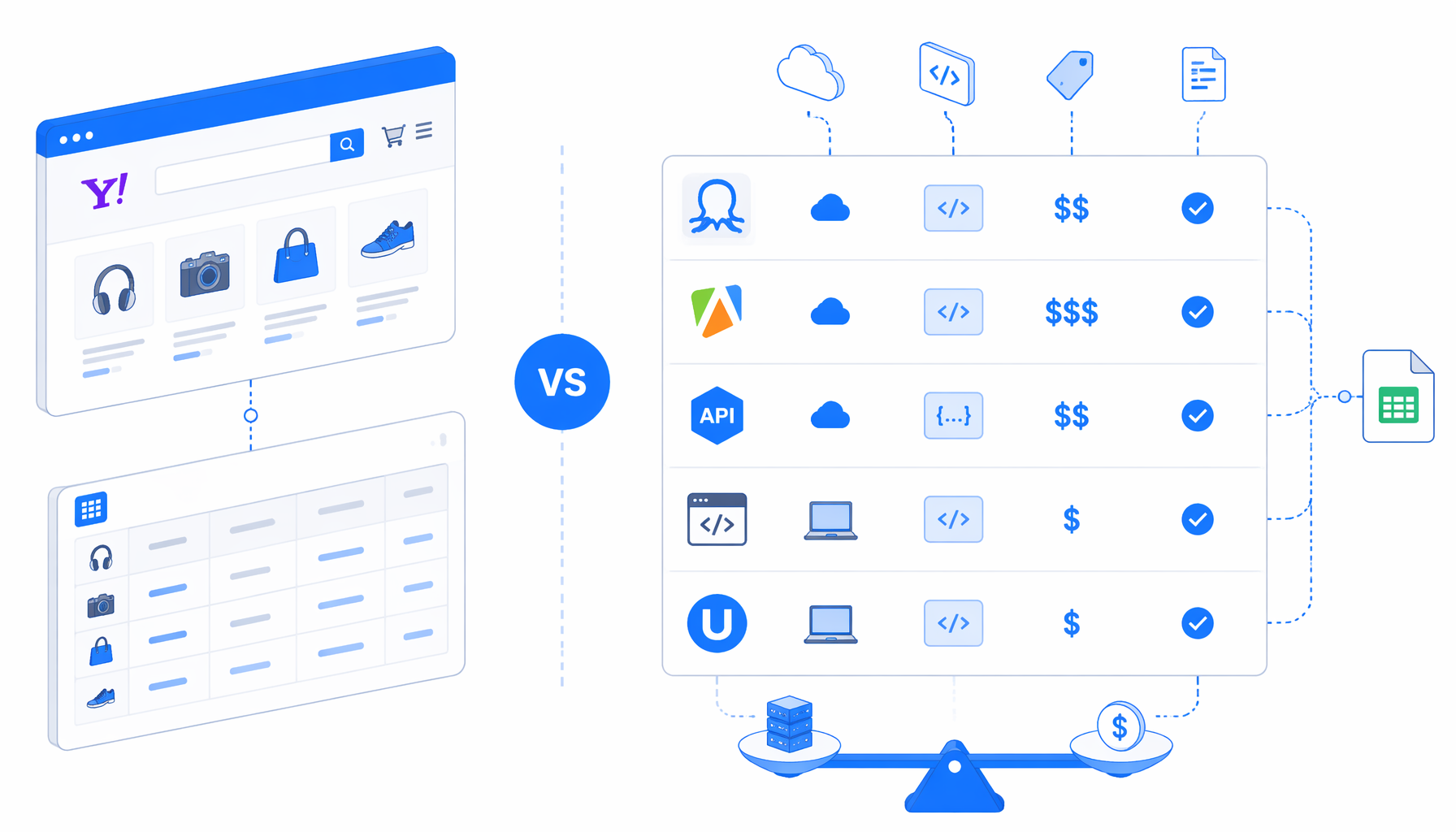
A Yahoo Shopping scraper can mean three very different things: an approved API integration, a hosted scraper that returns JSON, or a visual workflow that exports a CSV from listing URLs. This comparison looks at Octoparse, Apify, hosted scraper APIs, Python scripts, and UScraper's Yahoo Shopping Scraper by URL template for teams comparing cost, control, code, and output.
Comparison frame
What a Yahoo Shopping scraper needs to solve
Yahoo Shopping Japan search pages are useful for price monitoring, seller research, assortment checks, and marketplace analysis. The hard part is not only opening a page. A usable Yahoo Shopping scraper by URL has to wait for lazy-loaded results, preserve pagination context, normalize product rows, and export fields that a spreadsheet user can understand later.
The UScraper template targets listing/search URLs on shopping.yahoo.co.jp and exports columns for 商品名, 店舗URL, 価格, 送料, ポイント, スターランキング, レビュー件数, and 店舗名. Its workflow uses known pagination offsets such as b=1, b=61, and b=121 instead of relying on a dynamic next button that may repeat.
There is also a legitimate API question. Yahoo Japan publishes a Shopping ItemSearch API, and that should be reviewed first when your use case fits an approved API route. Scraping tools make more sense when the required fields, visual context, or workflow shape are not covered by that API.
The practical question is not "can this tool scrape Yahoo Shopping?" It is "where does the browser run, who maintains the extraction, and what does the final row look like?"
Side-by-side
Yahoo Shopping scraper alternatives compared
| Option | Best fit | Hosting | Code needed | Output shape | Pricing shape | Main trade-off |
|---|---|---|---|---|---|---|
| Official Yahoo Shopping API | Approved integrations and apps that can work inside Yahoo's API terms | Yahoo API | Medium | Structured API responses | Developer/API commercial rules | Strong compliance path, but not a visual page scraper |
| Octoparse Yahoo Shopping Scraper by URL | No-code teams that want a ready Yahoo Shopping template | Vendor app/cloud model | Low | Exported product data such as prices and stores | Free tier plus paid SaaS plans | Convenient setup, but cloud limits and plan rules matter |
| Apify Yahoo Shopping actor | Recurring cloud scraping with API access and datasets | Apify cloud | Low to medium | Dataset records, JSON, CSV-style exports | Platform/actor usage pricing | Good for automation, less local custody |
| Bright Data, Spider, or ShopAPIS | Managed product data APIs and higher-volume extraction | Vendor infrastructure | Low to medium | JSON/API delivery or datasets | Usage-based or custom pricing | Strong scale, usually overkill for a small analyst CSV |
| ParseHub or ScrapeStorm-style visual tools | Generic no-code scraping projects across many sites | Vendor app/cloud model | Low | CSV, Excel, JSON, integrations | Tiered SaaS | Flexible, but you still maintain page logic |
| Python scripts and proxy/rendering stacks | Engineers who need custom parsing, queues, tests, and storage | Your infrastructure | High | Whatever you build | Engineering time plus proxy/API cost | Maximum control, maximum maintenance |
| UScraper + Yahoo Shopping Scraper by URL | Local CSV from bounded Yahoo Shopping listing URLs | Local desktop app | Low | CSV with product, store, price, shipping, points, ratings, reviews | Template is free; app licensing applies | Best for inspectable local runs, not fleet-scale cloud crawling |
Where UScraper wins
When UScraper is the better fit
UScraper is strongest when the task is bounded: you already have one or more Yahoo Shopping search/listing URLs, you need a CSV, and the operator should be able to see the extraction flow. The Yahoo Shopping Scraper by URL template opens each configured URL, waits for the page body, scrolls to trigger lazy-loaded listings, injects JavaScript to normalize product rows, waits for normalized rows, then appends them to yahoo_shopping_scraper_url.csv.
That local, visual workflow is useful for teams that do not want a black-box scraper. If the result is empty, the user can inspect the browser, the waits, the JavaScript normalization step, and the Structured Export columns. If the site changes markup, the maintenance work is visible instead of hidden inside a hosted template.
The subscription comparison is also different. Many SaaS and API alternatives price against cloud execution, seats, records, credits, tasks, or usage. UScraper's template itself is free, while app licensing is separate. For periodic CSV jobs, that can be easier to forecast than a metered scraper API. For continuous monitoring at scale, hosted metering may still be the cleaner operational choice.
UScraper wins when the browser run, export file, and workflow edits should stay close to the analyst. The output is a normal CSV, not only an API response in a remote dataset.
Apify, Bright Data, Spider, ShopAPIS, and custom scripts win when the team needs API orchestration, remote scheduling, retries, proxy handling, and large recurring jobs.
Octoparse and similar tools are strong if your team already operates in their SaaS environment. UScraper is stronger when visual setup needs local execution and direct CSV custody.
If Yahoo's official API covers your fields and rights, start there. If you need visible page context from listing URLs, compare scraper workflows carefully.
Output shape
What the UScraper template exports
The JSON workflow definition is the authoritative sample for the template. It describes a bounded multi-URL Yahoo Shopping run, not an infinite crawler. The export is designed to match common Octoparse-equivalent fields while avoiding a click-next loop that can repeat on dynamic pages.
| CSV header | Meaning | Why it matters |
|---|---|---|
| 商品名 | Product name | Identifies the listing being compared |
| 店舗URL | Captured listing or store URL | Lets the analyst trace the row back to the source |
| 価格 | Product price text | Core price monitoring field |
| 送料 | Shipping text | Prevents false comparisons between cheap and paid-shipping offers |
| ポイント | Points or PayPay-style reward text | Captures marketplace incentive context |
| スターランキング | Visible rating | Useful for seller/product quality filters |
| レビュー件数 | Review count | Helps separate proven listings from thin listings |
| 店舗名 | Store name | Supports seller analysis and duplicate review |
Decision guide
Which Yahoo Shopping scraper should you choose?
If the Yahoo Shopping ItemSearch API returns the product fields you need and your intended use fits the policy, that route is easier to defend than scraping rendered pages.
For a wider view of available scrapers, start from the UScraper template library. For more explainers and comparisons, browse the UScraper blog.
FAQ
Yahoo Shopping scraper FAQ
What is the best Yahoo Shopping scraper by URL?
The best choice depends on scale and governance. Use the official API when it covers the data and rights you need, a hosted API or marketplace actor for recurring cloud collection, a script when engineers need full control, and UScraper when analysts need local CSV output from known listing URLs.
How does UScraper compare with Octoparse for Yahoo Shopping scraping?
Octoparse is a no-code SaaS option with Yahoo Shopping templates and cloud-oriented plans. UScraper uses a local desktop app workflow where the user can inspect navigation, waits, JavaScript normalization, and Structured Export columns before writing CSV.
Should I use Apify or a Yahoo Shopping scraper API instead?
Use Apify or a hosted scraper API when you need cloud execution, API delivery, remote datasets, retries, and recurring automation. Use UScraper when the job is narrower: a bounded list of Yahoo Shopping URLs and a spreadsheet-ready CSV.
What fields does the UScraper Yahoo Shopping template export?
It exports 商品名, 店舗URL, 価格, 送料, ポイント, スターランキング, レビュー件数, and 店舗名. In plain English, that is product name, URL, price, shipping, points, rating, review count, and store name.
Is it legal to scrape Yahoo Shopping?
Public visibility does not automatically grant unrestricted reuse rights. Review Yahoo Shopping policies, the Yahoo Developer terms if you use an API, robots directives, copyright and database rules, privacy law, and local compliance requirements. Do not bypass access controls or verification checks.