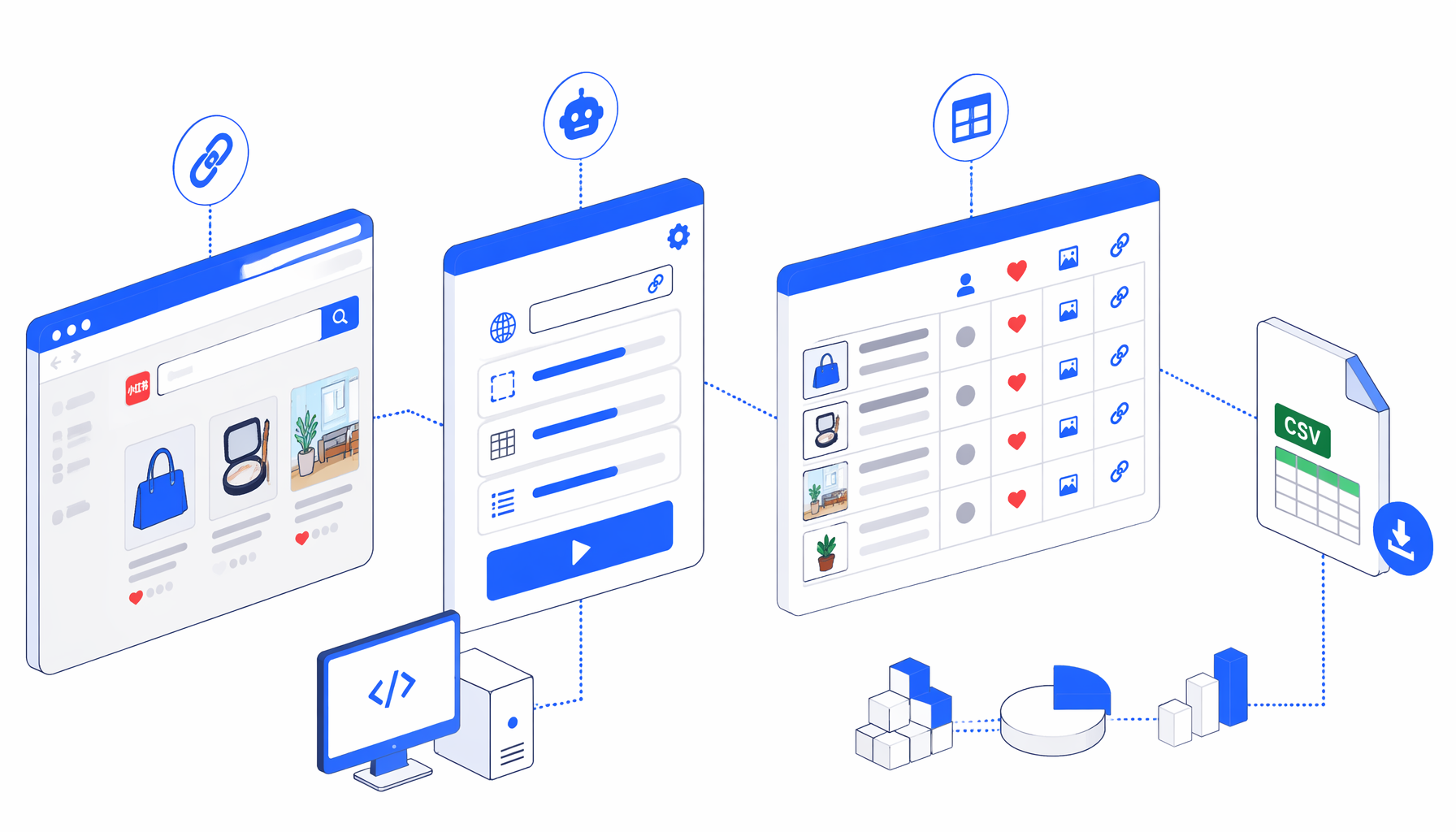
Learn how to scrape Xiaohongshu search results from a saved RedNote search URL into CSV with the Xiaohongshu Search Results Scraper by URL template for UScraper.
Before you start
Prerequisites, scope, and policy checks
You need UScraper as a local desktop app, one Xiaohongshu or RedNote search result URL you can open in a browser, and a folder for CSV exports. Start with one URL, not a keyword list. This URL-based workflow is useful when your team already reviewed a result page manually and wants those visible cards in a spreadsheet.
This tutorial does not cover private messages, account dashboards, hidden APIs, CAPTCHA bypassing, request signing, or login automation. Public pages can still be governed by platform rules, so review the current Xiaohongshu terms of service and robots.txt before automated collection.
Treat this as supervised extraction for approved research. If a page asks for verification, solve it manually in the browser profile or stop the run; do not build around the challenge.
Workflow anatomy
What the Xiaohongshu search results scraper does
The template JSON is the source of truth. Its flow is compact: Navigate -> Wait for Page Load -> Sleep -> Inject JavaScript -> Wait for Element -> Structured Export -> End. Navigate opens a URL such as https://www.xiaohongshu.com/search_result?keyword=web%20scraping. The wait blocks let the web app render. The JavaScript block autoscrolls, deduplicates note cards, and creates hidden .uscraper-xhs-row elements. Structured Export writes those rows to CSV.
| Workflow block | What it does | What to inspect |
|---|---|---|
| Navigate | Opens the configured search URL | Keyword and source parameters. |
| Wait and Sleep | Lets the SPA and prompts settle | Whether cards are visible. |
| Inject JavaScript | Scrolls, extracts, and deduplicates | Whether note links are detected. |
| Wait for Element | Confirms hidden rows exist | Data rows or a diagnostic row. |
| Structured Export | Writes append-mode CSV with headers | Save folder, filename, and columns. |
The export is best effort because Xiaohongshu can withhold or rearrange fields. Empty cells are not automatically failures.
Runbook
How to scrape Xiaohongshu search results by URL
Open the search URL manually
Confirm normal note cards load, then handle any consent, login, language, or verification prompt before automation.
Import the UScraper template
Download the JSON from the related template page and import it into UScraper.
Replace the sample URL
In Navigate, replace the sample keyword URL with your approved search result URL.
Set the export destination
In Structured Export, confirm xiaohongshu-search-results-scraper.csv, headers, append mode, and the folder where your team expects CSV files.
Run one URL and validate
Open the CSV, compare rows against the browser, then repeat the flow for more saved URLs.
Use the sibling Xiaohongshu Search Result Scraper by Keyword when you need keyword entry rather than URL replay.
Output preview
What the Xiaohongshu to CSV export includes
There is no bundled CSV sample, so treat the JSON export as the authoritative workflow sample. The row below is illustrative, not a promise that every card exposes every field.
xiaohongshu-search-results-scraper.csvColumn
input_keywords
Decoded keyword from the search URL.
Column
title
Visible note title, image alt text, or link text.
Column
image_url
Primary card image URL when exposed.
Column
details_page_url
Note detail page URL.
Column
author
Visible creator or account name.
Column
datetime
Visible date or relative time.
Column
author_url
Creator profile URL.
Column
like_count
Visible like count text.
Column
recommended_reason
Recommendation copy or diagnostic reason.
Sample rows
1 of many
| input_keywords | title | image_url | details_page_url | author | datetime | author_url | like_count | recommended_reason |
|---|---|---|---|---|---|---|---|---|
| web scraping | RedNote trend research workflow notes | Market Studio | 2026-06-02 | 865 | Search result card |
Validation
Validate the export before using it
Open the CSV beside the Xiaohongshu page and compare the first few rows manually. Titles should match visible cards. Detail URLs should point to note pages, while author URLs should point to profiles. Like counts may appear as localized shorthand, so normalize them only after review.
| Symptom | Likely cause | Fix |
|---|---|---|
| Only one diagnostic row | Login, CAPTCHA, security verification, expired URL, or invalid token | Open the URL manually, resolve access if permitted, then rerun one URL. |
| Blank author or date | Card markup did not expose those fields | Keep the row and review whether the field is required. |
| Repeated rows | The same card appeared in multiple selector candidates | Use detail URL or image URL to dedupe downstream. |
| Empty image URLs | Images lazy-loaded differently or were hidden | Scroll manually once, then rerun; update selectors if the layout changed. |
| Very low row count | Infinite scroll stopped early or access throttled | Increase dwell time modestly and keep runs paced. |
Guardrails before scaling RedNote exports
Do not automate around verification
Stop or handle prompts manually. The stock workflow is not a bypass system.
Use rows for approved research
Review platform terms, privacy rules, and data-retention policy before sharing exports.
Expect selector maintenance
Card layouts can change, so keep a small validation run in recurring processes.
Alternatives
UScraper vs Octoparse, Apify, APIs, and Python
There is more than one way to scrape Xiaohongshu. Octoparse offers no-code templates, Apify packages scrapers as hosted actors, API providers focus on structured endpoints, and open-source Python projects give engineers full control.
| Option | Best fit | Trade-off |
|---|---|---|
| UScraper | Supervised CSV, visible browser QA, local desktop app workflow | You maintain selectors when the card layout changes. |
| Hosted tools | Scheduling, cloud queues, managed infrastructure | Check pricing, data custody, and exact URL support. |
| Code or API | Backend integration, typed payloads, repeatable services | Authentication state and schema drift become engineering work. |
FAQ
Xiaohongshu search scraper FAQ
Xiaohongshu and RedNote pages can be visible in a browser and still be governed by terms, robots rules, copyright, privacy law, and local compliance requirements. Review current rules, avoid bypassing access controls, and get legal review before commercial use.
Next step
Download the Xiaohongshu search results scraper by URL
When you are ready to run the tutorial, open Xiaohongshu Search Results Scraper by URL, import the JSON into UScraper, and keep this article open for validation. For adjacent workflows, browse all UScraper templates or the UScraper blog for more CSV export tutorials.