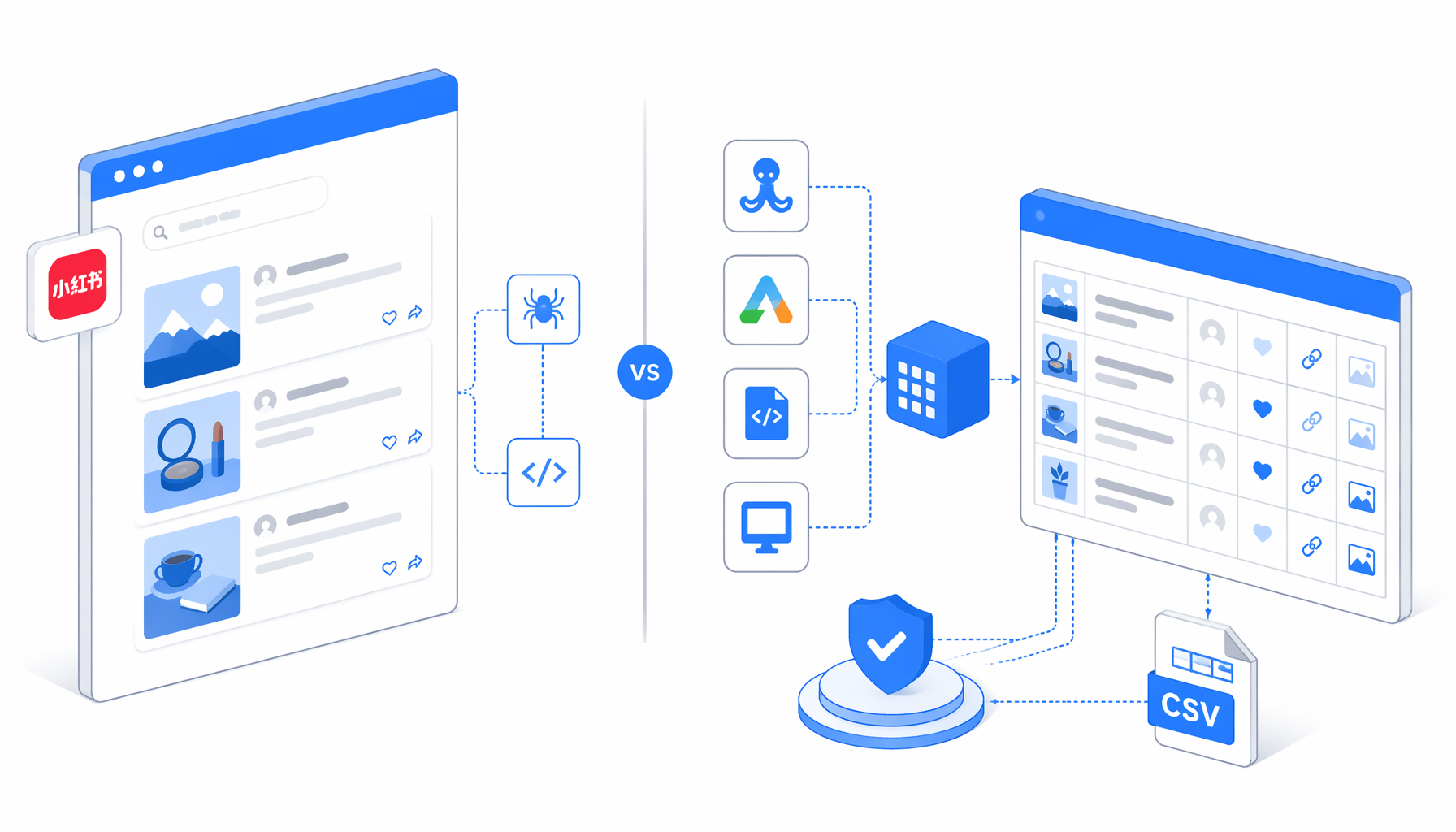
The best Xiaohongshu scraper is not automatically the most expensive cloud actor or the most flexible Python library. For RedNote search research, the practical choice depends on hosting, price meter, code ownership, account friction, and whether the output needs to be a reviewable CSV. This comparison covers Octoparse, Apify actors, Thunderbit-style no-code tools, open-source scripts, and UScraper's Xiaohongshu Search Results Scraper by URL.
Comparison frame
What Xiaohongshu scraper alternatives really differ on
Xiaohongshu, also known as RedNote or Little Red Book, is a search-driven social platform where brands, creators, and shoppers leave short-form posts, product notes, images, and buying signals. A useful Xiaohongshu search scraper must wait for the web app, handle infinite-scroll cards, preserve post URLs, and fail clearly when login, verification, or invalid-token pages interrupt collection.
Most searches for how to scrape Xiaohongshu land in five lanes: no-code SaaS templates such as Octoparse's URL-based Xiaohongshu search results scraper, cloud actors on Apify, AI/no-code browser tools such as Thunderbit, open-source scripts, and local desktop app workflows such as UScraper templates.
The right question is not "which tool can scrape RedNote?" It is "which workflow creates rows your team can explain, maintain, and afford after the first demo?"
Side-by-side
Xiaohongshu scraper alternatives compared
| Option | Best fit | Hosting | Code needed | Output shape | Pricing shape | Main trade-off |
|---|---|---|---|---|---|---|
| Octoparse Xiaohongshu templates | No-code teams that prefer preset hosted flows | Vendor cloud | Low | CSV, Excel, cloud task output | SaaS plan, task, and cloud limits | Quick no-code start; workflow and rows live in the vendor platform |
| Apify RedNote actors | Recurring jobs, API pipelines, datasets, automation | Apify cloud | Low to medium | JSON, CSV, dataset API | Platform usage plus actor pricing or runtime units | Strong cloud infrastructure; costs depend on run shape and actor model |
| Thunderbit Xiaohongshu scraper | Lightweight AI-assisted extraction into sheets | Vendor cloud/browser extension flow | Low | Excel, Sheets, or table output | Credit or subscription model | Fast for ad hoc work; less suited to owned parser logic |
| ParseHub-style visual scrapers | Custom point-and-click extraction projects | Vendor app/cloud | Low to medium | CSV, JSON, integrations | SaaS tiers and speed limits | Flexible visual setup; still needs QA and maintenance |
| Open-source Python scripts | Engineers who need parser control and extensibility | Your environment | High | Whatever you build | Engineer time plus proxy/rendering cost | Maximum control; maximum maintenance burden |
| UScraper + Xiaohongshu URL template | Local CSV from a known RedNote search result URL | Local desktop app | Low | CSV with search-result fields and diagnostic rows | Free template; app licensing applies | Best for supervised local runs, not hands-off cloud scale |
This is not a universal ranking. A data platform that needs thousands of scheduled searches should compare hosted actors, managed APIs, and custom code. A brand analyst checking campaign URLs may care more about a local CSV, visible waits, and predictable workflow edits.
Where UScraper wins
When UScraper is the better Octoparse Xiaohongshu alternative
UScraper is strongest when the job is CSV-first and analyst-led. The companion Xiaohongshu Search Results Scraper by URL template opens a configured search result URL, waits for the single-page app, gives RedNote time to render or redirect, autoscrolls the listing, normalizes detected note cards, and writes rows through Structured Export.
The template is intentionally narrow. It is built around URLs like:
https://www.xiaohongshu.com/search_result?keyword=web%20scraping&source=web_search_result_notes&type=51
That URL-based approach is useful when your team has already reviewed a query in the browser, copied the exact search result page, and wants to export what is visible under the same session context.
xiaohongshu-search-results-scraper.csvColumn
input_keywords
Decoded input keyword.
Column
title
Visible note title.
Column
image_url
Primary card image.
Column
details_page_url
Post detail URL.
Column
author
Creator name.
Column
datetime
Date or relative time.
Column
author_url
Profile URL.
Column
like_count
Visible like count.
Column
recommended_reason
Recommendation or diagnostic text.
Where cloud wins
When Apify, Octoparse, Thunderbit, or scripts make more sense
Choose Apify when engineering needs hosted actors, scheduled runs, API access, datasets, remote logs, and cloud storage. Apify's RedNote marketplace includes actors for search, all-in-one collection, comments, users, posts, and social listening.
Choose Octoparse when operators want hosted no-code templates, cloud task management, and CSV or Excel exports. It is the closest direct comparison because it publishes both URL-based and keyword-based Xiaohongshu search templates.
Choose Thunderbit or similar AI table tools for quick ad hoc extraction into spreadsheets. Choose open-source scripts when developers need full control over signing, cookies, retries, tests, storage, and parsing. That control also means owning authentication problems, anti-bot changes, and selector drift.
Decision guide
Which RedNote search scraper should you pick?
Pick UScraper if your input is a known Xiaohongshu search result URL, the output is CSV, and the operator wants a local desktop app workflow that is easy to inspect. Start with the Xiaohongshu Search Results Scraper by URL, test one query, compare rows against the browser, and only then run more campaign URLs.
Pick Octoparse if your team wants a hosted no-code template and is already comfortable with Octoparse task management. Pick Apify if you need actor APIs, datasets, scheduling, and cloud orchestration. Pick Thunderbit for quick ad hoc spreadsheet extraction. Pick open-source scripts when engineering has time to own authentication, signatures, selector updates, and deployment.
For adjacent workflows, browse the UScraper template library, read more comparison posts in the UScraper blog, or pair this URL-based scraper with a keyword-focused workflow when your research starts from a list of terms instead of saved RedNote search links.
FAQ
Xiaohongshu scraper alternatives FAQ
The best Xiaohongshu scraper depends on scale, hosting, code tolerance, price meter, and output format. Use UScraper for supervised local CSV exports from visible search result cards.