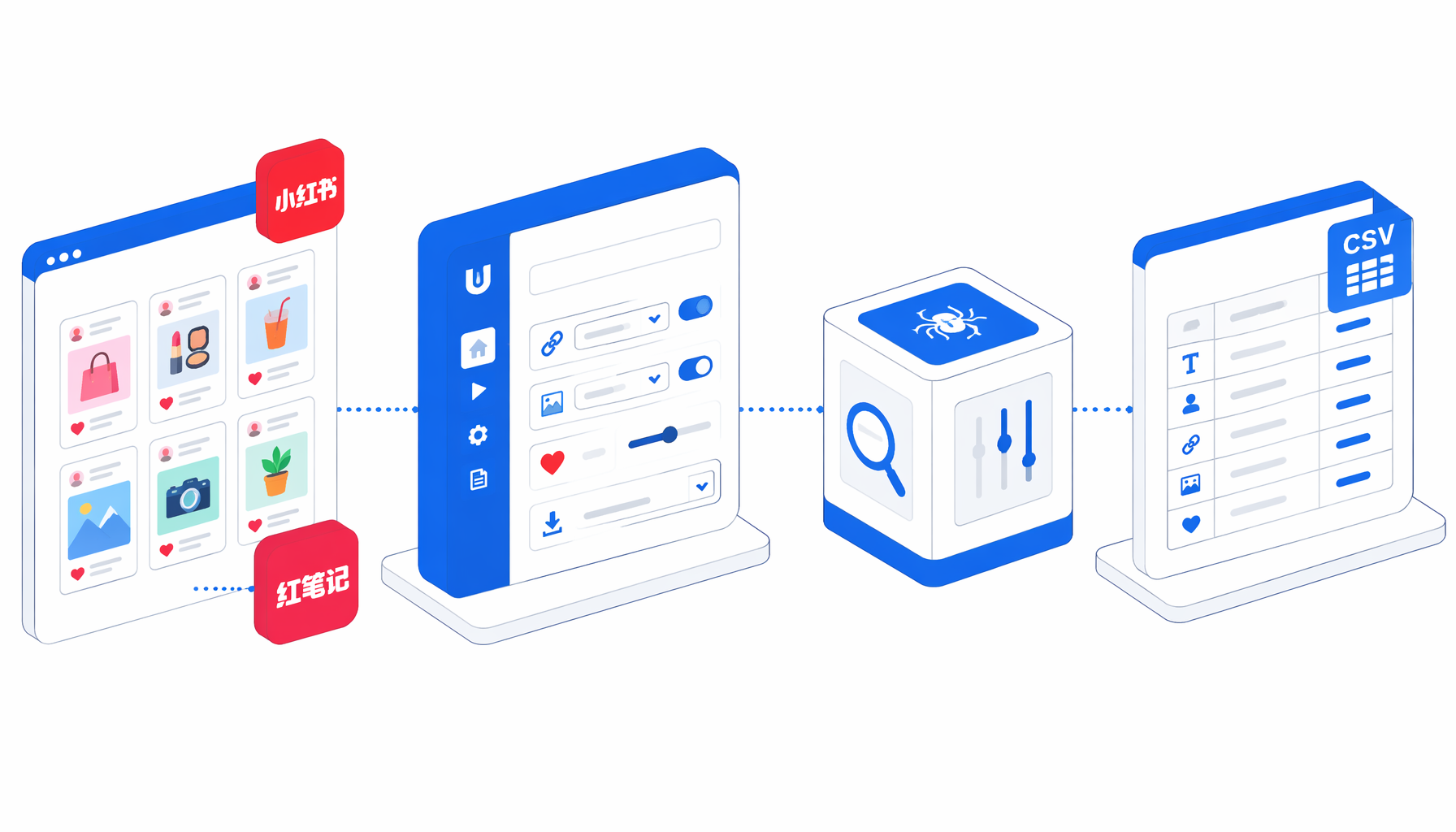
This tutorial shows how to scrape Xiaohongshu and RedNote search results into CSV with the Xiaohongshu Scraper template for UScraper. You will import the workflow, set a search URL, choose an export path, validate one run, and diagnose empty-result cases.
Before you start
Prerequisites, access, and scope
You need UScraper installed as a local desktop app, the current Xiaohongshu Scraper template, a Xiaohongshu search or listing URL you are allowed to process, and a folder for the CSV. Start with one keyword URL before a larger run.
This guide covers visible search and listing cards on Xiaohongshu. It does not cover private accounts, dashboards, messages, commerce flows, CAPTCHA bypassing, or access-control workarounds. Review the current Xiaohongshu user service agreement, privacy policy, and marketing platform when the use case is advertising or partner reporting.
Treat scraping as supervised research. Use permitted pages, keep pacing modest, avoid sensitive personal data, and stop when Xiaohongshu asks for verification.
Workflow anatomy
What the Xiaohongshu scraper template does
The JSON workflow is simple on purpose. It sets a large browser window, navigates to a sample Xiaohongshu search URL, waits for the page body, pauses for the front-end app, closes common overlays, scrolls three times, checks for post-card selectors, and chooses one of two export paths.
If post cards are present, Structured Export writes one row per detected card. If not, the fallback export writes a diagnostic row instead of a silent empty file.
| Workflow stage | What to check | Why it matters |
|---|---|---|
| Navigate | The URL starts from a Xiaohongshu search or listing page | The template is built for feed cards, not every post detail layout. |
| Waits | Page load, visible body, and a short sleep remain in place | Xiaohongshu renders cards after the shell loads. |
| Scroll pass | Three scroll blocks run with pauses | Infinite feeds need time to append additional card elements. |
| Element check | Selectors look for explore links and note-card containers | This chooses normal export or diagnostic export. |
| Structured Export | Save location and file name are set | The CSV lands in a project folder you can audit. |
Normal columns are post_title, post_url, image_url, author_name, author_url, and like_count. Fallback rows add extraction_status and page_text_sample.
Runbook
How to scrape Xiaohongshu posts to CSV
Import the template
Open the Xiaohongshu Scraper template, download the JSON, and import it into UScraper.
Replace the search URL
In Navigate, replace the sample travel query with your Xiaohongshu keyword or listing URL. Keep non-Latin search terms URL-encoded.
Open the page once
Run the browser to the target page and handle visible consent, login, language, or verification prompts before trusting the export.
Set the export path
In Structured Export, change the save location to your project folder and keep the file name xiaohongshu-scraper.csv.
Run one validation pass
Run one URL, open the CSV, spot-check several post URLs against the browser, then repeat with the next keyword or listing.
For the first pass, optimize for trust, not volume. Confirm that titles match the browser, author links resolve, images populate, and like counts look like visible engagement text.
Output
Validate the CSV export
There is no bundled CSV sample for this template, so treat the JSON export shape as authoritative. A healthy result should look like a post-card table, not a profile or comment crawl.
| CSV column | Expected value | Validation check |
|---|---|---|
post_title | First visible title, alt text, or card text | Compare against the card shown in the browser. |
post_url | Absolute Xiaohongshu post URL | Open two or three links to confirm they resolve. |
image_url | Cover image URL from the card | Blanks usually mean lazy loading or blocked media. |
author_name | Visible creator or account name | Check for empty cells when the card layout changes. |
like_count | Visible like or engagement count | Locale and compact notation can change the text pattern. |
extraction_status | Diagnostic text on fallback rows | Read this before rerunning the same URL. |
Fix common Xiaohongshu scraper issues
| Symptom | Likely cause | Fix |
|---|---|---|
| One diagnostic row exports | Login, CAPTCHA, restricted access, or changed layout | Open the page manually, resolve prompts, then rerun one URL. |
post_title is blank | Title text moved or is only present in an image | Update the JavaScript column selector against the live card. |
| Too few rows | Feed did not append enough cards during the finite scroll | Add one scroll-and-sleep pair, then retest with one keyword. |
Alternatives
UScraper vs Python, APIs, and hosted tools
Xiaohongshu scraping has a maintenance cost. Python projects help when engineers need full control over requests, browser state, comments, profiles, or signing research. Hosted platforms such as Apify, Octoparse, Thunderbit, and Bright Data help with cloud execution, APIs, scheduling, or managed scale, but data passes through a vendor system. UScraper fits supervised desktop workflows where the deliverable is a reviewable local CSV.
If you are comparing the best Xiaohongshu scraper, start from the output requirement: use UScraper templates for visible RedNote post cards, code for custom pipelines, and official routes for sanctioned commercial programs.
FAQ
Xiaohongshu scraper FAQ
Public Xiaohongshu pages can still be governed by platform terms, copyright, privacy rules, database rights, and local law. Use permitted pages, do not bypass login or CAPTCHA controls, avoid sensitive personal data, and get legal review for advertising, resale, enrichment, or AI training.
Next step
Download the Xiaohongshu scraper template
Use this tutorial as the runbook and the Xiaohongshu Scraper template as the download path. After you validate one search URL, explore the broader UScraper template library for related social, search, and marketplace exports, or review more tutorials from the UScraper blog.