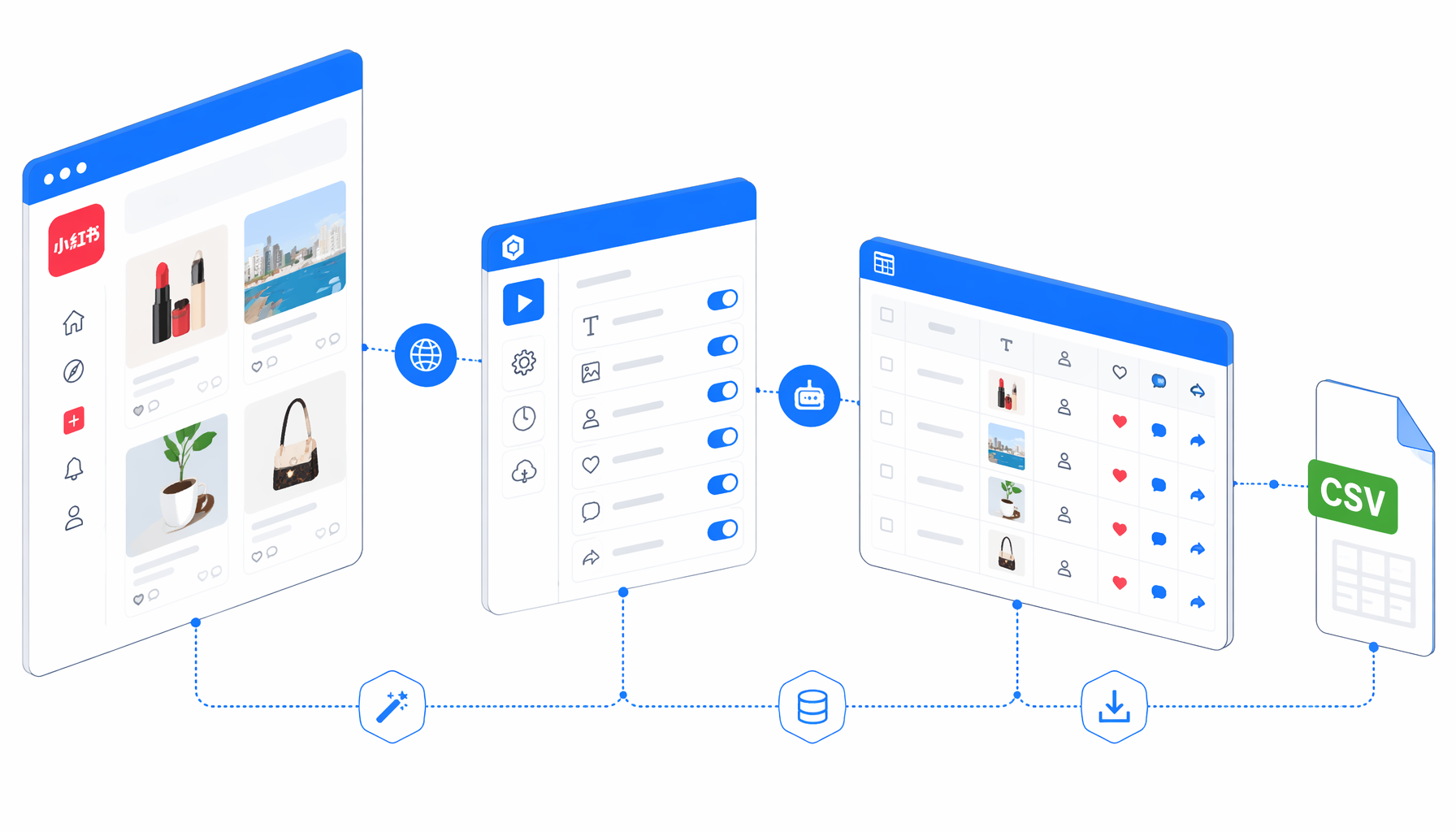
This tutorial shows how to scrape Xiaohongshu post details from RedNote detail URLs into CSV with the Xiaohongshu Post Details Scraper template for UScraper. You will prepare valid post URLs, import the JSON workflow, set the export path, run one page, and validate comments before scaling.
Before you start
Prerequisites and Xiaohongshu policy checks
You need UScraper installed as a local desktop app, current Xiaohongshu or RedNote post detail URLs, and a CSV folder. Start with one URL that opens manually in the same browser session. If it redirects to the explore feed, asks for login, or shows verification, the detail view is not available.
This guide covers public or permissioned post detail pages you can already view. It does not cover private account data, CAPTCHA bypassing, credential capture, or high-volume crawling. Review the current Xiaohongshu terms.
Use the browser as your source of truth. If the current session cannot open the post detail page, the workflow cannot reliably extract comments.
Workflow anatomy
What the Xiaohongshu post scraper template does
The companion JSON is the authoritative workflow definition. Its core path is Set Window Size -> Navigate -> Wait for Page Load -> Sleep -> Wait for Element -> Inject JavaScript -> Sleep -> Wait for Element -> Structured Export -> Loop Continue. Navigate owns the URL list, JavaScript normalizes the live page into .uscraper-xhs-row elements, and Structured Export writes the CSV in append mode.
The template is intentionally best-effort. If the detail page loads, it exports post metadata and comment rows. If it does not, it writes a diagnostic row instead of scraping unrelated /explore feed content.
| Export area | CSV fields | Why it matters |
|---|---|---|
| Post identity | page_url, title, image | Keeps each row tied to the exact detail URL and media set. |
| Author context | user_name, personal_file_link | Helps researchers connect post engagement to the creator profile. |
| Engagement | likes_amount, favorite_amounts, comment_amount | Captures visible counts for lightweight post scoring. |
| Comments | comment_author, comment_author_location, datetime, comment | Turns the visible comment stream into reviewable rows. |
| Replies | comments_replies, comment_like_count, comment_reply_count, replies | Preserves nested discussion where Xiaohongshu exposes it. |
Runbook
How to scrape Xiaohongshu post details to CSV
Import the template
Open Xiaohongshu Post Details Scraper, download the JSON, and import it into UScraper.
Collect current post URLs
Use post detail URLs that open correctly in your browser. Avoid old shared links that depend on expired tokens or redirect to the explore feed.
Replace Navigate URLs
Paste your approved Xiaohongshu post URLs into navigate.urls[]. Keep the multi-URL loop intact so every post appends to the same CSV.
Confirm the export folder
In Structured Export, confirm rednote-post-details-scraper.csv, headers, append mode, and a project-specific save location.
Run one post and inspect rows
Compare the CSV against the browser page. Check title, author, engagement counts, at least two comments, and any diagnostic status before batch runs.
Run the remaining list
Add the rest of your URLs only after the first row checks out. Keep batches modest and preserve the source list.
After the first run, sort by page_url and comment_author. A post with many comments may create multiple rows; a post with no visible comments may create a diagnostic row.
Validation
Validate comments, replies, and diagnostics
Check the CSV against the live page before using it. The template clicks visible "show more" controls, scrolls the comment area, and rebuilds hidden export rows during the wait window, but it does not guarantee every reply on a long thread.
| Symptom | Likely cause | Fix |
|---|---|---|
POST_DETAIL_NOT_LOADED_OR_REDIRECTED | Expired token, unavailable post, login gate, CAPTCHA, or redirect to /explore | Open the URL manually, refresh the post detail URL, then rerun one page. |
| Blank author or title | Detail DOM did not finish rendering or selectors changed | Increase waits and compare the live page structure before updating selectors. |
| Comment count does not match | Xiaohongshu did not load all comments in the visible viewport | Scroll manually, rerun, or treat the export as visible comments only. |
| Replies are missing | Reply controls were collapsed, hidden, or rate-limited | Open the thread in the browser and rerun after expanding visible replies. |
| Duplicate rows | The same URL was supplied twice or append mode reused an old CSV | Clear the CSV or dedupe by page_url, comment_author, datetime, and comment. |
Alternatives
UScraper vs Octoparse, Apify, and Python scripts
UScraper is a strong fit when the job is a supervised local CSV export from known post detail URLs. The workflow is visual, the file lands in your configured folder, and failure states appear as diagnostic rows.
| Option | Best fit | Trade-off |
|---|---|---|
| UScraper template | Local visual QA, CSV exports, known post URLs | Not a managed cloud crawler. |
| Octoparse RedNote template | Teams already using Octoparse templates | Check cloud and subscription fit. |
| Apify XiaoHongShu actor | Cloud actors, datasets, APIs, scheduling | Cloud routing and actor cost apply. |
| Python projects | Custom auth research, signing work, retries, pipelines | Highest maintenance burden. |
For a broader breakdown, read Best Xiaohongshu Scraper Alternatives. For this tutorial, the practical question is narrower: can you open the detail URL, do you need comments in CSV, and do you want the run to happen in a local desktop app?
FAQ
Xiaohongshu post scraper FAQ
Xiaohongshu post pages can be visible in a browser and still be governed by platform terms, copyright, privacy law, database restrictions, and local compliance rules. Review terms, use modest pacing, avoid bypassing access controls, and get legal review for advertising, resale, enrichment, or AI training.
Next step
Download the Xiaohongshu post details scraper
Download the JSON from Xiaohongshu Post Details Scraper and keep this guide open for validation. For related workflows, browse all UScraper templates or the UScraper blog.