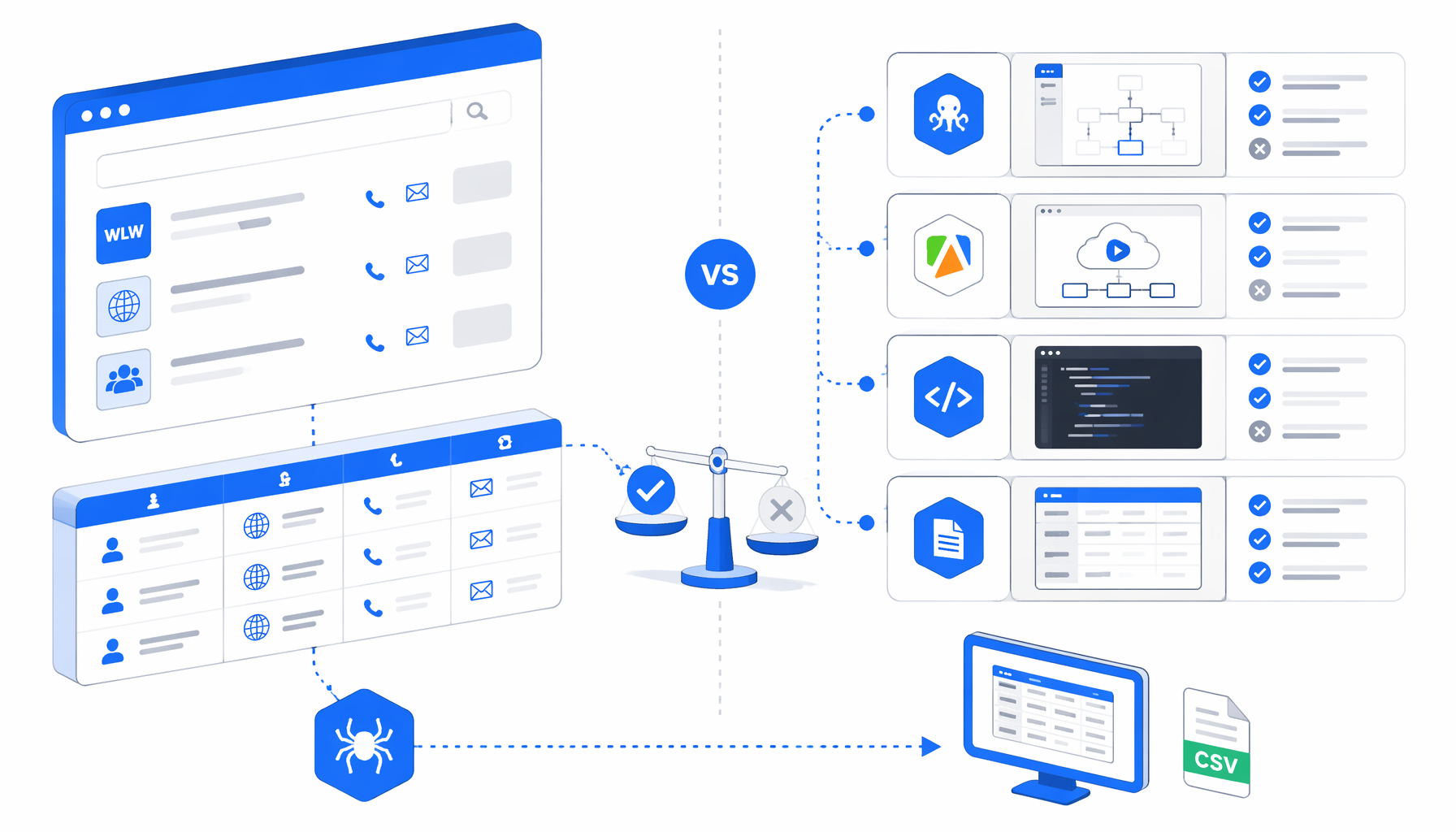
The best WLW lead scraper is not one universal product. Sales ops, procurement, and engineering teams need different trade-offs. This guide compares WLW scraper alternatives across Octoparse templates, Apify actors, managed scraping providers, dedicated WLW tools, Chrome extensions, scripts, and UScraper's WLW.de Lead Scraper template.
CSV
12
wlw.de
No-code
Local
Comparison frame
What a WLW lead scraper has to solve
WLW.de, also known as Wer liefert was, is a B2B supplier marketplace. A useful Wer liefert was scraper should preserve source page URLs, supplier type, location, delivery area, website, phone, email when available, and enough context for a human to verify each row.
That means "how to scrape WLW leads" is really a workflow question:
- Do you want a cloud actor, SaaS visual scraper, local desktop app, browser extension, or custom script?
- Is the job one analyst batch, a monthly sourcing routine, or a production pipeline?
- Should supplier data stay local, live in a vendor dataset, or flow through an API?
The practical question is not "which vendor can extract WLW?" It is "which workflow creates lead rows your team can audit, maintain, and pay for without surprises?"
Side-by-side
WLW scraper alternatives compared
| Option | Best fit | Hosting | Code needed | Output shape | Pricing shape | Main trade-off |
|---|---|---|---|---|---|---|
| UScraper + WLW.de Lead Scraper | Analyst-led supplier research from known company detail URLs | Local desktop app | Low | CSV with company, contact, and firmographic fields | Free template; app licensing applies | Best for visible local runs, not massive parallel cloud crawling |
| Octoparse WLW templates | Teams already using a hosted no-code scraper | Vendor cloud / SaaS workflow | Low | CSV, Excel, or cloud task exports | Subscription tiers and task limits | Convenient visual setup, but less local custody |
| Apify WLW actors | Developer-friendly hosted runs, datasets, and API automation | Apify cloud | Low to medium | Dataset, JSON, CSV, API | Platform usage plus actor/run pricing | Strong automation surface, but data and logs live in cloud workflows |
| Bright Data or managed scraping providers | Enterprise-scale extraction, compliance review, and managed delivery | Vendor infrastructure | Low to medium | API, dataset, or custom delivery | Managed or usage-based pricing | Powerful for scale, usually too heavy for a small CSV job |
| NanoScrape, Niomaker, or niche WLW tools | Purpose-built extraction where the UI exactly matches the task | Usually hosted or browser-assisted | Low | CSV, Excel, JSON, or provider-specific export | Product-specific pricing | Fast to test, but vendor depth and maintenance vary |
| Chrome extension scrapers | One-off lead pulls by a single operator | Browser extension | Low | CSV, Excel, JSON | Extension plan or freemium | Convenient, but harder to govern across repeatable projects |
| Open-source or Python scripts | Engineering teams that need parser ownership | Your environment | High | Whatever you build | Engineering time plus proxy/rendering costs | Maximum control, maximum maintenance burden |
| ParseHub-style generic visual scrapers | Teams that want a general web scraping builder | Vendor cloud | Low to medium | CSV, JSON, integrations | SaaS subscription tiers | Flexible, but WLW-specific polish depends on your setup |
This is not a universal ranking. If engineering needs scheduled API collection, an Apify actor or script can be right. If procurement has vetted company detail pages and wants a reviewable CSV, a local desktop workflow is usually simpler.
Where UScraper wins
When UScraper is the better WLW scraper alternative
UScraper wins when the job is controlled, CSV-first, and audit-heavy. The companion WLW.de Lead Scraper template opens company detail URLs, waits for the page, handles consent prompts, clicks available contact buttons, and appends one row per profile into a local CSV.
The export is designed around lead review, not raw HTML capture: URL, company name, location, overview, verified status, delivery area, founding year, employee count, supplier type, website, phone, and email. A visible block graph is easier to explain than an opaque hosted task when a contact field is blank or a supplier type looks wrong.
UScraper wins when source URLs and CSV exports should remain on machines your team controls.
UScraper wins when analysts need to inspect waits, reveal clicks, selectors, and export columns.
Hosted platforms win when the scraper must run continuously, expose an API, and retry remotely.
Scripts win when engineers need tests, queues, custom storage, typed schemas, and full parser control.
Octoparse and Apify
Octoparse WLW scraper alternative vs Apify WLW scraper
Octoparse and Apify sit on different sides of the hosted category. Octoparse is a no-code SaaS scraper, useful when operators want templates, visual task design, and spreadsheet-style exports. If your team already pays for Octoparse and needs a WLW lead, listing, or detail template, it can be the shortest path to a test.
Apify is more attractive when developers need datasets, actor runs, API calls, scheduled jobs, integrations, or pay-per-run orchestration. It is usually a better fit for pipeline work than for a one-person CSV export.
UScraper is narrower: local browser execution, visible workflow blocks, and a CSV file on your machine. That scope is a strength when the workload is periodic and review-driven. It is a weakness when you need cloud concurrency, queue management, or remote API delivery.
Compliance
Do not skip WLW.de policy review
WLW company pages may be visible in a browser, but automated extraction can still be limited by terms of use, robots guidance, database rights, privacy rules, contract duties, and outreach regulations.
Keep the first run small. Use supplier pages you are permitted to access. Do not bypass login walls, CAPTCHA, payment gates, or technical access controls. Avoid collecting fields you do not need.
Decision guide
Which WLW scraping tool should you pick?
Pick UScraper if your workflow starts from known WLW.de company detail URLs, the output should be CSV, and the person responsible for the data wants to inspect the run locally. Start with the WLW.de Lead Scraper template, validate five supplier pages, then expand only after the exported fields match the source pages.
Pick Octoparse if your team already uses its no-code environment. Pick Apify if engineers want actors, datasets, APIs, and scheduled cloud automation. Pick Bright Data or a managed provider if procurement needs enterprise support. Pick scripts if engineering is prepared to own parsing, monitoring, proxies, retries, tests, and schema drift.
For adjacent workflows, browse the UScraper template library or read the step-by-step WLW.de scraping tutorial after this comparison.
FAQ
WLW lead scraper FAQ
The best WLW lead scraper depends on the operating model. Use UScraper for local CSV exports from approved company detail URLs. Use cloud actors, SaaS scrapers, or scripts when scheduling, API orchestration, or custom engineering matters more.
Next step
Download the WLW.de lead scraper template
If UScraper fits your operating model, import WLW.de Lead Scraper, add a small approved URL list, and compare the first CSV rows against the browser before batching. For more options, return to the UScraper blog or browse all templates.