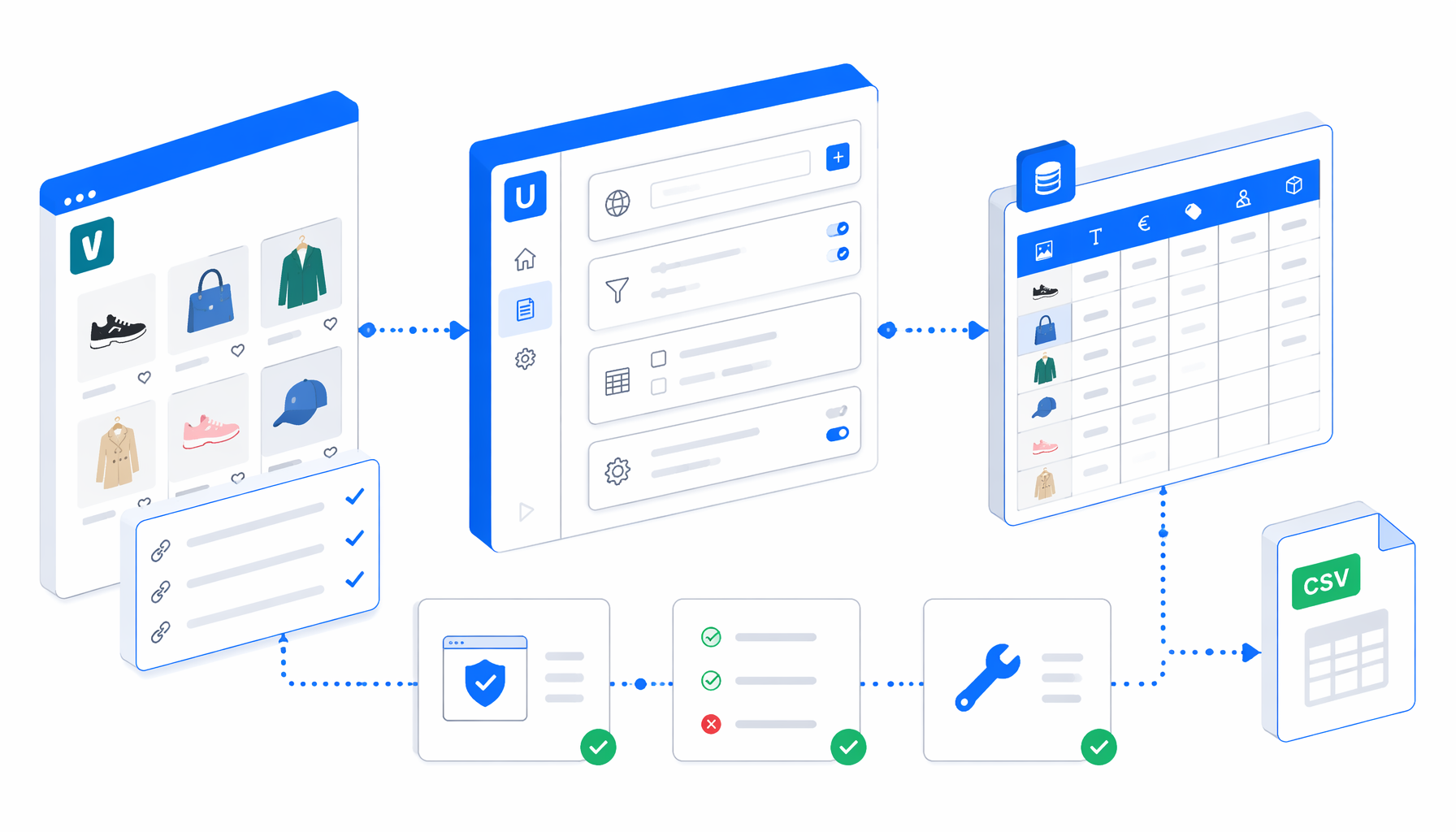
This Vinted scraping tutorial shows how to turn a Vinted catalog or search URL into a CSV export with the Vinted Scraper by URL template for UScraper. You will import the workflow, replace the sample URL, run one controlled test, and validate the rows before using the data.
Before you start
Prerequisites for scraping Vinted by URL
You need UScraper installed as a local desktop app, the Vinted Scraper by URL template, a Vinted catalog or search URL you are allowed to process, and a folder where the CSV can be written. Start with one narrow URL, such as a specific keyword, brand, size, category, or price filter.
This guide covers public catalog-style pages only, not private messages, account dashboards, checkout flows, seller tools, or CAPTCHA bypassing. Vinted Pro Integrations are for approved inventory workflows, not general public catalog research.
Technical access is not the same as permission. Keep runs modest, avoid access-control bypassing, and document why each dataset is being collected.
Workflow anatomy
How the Vinted scraper by URL works
The companion JSON is the authoritative workflow definition: Set Window Size -> Navigate -> Wait -> Inject JavaScript -> Wait for rows -> Structured Export -> End. The Navigate block contains the Vinted URL. Replace the bundled sample with your own catalog or search URL while keeping useful filters in the query string.
The JavaScript block creates a hidden result container, collects catalog items when same-origin responses are available, fetches detail data for discovered item IDs, and normalizes each record into data-* attributes.
If that API path is blocked, empty, or returns an unexpected response, the workflow scrolls the visible page and extracts partial rows from listing cards. If neither path works, the CSV still receives a diagnostic row with scrape_status set to blocked_or_empty. That status is intentional: it prevents a failed run from looking like a successful empty dataset.
Runbook
How to scrape Vinted listings to CSV
Import the template
Open Vinted Scraper by URL, download the JSON workflow, and import it into UScraper.
Replace the Vinted URL
In the Navigate block, paste the exact Vinted catalog or search URL you want to scrape. Keep filters such as keyword, category, brand, size, order, and price when they matter.
Prepare the browser session
Open Vinted normally first if you need to accept cookies, pick a region, sign in, or clear a verification prompt. Do not automate around access controls.
Set the export folder
Structured Export writes vinted_data_scraper_by_url.csv with headers. Change the save location to a project folder before client, market, or category runs.
Run one test and inspect
Run one URL, open the CSV, compare rows with the browser, and check scrape_status. Only widen the search after the first run passes validation.
For recurring research, duplicate the workflow per category or market instead of overwriting one configuration. Keep the source URL and run date with the CSV.
Output
What the Vinted to CSV export includes
The export is designed for spreadsheet review, not raw HTML archiving. It captures title, price, buyer-protection price, brand, size, condition, photos, seller fields, address text, item URL, item ID, and scrape status.
| Status | Meaning | Next action |
|---|---|---|
api_ok | The browser session returned structured catalog or detail data | Spot-check titles, prices, URLs, and seller fields |
dom_fallback_partial | API access failed, but visible cards produced partial rows | Accept for lightweight review or tune selectors for richer data |
blocked_or_empty | No API rows and no visible listing cards were collected | Check the URL, prompts, login state, rate limits, and browser trust |
API comparison
Vinted API vs scraper: when each path fits
People often search for a Vinted API scraper because they want stable data without maintaining selectors. The trade-off is that official integrations, hosted scraper actors, Python packages, and local browser workflows solve different problems.
| Approach | Best fit | Trade-off |
|---|---|---|
| UScraper Vinted scraper by URL | No-code, supervised CSV exports from known search URLs | You validate waits, access state, and selectors when Vinted changes |
| Official Pro Integrations | Approved seller or inventory synchronization workflows | Not a general public marketplace research API |
| Hosted Vinted scraper tools | Scheduling, cloud infrastructure, managed scale, API access to datasets | Data custody, cost, and scraping behavior depend on the vendor |
| Python Vinted scraper packages | Developer-controlled pipelines and custom enrichment | Requires code, maintenance, anti-bot handling, and operational QA |
If your goal is production resale infrastructure, official or contracted access may be more durable. If your goal is a local research CSV for a known URL, the UScraper template library is faster to test.
FAQ
Vinted scraper by URL FAQ
Vinted listings can be publicly visible and still be governed by Vinted terms, robots directives, copyright, privacy law, marketplace policies, and local rules. Use modest pacing, do not bypass login, CAPTCHA, or access controls, avoid sensitive personal data, and get legal review before commercial monitoring or resale use.
Next step
Download the Vinted scraper by URL template
Download the JSON from Vinted Scraper by URL, import it into UScraper, and keep this guide open for the first validation pass. For neighboring workflows, browse all UScraper templates or the UScraper blog for more CSV export tutorials.