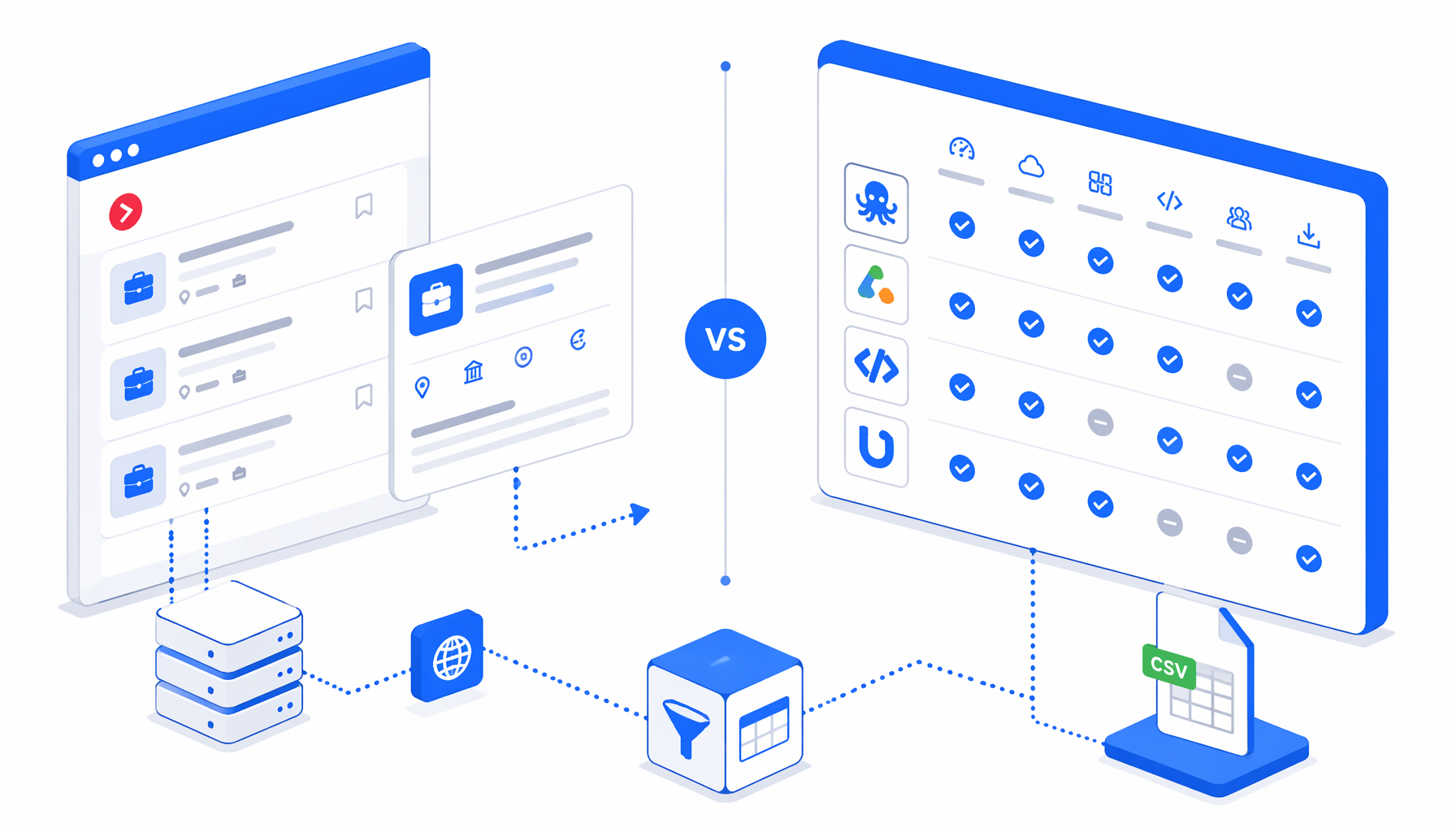
Choosing a Universia job scraper alternative is mostly about where the browser runs, who maintains the workflow, and whether the final output is a clean CSV or a vendor-hosted dataset. This comparison shows where Octoparse, Apify-style actors, SaaS scrapers, Zapier workflows, open-source scripts, and UScraper's Universia Job Details Scraper template fit.
Decision frame
What a Universia job scraper should extract
Universia job pages combine employer, role, location, contract terms, modality, compensation hints, schedule, description, and requirement text. A basic listings scraper can capture titles and links, but recruiting analysts usually need detail-page fields before comparing roles across markets.
The UScraper Universia template is built for that detail-page job. The stock workflow starts from a Universia search URL, accepts the cookie prompt when it appears, waits for job links, opens same-origin detail pages in hidden frames, reads JobPosting JSON-LD plus rendered text, creates hidden extraction rows, and writes a CSV with titulo, empresa, localidad, publicidad, modalidad, contrato, remuneracion, jornada, horario, descripcion, informacion, requisito, and url.
The practical question is not "which scraper has the biggest platform?" It is "can my team explain where the data ran, what each column means, and how to fix the workflow when Universia changes markup?"
Side-by-side
Universia job scraper alternatives compared
| Alternative | Best fit | Hosting | Code needed | Output shape | Pricing shape | Main trade-off |
|---|---|---|---|---|---|---|
| Octoparse Universia Job Details Scraper | Direct no-code Universia template | Octoparse platform | Low | Table export such as CSV or Excel | Free template; paid platform tiers for heavier usage | Closest direct alternative, but workflow custody sits inside a SaaS platform |
| Apify jobs marketplace | Hosted actors, datasets, APIs, and repeat jobs | Apify cloud | Low to medium | Dataset, JSON, CSV, API | Platform usage plus actor pricing | Strong cloud infrastructure, but not always Universia-specific |
| Zapier plus Apify or ZenRows | Send scraped jobs into sheets, email, or alerts | Cloud integration chain | Low | Google Sheets, email, webhooks | Multiple subscriptions or credit meters | Great automation, more moving parts to debug |
| ParseHub-style no-code projects | Custom visual job-board extraction | Vendor app plus cloud options | Low | CSV, Excel, JSON | Free and paid SaaS plans | Flexible, but each Universia variant still needs setup and testing |
| JobSpy and scripts | Engineering-owned job data pipelines | Your machine or server | High | DataFrame, JSON, CSV | Open source plus infrastructure cost | Maximum control, but Universia support and maintenance are yours |
| UScraper Universia Job Details Scraper | Local CSV from a visible no-code flow | Local desktop app | Low | CSV with 13 columns | Free template; app licensing applies | Best for inspectable local runs, not massive cloud concurrency |
No row wins every case. Data engineering teams may prefer Apify. A no-code team already paying for Octoparse may prefer its template. A research analyst who needs a repeatable Universia CSV without a cloud actor has a different set of priorities.
Where UScraper fits
When UScraper is the right no-code job scraper
UScraper fits teams that want the workflow visible and local. The Universia template is not a black-box endpoint. It shows navigation, waits, cookie handling, JavaScript extraction, hidden detail-page parsing, and Structured Export. When a field is blank, the operator can inspect whether the issue is page source, selector, label text, wait timing, or a missing value.
That matters because Universia country pages and job-detail layouts can vary. The bundled template was tested against an Argentina sample query for Ingeniero in Buenos Aires, but the workflow is meant to be adjusted. Change the start URL, keep the waits, run a small batch, spot-check url values, then review blank fields before expanding.
Local data custody
The browser flow and CSV export run in the local desktop app. That is useful when job research should stay in folders the team administers.
Visual maintenance
Waits, click logic, injected JavaScript, and export columns are visible blocks, so non-engineers can review the flow before asking for code help.
CSV-first output
The template writes universia-detalles-de-empleo-scraper.csv, which is simpler for spreadsheet QA than a hosted dataset that must be pulled through an API.
Honest scale boundary
This is a local workflow for controlled batches. If you need high-concurrency cloud crawling, hosted actors or managed scraping APIs are better fits.
Where alternatives win
When Octoparse, Apify, Zapier, ParseHub, or scripts make more sense
Octoparse has a direct Universia Job Details Scraper template and a Spanish-localized version. It is the natural comparison for octoparse Universia alternative searches. Choose it when your team already uses Octoparse or values its larger template marketplace.
Compliance
Legal and robots checks before scraping Universia jobs
Universia is an official employment and internships portal with country-specific job pages, including Spain, Mexico, Argentina, and Colombia. Before collecting rows, review the relevant page terms, privacy policy, and robots.txt. The robots file includes disallowed parameter patterns and allowed first-page employment patterns, so do not assume every filtered or paginated URL is treated the same.
For lower-risk operational practice, start from the official Universia result page you are allowed to review, run a small sample, retain the source url, and keep a human review step before rows are merged into recruiting, market-intelligence, or AI-training workflows.
FAQ
FAQ
What is the best Universia job scraper alternative?
The best Universia job scraper alternative depends on hosting, scale, code ownership, and export format. Octoparse is the closest direct no-code marketplace alternative, Apify and Zapier fit hosted automation, scripts fit developer-owned pipelines, and UScraper fits local CSV workflows with an inspectable visual flow.
How do I scrape Universia jobs without code?
Use a no-code workflow that starts from a Universia search URL, waits for job links, opens each detail page, extracts structured and rendered job fields, and exports rows to CSV. UScraper packages that flow in the Universia Job Details Scraper template.
Is Octoparse the closest Universia scraper alternative?
Yes. Octoparse has a direct Universia Job Details Scraper template, so it is the most obvious side-by-side comparison. The trade-off is that Octoparse is a broader no-code scraping platform with cloud and subscription options, while UScraper emphasizes local execution and visible workflow blocks.
Is it legal to scrape Universia jobs?
Universia job pages may be publicly visible, but automated collection can still be governed by Universia terms, robots guidance, privacy law, copyright, database rights, employment-data rules, and local regulations. Do not bypass technical controls, keep volume modest, and get legal review before commercial reuse.
What does the UScraper Universia template export?
The template exports CSV columns for titulo, empresa, localidad, publicidad, modalidad, contrato, remuneracion, jornada, horario, descripcion, informacion, requisito, and url. Browse more local desktop workflows in the UScraper template library, or continue reading related comparisons on the UScraper blog.