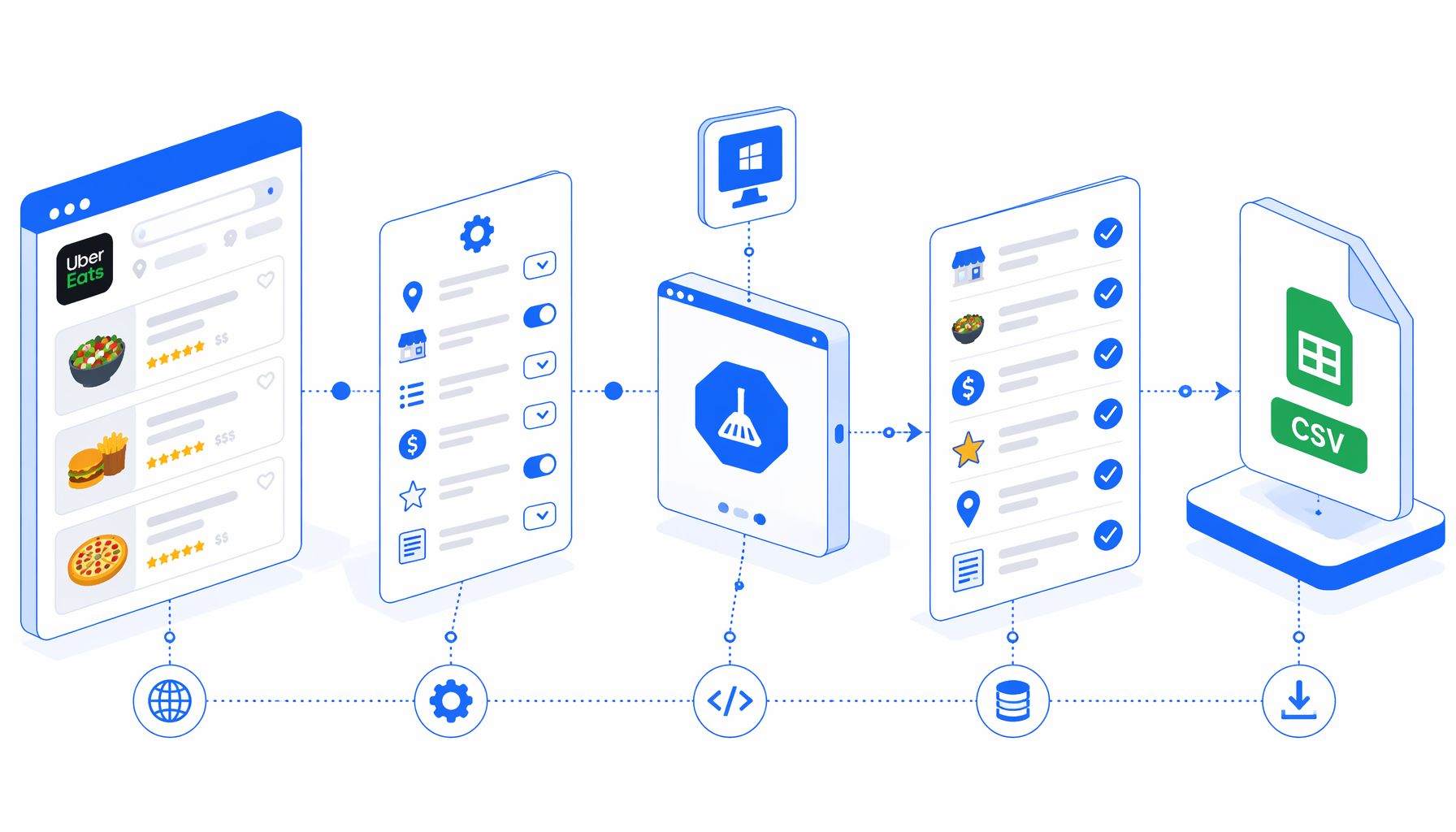
This tutorial shows how to scrape Uber Eats restaurant data into CSV with the Uber Eats Restaurant Details Scraper for UScraper. You will prepare store URLs, import the workflow, set the export path, validate menu rows, and decide when the official Uber Eats API or a coded scraper is the better fit.
CSV
19
Store URLs
Best effort
Locally
Before you start
Prerequisites before you scrape Uber Eats
You need UScraper installed, one or more Uber Eats restaurant or store detail URLs, and a local folder where the CSV can be written. Start with three to five store pages from the same city because Uber Eats can show address prompts, availability differences, closed-store states, and regional menu layouts.
This guide is for supervised collection from pages you can inspect in a normal browser. It is not a guide to bypass sign-in walls, CAPTCHA, address restrictions, blocked sessions, or other access controls. Before reusing exported restaurant or menu data, review the live Uber Eats site, current Uber Eats robots.txt, the Uber Eats Marketplace API getting started guide, and any contract or policy that applies to your use case.
Visible data still needs a lawful and permitted use. Keep the run small, document why you collected the rows, and stop when the site asks for manual verification.
Choose the path
Uber Eats restaurant scraper vs API vs coded scraper
The right route depends on what you are trying to control: speed, official access, infrastructure, or code ownership.
Use UScraper when a market researcher, restaurant operator, analyst, or agency needs a spreadsheet from prepared public store URLs. The workflow is editable, local, and does not require maintaining browser automation code.
| Option | Best fit | Main trade-off |
|---|---|---|
| UScraper Uber Eats Restaurant Details Scraper | No-code CSV exports from known store URLs | You must validate dynamic pages and rerun carefully when layout changes |
| Official Uber Eats Marketplace API | Approved partner or merchant integrations | Requires credentials, scopes, business approval, and implementation work |
| Python or Selenium scraper | Engineering-owned data pipelines | Your team owns browser behavior, selector drift, retries, and output QA |
Export shape
What the Uber Eats restaurant details scraper extracts
The template is designed for Uber Eats store detail pages, not generic search results. Add restaurant URLs to the Navigate block and the workflow loops over them. After the page loads, it scrolls to reveal lazy-loaded menu cards, injects JavaScript to create stable hidden export rows, and lets Structured Export write one row per detected dish.
Each dish row carries restaurant context beside menu fields, which helps compare price points, cuisine labels, menu depth, ratings, locations, and dish descriptions.
uber-eats-restaurant-details-scraper.csvColumn
Restaurant
Store name from the page.
Column
Restaurant_URL
Source Uber Eats store detail URL.
Column
Cuisine_type
Cuisine labels when detected.
Column
Rating
Visible rating value.
Column
Dish_category
Nearest menu section heading above the item.
Column
Dish_name
Detected menu item name.
Column
Price
Menu item price from the rendered card.
Column
Description
Dish description when shown.
The bundled JSON defines the extraction intent: Navigate through multiple restaurant URLs, wait for page load, sleep briefly, run preprocessing JavaScript, wait for .uscraper-menu-row, export custom columns, and continue the loop. Here is the operational summary, not the full graph:
{
"project": {
"name": "Uber Eats Restaurant Details Scraper",
"description": "Scrapes Uber Eats restaurant/store detail URLs and exports restaurant metadata plus menu dish details."
},
"export": {
"fileName": "uber-eats-restaurant-details-scraper.csv",
"rowSelector": ".uscraper-menu-row",
"fileMode": "append",
"columns": [
"Restaurant",
"Restaurant_URL",
"Cuisine_type",
"Price_range",
"Locality",
"Region",
"Postal_code",
"Country",
"Street",
"Latitude",
"Longitude",
"Telephone",
"Rating",
"Review_count",
"Error_message",
"Dish_category",
"Dish_name",
"Price",
"Description"
]
}
}
Run it
How to scrape Uber Eats restaurant data with UScraper
Collect store detail URLs
Open each restaurant in Uber Eats and copy the store URL, not a broad search page. If you need discovery first, use the Uber Eats Restaurant Listing Scraper, then feed detail URLs into this template.
Import the template
Download the JSON from the template page and import it into UScraper. Keep the sample URLs until you understand the loop, wait, JavaScript, export, and loop-continue blocks.
Replace the URL list
In the Navigate block, replace the sample store URLs with your own. Keep the first run small and use restaurants from the same region so prompts and menu formats are easier to compare.
Set the export folder
Open Structured Export and choose the save location. The default file name is uber-eats-restaurant-details-scraper.csv, headers are enabled, and append mode is on.
Run one QA pass
Run a single URL. Confirm that restaurant metadata, dish category, dish name, price, and description match the visible page before you trust a larger batch.
Export the batch
Add the remaining URLs, rerun, and deduplicate later by restaurant URL, dish name, and price if you test the same store more than once.
Validate the CSV before using it
Open the CSV and sort by Error_message first. A populated error usually means the page required address selection, blocked the session, changed layout, or loaded no detectable menu cards. Then sample several restaurants manually against the source page.
For analysis, keep the raw export untouched and create a cleaned copy. Normalize currencies, split city and region fields if needed, and add your own run date column outside the scraper output.
Troubleshooting
Common Uber Eats scraping issues
Choose a delivery area manually if your use case permits it, then rerun the same store URL. Availability can vary by address, which is why the template prefers known detail URLs.
FAQ
FAQ
Is it legal to scrape Uber Eats restaurant data?
Uber Eats restaurant pages can include public information, but scraping may still be limited by Uber terms, robots directives, copyright in menu content, privacy rules, and local law. Use conservative pacing, avoid bypassing access controls, stop on verification prompts, and get legal review before commercial reuse, resale, or publication.
Do I need the official Uber Eats API?
Not for the UScraper workflow described here. The template opens public store URLs in a browser session and exports visible restaurant and menu data to CSV. Use the official Uber Eats Marketplace APIs when you have approved access, a business agreement, and a production integration need for stores, menus, or orders.
What does the Uber Eats restaurant scraper export?
The CSV includes restaurant, URL, cuisine type, price range, address fields, coordinates, telephone, rating, review count, error message, dish category, dish name, price, and description.
Where does UScraper save the Uber Eats CSV?
Structured Export writes uber-eats-restaurant-details-scraper.csv to the configured save location. Headers are enabled and append mode is on, so reruns can add duplicates unless you rename or clear the file first.
Why are some Uber Eats rows empty or incomplete?
Uber Eats is dynamic and may show address prompts, region-specific menus, lazy-loaded cards, bot checks, closed stores, or changed markup. Test one store URL first, confirm the visible page is accessible, and treat the Error_message column as a QA signal.
Related templates and next steps
Use the Uber Eats Restaurant Details Scraper when you already have store URLs and need menu rows. Use the Uber Eats Restaurant Listing Scraper when your first task is collecting restaurant URLs from listings. You can browse more no-code workflows in the template library or read more tutorials in the UScraper blog.