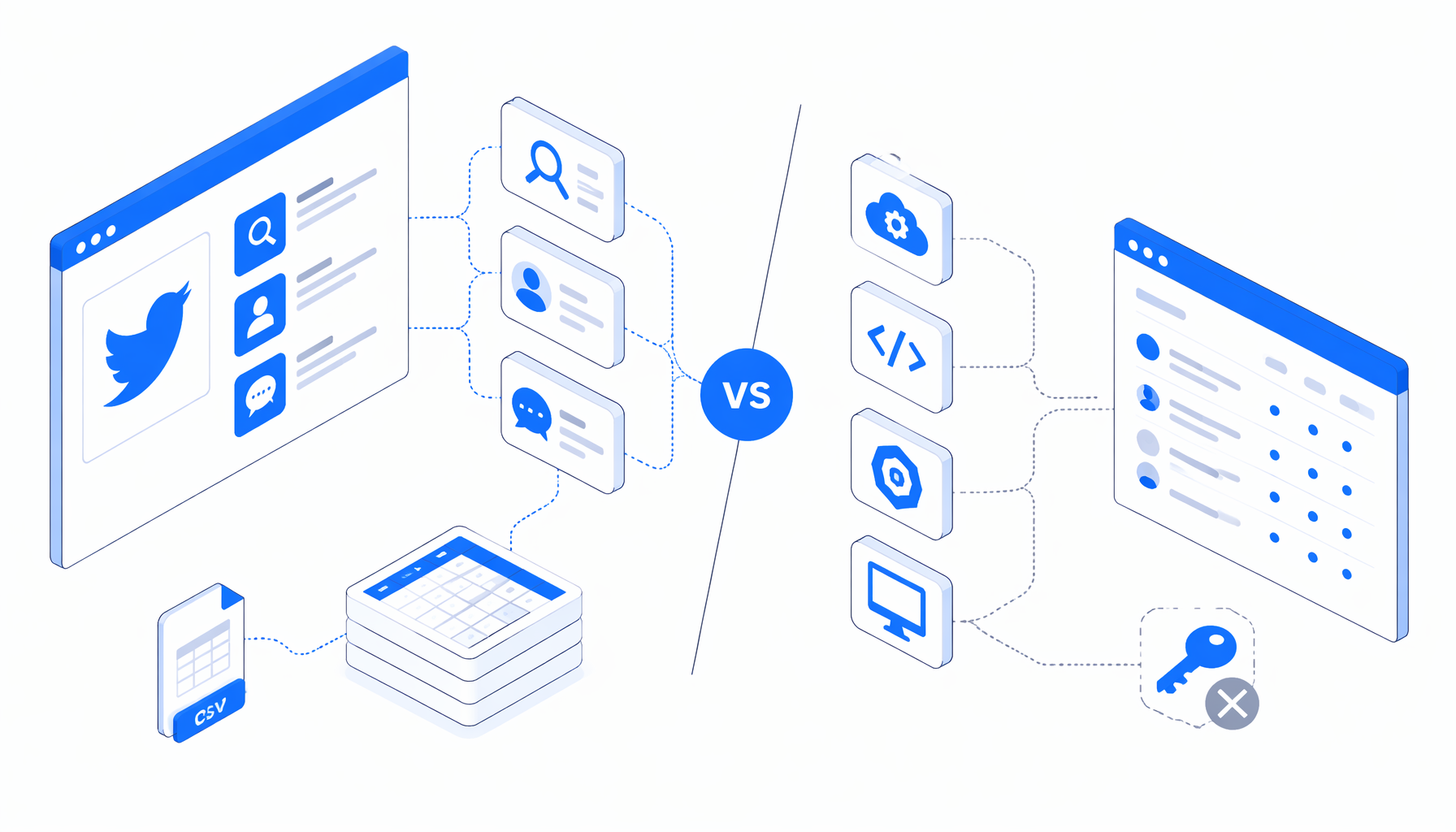
The best Twitter scraper tools are not interchangeable. X search monitoring, profile research, follower collection, post analytics, and Twitter to CSV exports all need different trade-offs. This guide compares the official X API, Octoparse, Apify, Bright Data, PhantomBuster, open-source scripts, and UScraper's Twitter Data Scraper for CSV Export.
Comparison frame
What Twitter scraper alternatives actually differ on
Search results for twitter scraper alternatives mix official APIs, no-code tools, actor marketplaces, enrichment automations, and Python libraries. Compare the workflow before the brand:
- Source: timeline, search results, hashtags, replies, followers, media, or post URLs.
- Access: official API, visible web page, authenticated browser session, vendor dataset, or custom account pool.
- Hosting: local desktop app, SaaS cloud, managed data provider, browser extension, or your own server.
- Output: CSV, Excel, JSON, API response, dataset table, Google Sheets, or CRM handoff.
- Cost: app license, SaaS plan, actor runs, API tier, result billing, or engineering time.
The practical question is not "which tool can scrape Twitter?" It is "which workflow produces the right rows, in the right custody model, with a maintenance burden your team can own?"
Side-by-side
Twitter scraper tools compared
| Option | Best fit | Hosting | Output | Main trade-off |
|---|---|---|---|---|
| UScraper + Twitter Data Scraper | Controlled profile, hashtag, timeline, and search exports | Local desktop app | CSV with tweet, author, engagement, media, and diagnostics | Strong for local CSV review, not cloud-scale pipelines |
| Official X API | Approved apps, governed search, production integrations | X infrastructure | API responses | Best governance route, but not no-code |
| Octoparse Twitter templates | Hosted no-code scraping for profiles, search, and keywords | Vendor platform | Table exports | Visual builder, but execution and data live in a vendor workflow |
| Apify Twitter actors | Scheduled actors, datasets, APIs, search, profiles, followers | Apify cloud | Dataset, JSON, CSV, API | Strong infrastructure; cloud run state and usage billing apply |
| Bright Data Twitter scraper | Enterprise-scale posts, profiles, APIs, and managed datasets | Vendor infrastructure | API, dataset, JSON, CSV | Powerful at scale, often heavy for one spreadsheet workflow |
| PhantomBuster Twitter Profile Scraper | Profile enrichment and growth workflows | Vendor cloud | CSV or JSON | Better for profiles than tweet search analysis |
| twscrape and custom scripts | Engineers who want code, queues, tests, storage, and retries | Your server or machine | Whatever you build | Maximum control, highest maintenance burden |
Where UScraper wins
When UScraper is the better Twitter scraper alternative
UScraper wins when the requirement is narrow and auditable: scrape Twitter search results or visible X timelines into a local CSV that a person will inspect. The Twitter Data Scraper template starts from an editable X URL, so the same workflow can target a profile timeline, hashtag, search result, or advanced-search page that loads in the desktop browser session.
The workflow sets a large viewport, navigates, waits for client-rendered content, injects a collector script, scrolls through visible batches, de-duplicates tweet cards, creates hidden export rows, and runs Structured Export.
Set Window Size -> Navigate -> Wait -> Inject JavaScript
-> Scroll and collect -> Structured Export -> End
The stock export writes twitter-scraper.csv with page_status, blocked_reason, profile fields, author name, handle, timestamp, tweet text, tweet URL, replies, reposts, likes, views, bookmark label, media URLs, and captured page URL. If X shows a login wall, CAPTCHA, rate limit, or guest-access block, the template exports a diagnostic row instead of pretending the page had no tweets.
Where competitors win
Twitter scraper vs X API, SaaS tools, and scripts
Choose the official X API for production integrations, customer-facing products, or datasets with contractual and redistribution requirements. Choose Apify for hosted actors, schedules, datasets, logs, webhooks, and developer handoff. Choose Bright Data when procurement, managed infrastructure, support, and delivered datasets matter more than block-level editing.
Choose Octoparse when the team already uses hosted no-code scraping and wants visual task setup. Choose PhantomBuster when the job is closer to profile enrichment or growth automation. Choose twscrape, Playwright, Selenium, or custom scripts when engineering wants complete parser control and accepts account handling, selector drift, storage, monitoring, and tests.
Policy
X rules should shape the scraper choice
X/Twitter data can be public to read and still restricted for automated collection or reuse. Review the current X API documentation, X terms, and robots directives. Avoid bypassing login walls, CAPTCHA, rate limits, technical blocks, private content, account restrictions, or access controls.
Decision guide
Which Twitter scraper tool should you pick?
Pick UScraper for local Twitter to CSV exports, the X API for approved production access, Apify or Bright Data for hosted data pipelines, Octoparse for hosted no-code tasks, PhantomBuster for profile automation, and scripts when engineering wants full parser control. Browse the UScraper template library for adjacent social scraping workflows, or read more comparison guides on the UScraper blog.
FAQ
Twitter scraper tools FAQ
The best Twitter scraper tool depends on the workflow. Use the official X API for governed production access, Apify or Bright Data for hosted data pipelines, PhantomBuster for profile automation, Octoparse for hosted no-code scraping, scripts when engineers own maintenance, and UScraper when an analyst wants a local desktop app workflow that exports visible tweets to CSV.
Next step
Try the Twitter Data Scraper template
Download Twitter Data Scraper for CSV Export, import the JSON into UScraper, replace the default X URL with a permitted profile, hashtag, search, or advanced-search URL, and run a small validation batch before widening the query.