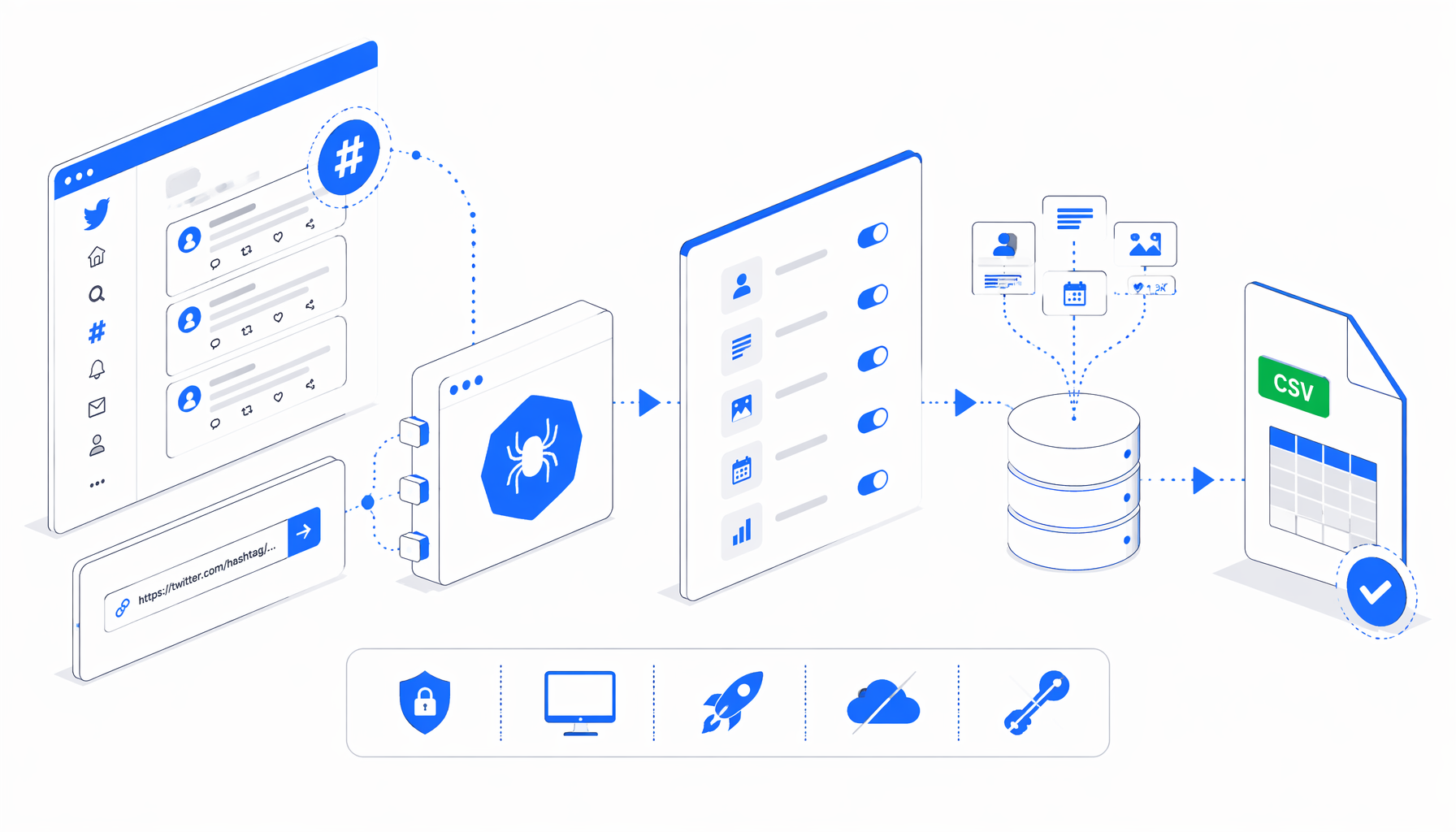
This tutorial shows how to scrape Twitter hashtags into CSV with the Twitter Hashtag Scraper template for UScraper. You will prepare tweet URLs, set the export path, run a validation batch, and check the fields.
Before you start
Prerequisites before you scrape Twitter hashtags
You need UScraper installed as a local desktop app, a CSV output folder, and a short list of X/Twitter status URLs connected to the hashtag. Start with one campaign, event, launch, or brand tag.
The Twitter Hashtag Scraper for CSV Export is the download path. The bundled workflow uses sample #fridayfeeling tweet URLs because X search can redirect unauthenticated sessions to login or onboarding.
A tweet loading in your browser is a validation condition, not a complete permission model. Keep the source hashtag, URL list, run date, and export file together so the CSV can be explained later.
Input
Choose a hashtag query and tweet URL list
A Twitter hashtag scraper is most useful when the input list is deliberate. Search the hashtag manually in X, an approved internal workflow, or another compliant source. Then collect tweet detail URLs you are allowed to process, such as https://x.com/account/status/123..., and paste them into the Navigate block.
Compared with the official API, the UScraper route is simpler for a supervised spreadsheet export: open status URLs, read visible tweet fields, and write a local CSV.
| Planning question | Recommended answer |
|---|---|
| Which hashtag? | Use one campaign, topic, or event tag per file |
| First batch size? | Start with 5 to 20 status URLs |
| Account state? | Use a session that is permitted to view the tweets |
Workflow
How the Twitter hashtag scraper template works
The export JSON is the authoritative workflow definition; the summary below explains the extraction intent. The template loops through tweet URLs, waits for the article, creates a hidden normalized row, and exports data attributes into CSV columns.
{
"project": {
"name": "Twitter Scraper by hashtag"
},
"blocks": [
{
"title": "Navigate",
"config": {
"urls": ["https://x.com/Printtapp/status/1768257041947062311"]
}
},
{
"title": "Structured Export",
"config": {
"fileName": "twitter-scraper-by-hashtag.csv",
"fileMode": "append"
}
}
]
}
Use UScraper when the deliverable is a reviewable CSV from a bounded set of hashtag tweet URLs.
Runbook
Step-by-step: scrape tweets by hashtag to CSV
Import the hashtag template
Open the Twitter Hashtag Scraper template from the templates library and import it.
Replace the status URLs
Remove the sample #fridayfeeling URLs and paste approved tweet URLs for your hashtag batch.
Set keyword context
Update the keyword and source search URL so each row points back to the hashtag research intent.
Choose the export folder
Confirm twitter-scraper-by-hashtag.csv, the save location, headers, and append mode.
Run a validation batch
Start with a handful of URLs. If the browser lands on login, onboarding, or an error page, stop and review access.
Spot-check the CSV
Open several tweet_website links and compare author, timestamp, text, media, and engagement labels.
Output
CSV fields to validate after scraping tweets by hashtag
The template exports 15 columns. Engagement values may be blank when X does not expose a label in the current page session. Treat blank as "not captured" unless you verify it means zero.
| Column | What to validate |
|---|---|
category, keyword, web_page_url | The result bucket, hashtag, and source search URL |
tweet_website | The normalized tweet URL |
author_name / author_web_page_url | The visible author and profile URL |
tweet_timestamp, tweet_content | The page timestamp and visible post text |
tweet_image_url / tweet_video_url | Media URLs or poster/current source values when visible |
tweet_ad, reply, repost, like, view | Visible ad and engagement labels |
Troubleshooting
Common Twitter hashtag scraper issues and fixes
The browser session cannot view the target URL. Confirm the URL manually and rerun only when the tweet page loads normally.
Alternatives
Twitter API hashtag search vs scraper alternatives
Use the official X API for application features, recurring pipelines, and formal data access. Use hosted actors for cloud scheduling. Use UScraper for bounded CSV exports where a human validates browser state and local output. For operator syntax, the twitter-advanced-search list can help, but validate every query in the browser first.
FAQ: Twitter hashtag scraping
Is it legal to scrape Twitter hashtags?
X/Twitter posts can be visible in a browser, but automated collection may still be limited by terms, robots directives, copyright, privacy law, account rules, and local regulations. Use approved access where required.
Do I need the X API for Twitter hashtag search?
No X API key is wired into the UScraper template. It opens known tweet detail URLs and exports visible fields. Use the official X API for sanctioned production access or application integration.
What does the Twitter hashtag scraper export?
It writes twitter-scraper-by-hashtag.csv with hashtag context, tweet URL, author, timestamp, content, media URLs, ad flag, and engagement columns.
Why does the template use tweet URLs instead of live hashtag pagination?
Unauthenticated X hashtag search can redirect to login or onboarding. For broader coverage, use only permitted workflows or approved sources to discover status URLs.
Where does UScraper save the hashtag CSV?
Structured Export saves twitter-scraper-by-hashtag.csv to the local folder configured in the workflow. Change it before a final run.