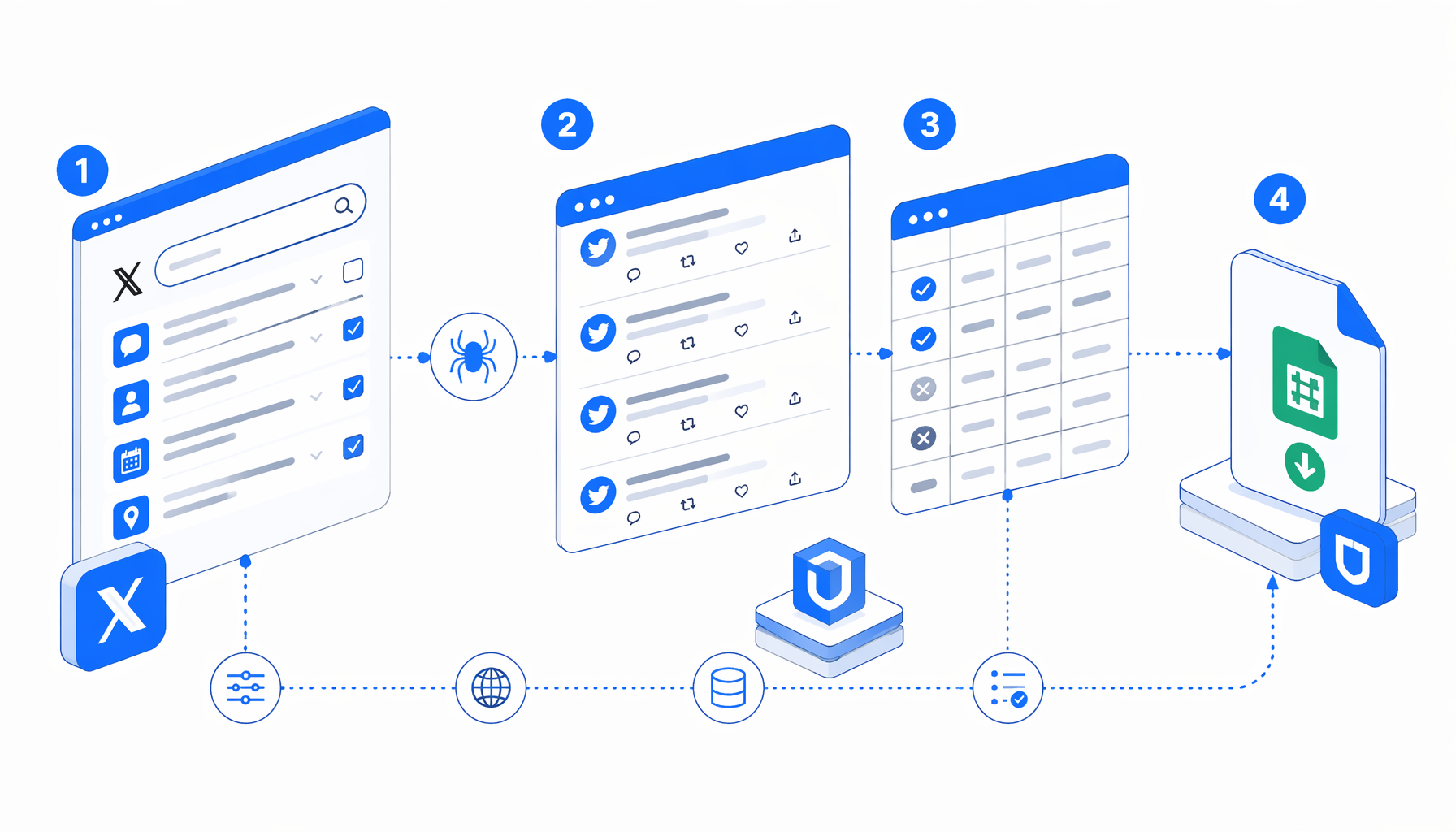
This tutorial shows how to scrape tweets from X/Twitter advanced search into CSV with the Twitter Advanced Search Scraper template for UScraper. You will build a precise search query, import the workflow, set the export path, run a small validation batch, and decide when the official X API or another Twitter scraper alternative is the better fit.
Before you start
Prerequisites before you scrape Twitter search results
You need UScraper installed as a local desktop app, an X/Twitter search URL that loads in your browser session, and a folder where CSV files can be written. Start with one narrow query, not a broad topic. A search for a product name plus a date window is easier to validate than a global word such as "ai" or "launch".
Use X's advanced search page or the standard search box to build the first URL. X's own search help explains the basic search interface and settings, while the X API query documentation is useful when you need a stricter operator reference for production integrations. Community references such as the twitter-advanced-search operator list can help with web-search syntax, but validate every operator in the browser before relying on it for a CSV batch.
A visible search page is a starting point, not a permission model. Do not automate around login walls, verification prompts, private content, account restrictions, or platform defenses.
Search query
Build an X search operators tutorial query
The best Twitter advanced search scraper workflow starts with a query you can explain later. If someone asks where a row came from, the CSV should point back to the exact q parameter and the source search page.
| Goal | Example query pattern | Why it helps |
|---|---|---|
| Search a phrase | "product launch" | Keeps unrelated mentions out of the batch. |
| Search by user | from:examplebrand | Answers "how to search within a Twitter account" without manual scrolling. |
| Search someone's tweets mentioning a topic | from:examplebrand pricing | Useful for brand, founder, competitor, or analyst monitoring. |
| Search by date | since:2026-06-01 until:2026-06-15 | Makes the export reproducible and easier to compare week by week. |
| Exclude noise | product launch -giveaway | Removes repeated campaign or spam terms. |
| Limit to media or links | product launch filter:links | Helps when the analysis needs articles, demos, or campaign URLs. |
For most research, combine three filters: a keyword or exact phrase, an account or hashtag when relevant, and a date range. That structure targets queries like "how to search by date Twitter", "Twitter search by user", and "Twitter until search" while keeping the output small enough to audit.
Workflow
How the Twitter advanced search scraper works
The companion template page is the download path; this article is the operating guide. Import the current Twitter Advanced Search Scraper instead of rebuilding the workflow graph by hand. The JSON export is the authoritative sample of the workflow definition, and the summary below explains the extraction intent.
{
"project": {
"name": "Twitter Advanced Search Scraper",
"description": "Best-effort X/Twitter advanced search scraper for public/search-visible tweets."
},
"blocks": [
{ "title": "Navigate", "config": { "url": "https://x.com/search?q=fringe&src=typed_query" } },
{ "title": "Inject JavaScript", "config": { "waitForCompletion": true, "timeout": 180 } },
{
"title": "Structured Export",
"config": {
"rowSelector": "#uscraper-x-tweet-cache .uscraper-x-tweet-row",
"fileName": "twitter-scraper-by-keywords.csv",
"includeHeaders": true,
"fileMode": "append"
}
}
]
}
| Stage | What it does | What to check |
|---|---|---|
| Set window and navigate | Opens the configured X search URL in a large viewport | Replace the sample URL with your own approved advanced-search URL. |
| Wait and pause | Gives the page time to load dynamic content | If the page redirects to login or onboarding, stop and review access. |
| Scroll collector | Captures loaded tweet cards until results stabilize or the safety loop ends | Very broad queries may load slowly or return noisy rows. |
| Hidden cache | Stores collected tweet rows in a hidden page element | This helps preserve rows that infinite scroll might virtualize away. |
| Structured Export | Maps cached data attributes into CSV columns | Confirm the file name, save folder, headers, and append mode. |
Runbook
Step-by-step: export Twitter search to CSV
Import the template
Open the Twitter Advanced Search Scraper template from the UScraper templates library and import the JSON workflow into the desktop app.
Paste a tested search URL
Build the query in X advanced search, run it manually, then paste the resulting https://x.com/search?q=... URL into the Navigate block.
Set the export path
In Structured Export, choose the folder for twitter-scraper-by-keywords.csv. Keep validation files separate from reporting or client batches.
Run one narrow batch
Start with a phrase, account, or date window that returns a manageable number of visible tweets. Let the scroll collector finish before opening the CSV.
Validate before scaling
Open several tweet URLs from the CSV, compare text and timestamps against the browser, and only then expand the query list or date range.
Output
CSV fields to validate after scraping tweets
The stock export writes one row per collected tweet card or diagnostic state. Blank engagement values should be treated as missing display data, not as zero, because X can hide, delay, or format counts differently across sessions.
twitter-scraper-by-keywords.csvColumn
Query_Str
The q parameter from the current X search URL.
Column
Post_URL
The search page opened during the run.
Column
Author_Name
Visible display name from the tweet card.
Column
Author_Handle
Handle parsed from the status URL or card text.
Column
Verified_Status
Whether a verification indicator is visible.
Column
UTC_Time
Datetime from the tweet time element.
Column
Tweet_Content
Tweet text or a diagnostic message.
Column
Tweet_URL
Canonical status URL when exposed.
Column
Reply_Count
Visible reply count parsed from the card.
Column
Repost_Count
Visible repost count.
Column
Like_Count
Visible like count.
Column
View_Count
Visible view count when available.
Column
Tweet_Image_URL
Visible media URLs joined into one field.
Column
Language
Language attribute from the tweet text element.
Sample rows
1 of many
| Query_Str | Post_URL | Author_Name | Author_Handle | Verified_Status | UTC_Time | Tweet_Content | Tweet_URL | Reply_Count | Repost_Count | Like_Count | View_Count | Tweet_Image_URL | Language |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| product launch since:2026-06-01 | ... | Example Brand | examplebrand | true | 2026-06-14T10:12:00.000Z | Launch thread with a demo clip. | 14 | 86 | 420 | 18K | en |
Tool choice
Twitter scraper alternatives: local app, API, or cloud tools
Use UScraper when an analyst, marketer, researcher, or agency operator needs a supervised CSV export from a known search URL. It is strongest for bounded work: query validation, local file custody, visual workflow edits, and same-day spreadsheets.
Troubleshooting
Common issues and FAQs
Public or search-visible X/Twitter posts can still be subject to platform terms, robots directives, privacy law, copyright, account rules, and local regulations. Use approved access where required, keep batches narrow, avoid bypassing login or verification controls, and get legal review before commercial reuse, redistribution, enrichment, or model training.
Next step
Download the workflow and run a validation query
Start with the Twitter Advanced Search Scraper template, use one phrase plus a recent date range, and export a short CSV before expanding. For adjacent workflows, browse the UScraper templates library or read more UScraper tutorials.