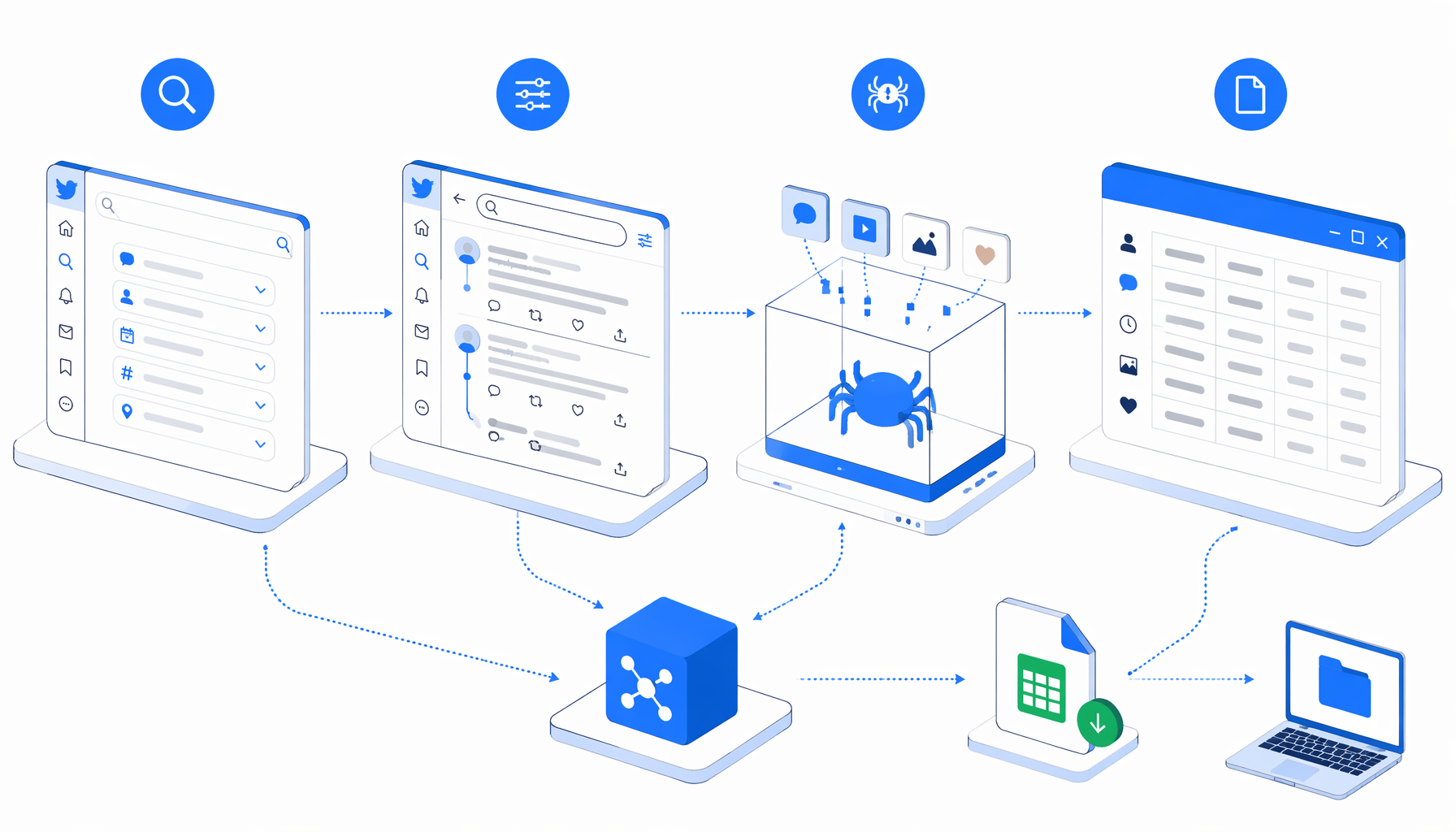
This tutorial shows how to scrape Twitter comments from selected X/Twitter advanced-search results into a CSV. You will use advanced search to find relevant posts, import the Twitter Advanced Search Comments Scraper template, replace the sample conversation URLs, set the export path, and validate the output.
Scope
Prerequisites before you scrape Twitter comments
Use this workflow for a finite list of posts, not broad crawling. You need UScraper as a local desktop app, an accessible X/Twitter browser session, conversation URLs copied from advanced search results, a CSV folder, and a clear review purpose such as campaign analysis, support triage, research, or open source intelligence notes.
Advanced search is the discovery step. Use X search filters such as keywords, exact phrases, accounts, hashtags, dates, language, or media filters to narrow the result set, then open the posts you are allowed to analyze and copy their direct URLs. The scraper template does not promise full X search coverage; it exports replies from conversations that your browser can actually load.
Workflow
How the Twitter advanced search comments scraper works
The companion template page is the download path; this article is the operating guide. Import the current Twitter Advanced Search Comments Scraper instead of rebuilding the graph by hand. The exported JSON workflow is the authoritative sample of the automation definition, while the summary below explains the extraction intent.
| Stage | What it does | What to check |
|---|---|---|
| Navigate | Opens each configured X/Twitter conversation URL | Replace the sample URL list with approved /status/ links from advanced search. |
| Wait for tweet article | Confirms the page rendered at least one tweet card | Empty runs usually mean login, access, or load-state friction. |
| Read replies branch | Clicks the visible reply-expander control when present | Some conversations expose this control; others load replies directly. |
| Scroll and collect | Runs repeated wait, scroll, and JavaScript collection cycles | Increase cycles only after one URL validates cleanly. |
| Hidden cache | Stores loaded tweet articles before page virtualization removes them | This protects rows that briefly appeared during infinite scroll. |
| Structured Export | Writes parent post and comment fields to CSV | Confirm headers, filename, save folder, and append mode. |
{
"project": {
"name": "Twitter Advanced Search Comments Scraper",
"description": "Best-effort X/Twitter advanced-search/comment scraper."
},
"blocks": [
{
"title": "Navigate",
"config": {
"urls": ["https://x.com/BBCNewsnight/status/1907187972686115037"]
}
},
{
"title": "Wait for Element",
"config": {
"selector": "article[data-testid='tweet']",
"timeout": 45
}
},
{
"title": "Structured Export",
"config": {
"rowSelector": "#uscraper-x-tweet-cache article[data-testid='tweet']",
"fileName": "twitter-advanced-search-comments-scraper.csv",
"includeHeaders": true,
"fileMode": "append"
}
}
]
}
The template is best-effort because X can change page markup, reply visibility, login requirements, and infinite-scroll behavior. The reliable practice is to validate one conversation URL, then expand gradually.
Runbook
Step-by-step: export Twitter replies to CSV
Import the template
Open the template page from the templates library and import the JSON workflow into UScraper.
Build the search
Use X/Twitter advanced search to narrow posts by keyword, account, hashtag, date window, language, or media type. Save the search string in your notes so the CSV can be traced back to the source query.
Copy conversation URLs
Open only the result posts you are allowed to review and copy their direct /status/ URLs. Deduplicate the list before pasting it into navigate.urls.
Set the export folder
In Structured Export, choose where twitter-advanced-search-comments-scraper.csv should be saved. Keep test files separate from client, campaign, or research batches.
Run one validation URL
Start with one conversation that visibly has replies. Let UScraper wait, click the reply control if available, scroll through six collection cycles, and export the cached rows.
Review and scale slowly
Open the CSV, compare source URLs and visible replies against the page, remove bad rows, then add more URLs only when the first run matches what the browser showed.
Output
Validate the CSV before analysis
The export keeps parent tweet fields beside each cached comment row. That makes the file easy to group by source conversation, sort by engagement, filter by author, or hand to a reviewer without losing where each reply came from.
| Field group | Example columns |
|---|---|
| Source context | query_str, source_page_url, post_url, post_id |
| Parent tweet | tweet_author, tweet_author_handle, posted_utc_time, tweet_text, tweet_image_url |
| Parent engagement | tweet_replies, tweet_retweets, tweet_likes, tweet_views |
| Comment fields | comment_url, comment_author_name, comment_author_handle, comment_timestamp, comment_content |
| Comment metadata | comment_image_url, comment_likes, comment_retweets, comment_replies, replying_to, language |
After the first run, check three things. First, every row should have a source page URL or comment URL that opens in the same browser session. Second, parent tweet fields should repeat consistently for rows from the same conversation. Third, blank engagement cells should be treated as missing display data, not as zero, because X may hide or delay counts.
Tool choice
When this is the best Twitter comments scraper approach
Use UScraper when the job is bounded: selected advanced-search results, supervised export, local CSV custody, and a reviewer who wants a visual workflow instead of a custom script. It is a strong twitter comments scraper alternative when analysts need a spreadsheet before they need a data platform.
Troubleshooting
Common issues and FAQs
X/Twitter content may be visible in a browser, but automated collection can still be limited by platform terms, login rules, copyright, privacy law, and local regulations. Use approved access, avoid bypassing controls, keep batches narrow, and get legal review before commercial use, redistribution, enrichment, or model training.
Next step
Download the workflow and run a short batch
Start with the Twitter Advanced Search Comments Scraper template, keep your first run to one or two posts, and document the search query, URL list, account state, run time, and CSV path. For adjacent workflows, browse the UScraper templates library or read more tutorials from the blog.