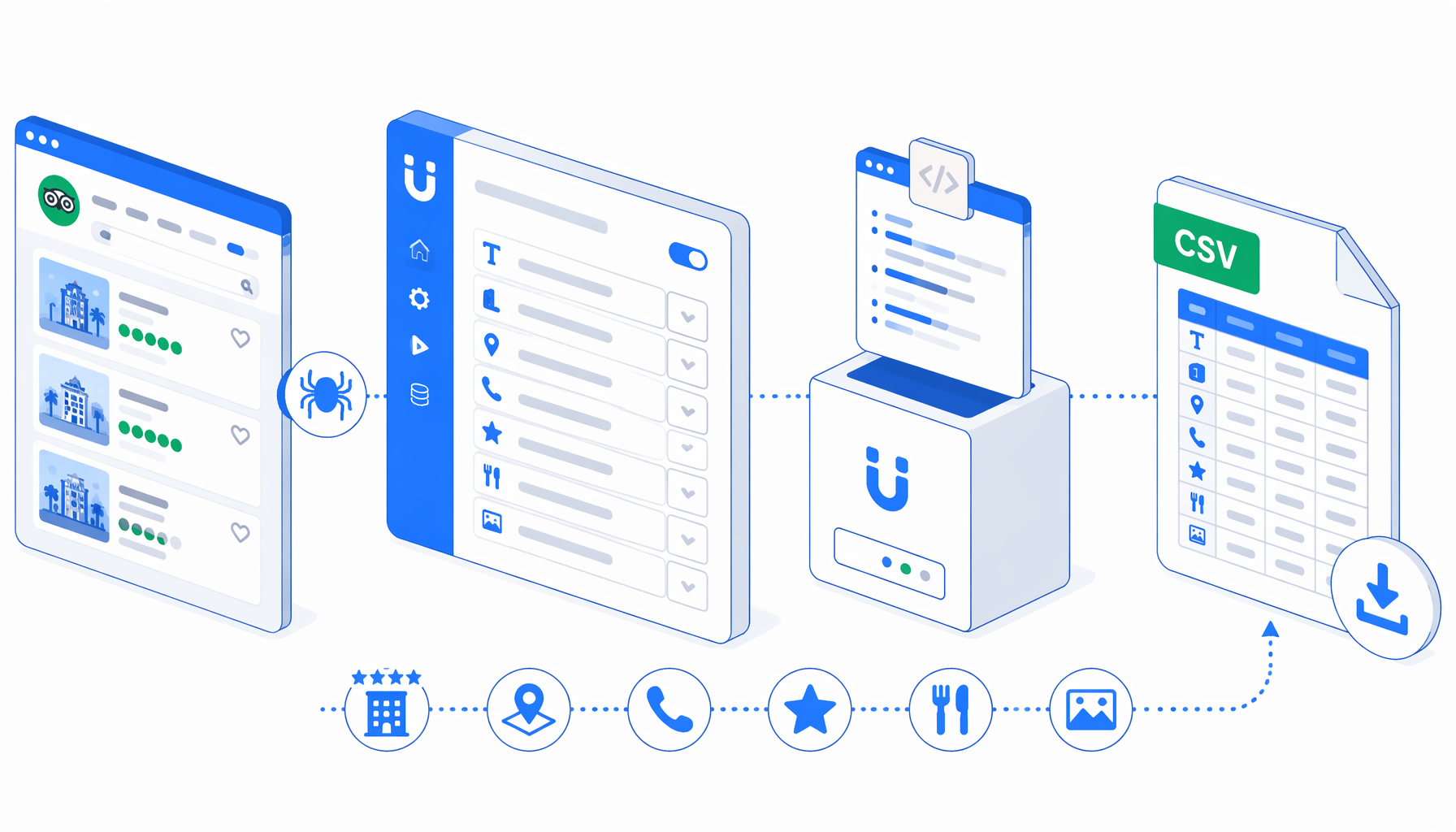
This tutorial shows how to scrape Tripadvisor hotels from approved Hotel_Review URLs into CSV with the Tripadvisor Hotel Details Scraper template for UScraper. You will import the workflow, replace the sample hotel URL, set the export path, run a small batch, and validate the hotel-detail rows.
Before you start
Prerequisites for scraping Tripadvisor hotel details
You need UScraper installed as a local desktop app, the Tripadvisor Hotel Details Scraper template, a folder for CSV exports, and one or more Tripadvisor hotel detail pages you are allowed to process. Use direct Hotel_Review URLs, not broad destination search pages.
Start with one hotel. Tripadvisor can vary content by region, language, consent state, login state, and bot-protection response, so the first run should be watched in the browser before you trust the CSV.
This guide is for supervised research exports. Review Tripadvisor's robots.txt, public terms, and the official Tripadvisor Content API when you need sanctioned access or commercial reuse.
Technical access is not permission. Collect only fields you need, keep pacing conservative, avoid bypassing verification or access controls, and stop when the browser shows limited or blocked content.
Choose the path
Tripadvisor Content API alternative, Python scraper, or UScraper?
Searches like tripadvisor content api alternative, tripadvisor scraper python, and best Tripadvisor scraping tools often hide different jobs. Pick the route based on who will maintain the workflow and what permission model you need.
| Approach | Best fit | Main trade-off |
|---|---|---|
| Official Tripadvisor Content API | Qualified travel websites, approved integrations, licensed reuse | Requires eligible access and API integration work. |
| Python or Playwright scraper | Engineering-owned pipelines with custom storage and monitoring | Flexible, but you maintain selectors, sessions, retries, compliance checks, and exports. |
| Hosted scraping tools | Cloud jobs, APIs, queues, and managed infrastructure | Vendor custody, pricing units, proxy behavior, and limits depend on the platform. |
| UScraper template | Analyst-led hotel detail exports to a local CSV | Visible and editable, but still affected by page layout, consent state, and access responses. |
Use the official API when your project needs approved Tripadvisor data access, predictable licensing, or partner terms. The Location Details endpoint is the right concept to review for structured place details.
Workflow
How the Tripadvisor hotel details scraper works
The JSON export is the authoritative workflow definition. In plain English, the flow is:
Set Window Size -> Navigate -> Wait for Page Load -> Wait for body
-> Sleep -> Click visible consent/show-all controls -> Scroll reveal
-> Sleep -> Structured Export -> Loop Continue
The Navigate block holds one or many hotel URLs. For each URL, the workflow waits for the page to settle, runs a small JavaScript interaction step, then uses Structured Export against the page body. The extraction columns use browser JavaScript fallbacks from visible text, metadata, JSON-LD, script content, full HTML, and URL parsing.
| Workflow area | Blocks involved | What to check |
|---|---|---|
| Input | Set Window Size, Navigate | Replace the sample hotel URL with approved Hotel_Review pages. |
| Page load | Wait for Page Load, Wait for Element, Sleep | Confirm the hotel page rendered before export. |
| Interaction | Inject JavaScript | Handles common consent, show-all, read-more, and scroll-reveal controls. |
| Export | Structured Export | Writes the configured columns into a local CSV with headers. |
| Batch loop | Loop Continue | Advances to the next URL so one file can hold many hotel rows. |
Runbook
How to scrape Tripadvisor hotel data to CSV
Import the template
Open Tripadvisor Hotel Details Scraper, download the JSON, and import it into UScraper.
Add hotel URLs
Open the Navigate block and replace the sample Moxy NYC Times Square URL with the Tripadvisor hotel pages you are permitted to process.
Set the export folder
Open Structured Export, set the save location to your project folder, keep headers enabled, and leave append mode on when you want one combined CSV.
Run one hotel first
Run a single URL while watching the browser. Confirm the page loads normally and stop if Tripadvisor serves verification, blocked content, or a login wall.
Validate and batch
Open the CSV, compare the first row with the live page, then add more hotel URLs only after names, rankings, amenities, ratings, and image URLs look correct.
Append mode is useful for batches, but it can also preserve test rows. Before a production run, either clear the existing CSV or change the filename to include a destination and date.
Export shape
CSV fields from the Tripadvisor hotel details scraper
No bundled CSV sample is required for this workflow because the JSON export defines the output shape. The stock file name is tripadvisor-scraper-hotel-details.csv, and each accessible hotel page appends one detail row.
| Field group | CSV columns | Validation check |
|---|---|---|
| Source and identity | web_page_url, hotel_name, current_time | Confirm the final URL and hotel name match the page. |
| Reputation | number_of_reviews, ranking, star_rating | Compare the visible review count and ranking text. |
| Location and contact | location, phone_number | Check address formatting and country-specific phone formats. |
| Hotel features | property_amenities, room_features | Blank cells often mean the section did not render or was collapsed differently. |
| Rating breakdown | location_rating, cleanliness_rating, service_rating, value_rating | Spot-check against visible rating labels when they appear. |
| Nearby and media | great_for_walkers, number_of_restaurants, number_of_attractions, image_1, image_2, image_3 | Verify image URLs and nearby counts before using them in reports. |
tripadvisor-scraper-hotel-details.csvColumn
web_page_url
Final Tripadvisor URL opened by the browser.
Column
hotel_name
Hotel name from H1, metadata, fallback mapping, or URL slug.
Column
number_of_reviews
Visible review count when Tripadvisor exposes it.
Column
ranking
Ranking text such as #47 of 498 hotels.
Column
location
Address from structured data or visible page text.
Column
phone_number
Telephone link or phone pattern from page text.
Column
property_amenities
Amenities section after available expand controls run.
Column
room_features
Room feature labels such as air conditioning or flatscreen TV.
Column
star_rating
Overall rating value when exposed in structured data or labels.
Column
image_1
First Tripadvisor CDN image URL detected on the page.
Troubleshooting
Common issues when scraping Tripadvisor hotels
Tripadvisor may hide those sections by region, language, consent state, or page variant. Open the URL manually in the same browser context and confirm the section appears before changing selectors.
Next steps
Download the template and keep the workflow auditable
Use the Tripadvisor Hotel Details Scraper template as the download and import path, then browse the full UScraper template library for companion hotel, restaurant, maps, and travel workflows. For more workflow guides, the UScraper blog collects tutorials and comparisons around local scraping, CSV exports, and no-code automation.
For production research, keep a simple audit trail: source URL list, run date, export filename, validation notes, and any URLs that returned limited content. That record makes the CSV easier to defend later than a one-off spreadsheet with no context.