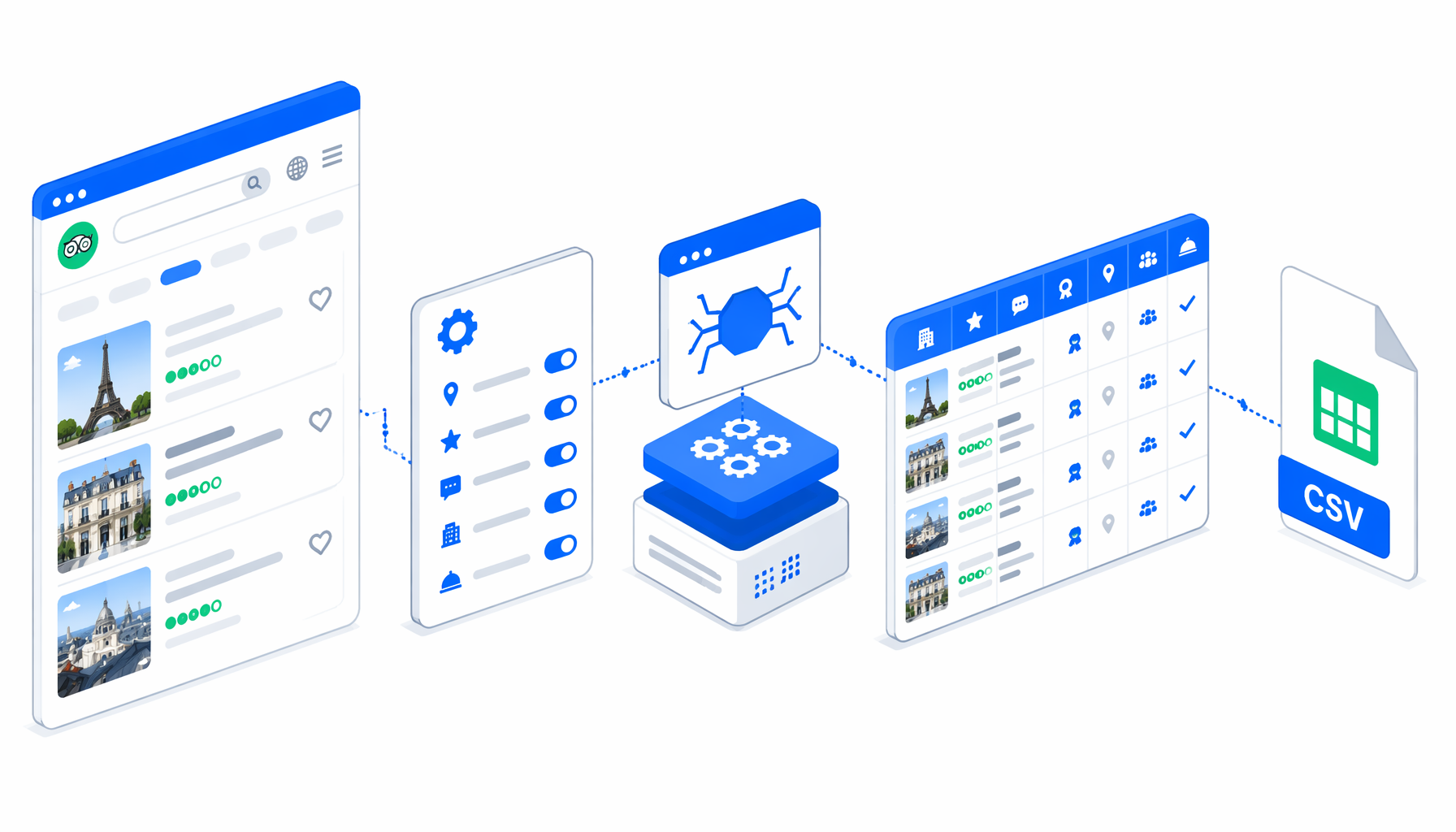
This Tripadvisor France scraper tutorial shows how to turn prepared hotel detail URLs into a local CSV with the Tripadvisor Scraper for France template for UScraper. You will import the workflow, replace sample URLs, choose an export folder, run one visible test, and validate the hotel data before scaling.
Before you start
Prerequisites for a Tripadvisor France scraper
You need the UScraper local desktop app, the free JSON template, a folder for the CSV, and a short list of Tripadvisor hotel review URLs your team is allowed to process. Start with three to five URLs, not a destination-wide crawl. Tripadvisor pages can vary by country domain, language, consent state, page layout, and access response, so a small first run is easier to audit.
This guide is for hotel detail enrichment from known pages. It does not search all of France, collect private account data, bypass verification, or guarantee that every hotel exposes every field. If your project is a public travel product, partner integration, or large redistribution workflow, review Tripadvisor's Terms of Use, current robots.txt, and official Content API route before running automation.
Technical access is not permission. Use approved URLs, collect only the fields you need, and stop when the browser shows a challenge page.
Workflow
How the workflow exports Tripadvisor hotel data
The JSON export is the authoritative workflow definition. In plain English, it follows this sequence:
Set Window Size -> Navigate URL list -> Wait for Page Load
-> Wait for Element -> Inject JavaScript -> Sleep
-> Structured Export -> Loop Continue
Navigate stores the hotel URLs. The wait blocks give the page time to render. Inject JavaScript accepts common visible consent prompts, checks whether the browser appears blocked, reads structured data and visible text, and builds helper functions under window.__usTA. Structured Export writes the configured columns. Loop Continue advances to the next URL.
| Block | Purpose | What to check |
|---|---|---|
| Set Window Size | Uses a stable large viewport | Keep it unless content hides in your environment. |
| Navigate | Holds the input hotel URLs | Replace every sample URL with approved Tripadvisor pages. |
| Wait blocks | Let content, prompts, or challenges appear | Increase cautiously after watching a slow page. |
| Inject JavaScript | Reads page text, JSON-LD, URL patterns, and known fallbacks | Re-test if Tripadvisor changes layout or French labels. |
| Structured Export | Appends one CSV row per page | Confirm filename, folder, headers, and append mode. |
| Loop Continue | Moves through the URL list | Keep it after export so every URL has a chance to write. |
The bundled JSON notes that live testing encountered Tripadvisor/DataDome CAPTCHA pages. That is why the workflow includes normal extraction plus URL-derived and sample fallbacks. Treat fallback rows as debugging scaffolding, not verified hotel records.
Runbook
How to scrape Tripadvisor France hotel data to CSV
Import the template
Open Tripadvisor Scraper for France, download the JSON workflow, and import it into UScraper.
Replace sample URLs
In Navigate, paste the Tripadvisor hotel review pages you are permitted to process. Keep the French domain when your report depends on French labels.
Set the export folder
In Structured Export, keep tripadvisor-scraper-for-france.csv, headers enabled, and append mode. Change the save folder for each client, city, or research batch.
Run one hotel first
Run a single URL with the browser visible. Confirm you see a normal hotel page, not a consent wall, login prompt, CAPTCHA, or blocked shell.
Validate, then batch
Compare the first row against the live page. Only widen the URL list after hotel name, rating, reviews, ranking, address, nearby counts, and services look sane.
Append mode is useful for multi-URL work, but it also means reruns add duplicate rows. Use a dated filename or clear test rows before your production batch.
Output
CSV output and validation checks
No final CSV sample was bundled with this template, so use the export shape summary and the JSON definition together. The summary explains the extraction intent; the JSON is the source of truth for block order, file name, save mode, JavaScript expressions, and column names.
tripadvisor-scraper-for-france.csvColumn
hotel_page_url
The final Tripadvisor hotel URL opened by the browser.
Column
nom_du_hotel
Hotel name from the page, structured data, fallback mapping, or URL slug.
Column
notation
Overall rating value when exposed on the page.
Column
nombre_d_avis
Visible review count, such as 1 288 avis.
Column
ranking
Hotel ranking text in the destination.
Column
adresse
Address from structured data or visible page text.
Column
services
Amenities and services joined into a multiline cell.
Sample rows
1 of many
| hotel_page_url | nom_du_hotel | notation | nombre_d_avis | ranking | adresse | services |
|---|---|---|---|---|---|---|
| THE OMNIA | 5 | 1 288 avis | Nº 1 sur 107 hôtels à Zermatt | Auf dem Fels, Zermatt 3920 Suisse | Wi-Fi, piscine, spa, restaurant |
| Symptom | Likely cause | Fix |
|---|---|---|
| Name and URL only | The page was blocked or fallback extraction was used | Mark the row for review and do not treat it as confirmed live data. |
| Blank services | Services were hidden, localized differently, or absent | Inspect the page and update the expansion or selector logic only if permitted. |
| Rating mismatch | Locale text or markup changed | Compare against the visible rating module before trusting aggregates. |
| Duplicate rows | The same URL was supplied twice or the workflow was rerun | Deduplicate by hotel_page_url before analysis. |
| Missing nearby counts | The page did not expose nearby modules | Treat those columns as optional enrichment fields. |
Tool choice
Tripadvisor scraper vs API, Octoparse, and hosted tools
People searching for tripadvisor scraper vs api, octoparse Tripadvisor alternative, or how to scrape hotel listings are usually comparing different operating models. The official Content API is the right route when you need approved partner access, stable schemas, or contractual reuse. Hosted scraper actors and no-code cloud platforms can fit scheduled jobs, managed infrastructure, and API delivery.
UScraper is narrower and more inspectable: it is useful when an analyst already has a controlled list of hotel URLs and needs a supervised CSV from a local desktop app. You can watch the browser, edit blocks, change the export folder, run a short batch, and keep the output local unless you add your own upload step.
| Option | Better fit | Trade-off |
|---|---|---|
| Tripadvisor Content API | Partner applications and licensed content workflows | Requires the official access path and product integration work. |
| Hosted scraper tools | Scheduled cloud jobs, datasets, APIs, and managed retries | Data custody, pricing, and behavior depend on the vendor. |
| Python or Selenium scripts | Engineering teams that want versioned scraping code | You own rendering, selectors, retries, and maintenance. |
| UScraper template | Modest, auditable hotel exports from prepared URLs | Best for supervised batches, not unattended large-scale crawling. |
For adjacent workflows, browse the UScraper template library or related tutorials in the UScraper blog.
FAQ
Frequently asked questions
Tripadvisor pages can be publicly viewable, but automated extraction may still be restricted by Tripadvisor terms, robots directives, copyright, privacy law, contract rules, and local regulations. Use only URLs you are allowed to access, keep runs modest, avoid bypassing verification, and get legal review before commercial reuse or redistribution.