This tutorial shows how to scrape Tripadvisor restaurant data from detail pages into CSV with the Tripadvisor Restaurant Scraper for Detail Pages template for UScraper. You will import the workflow, replace the sample URLs, set the export path, validate contact and hours fields, and understand when official or hosted options are a better fit.
Before you start
Prerequisites for a Tripadvisor restaurant scraper tutorial
You need UScraper installed as a local desktop app, the Tripadvisor Restaurant Scraper for Detail Pages template, a folder for CSV exports, and restaurant detail URLs you are allowed to process. Start with five to ten URLs instead of a large city list. The first run is for QA, not production volume.
This guide is for visible restaurant detail pages. It is not a CAPTCHA bypass guide, login automation guide, or advice to ignore publisher terms. Review Tripadvisor's current Terms of Use, robots.txt, the Tripadvisor Content API documentation, privacy rules, and your intended reuse before running a scraper.
Technical access is not the same thing as permission. Keep batches modest, stop when verification appears, and use official access paths when you need stable rights for production applications or redistributed datasets.
Workflow anatomy
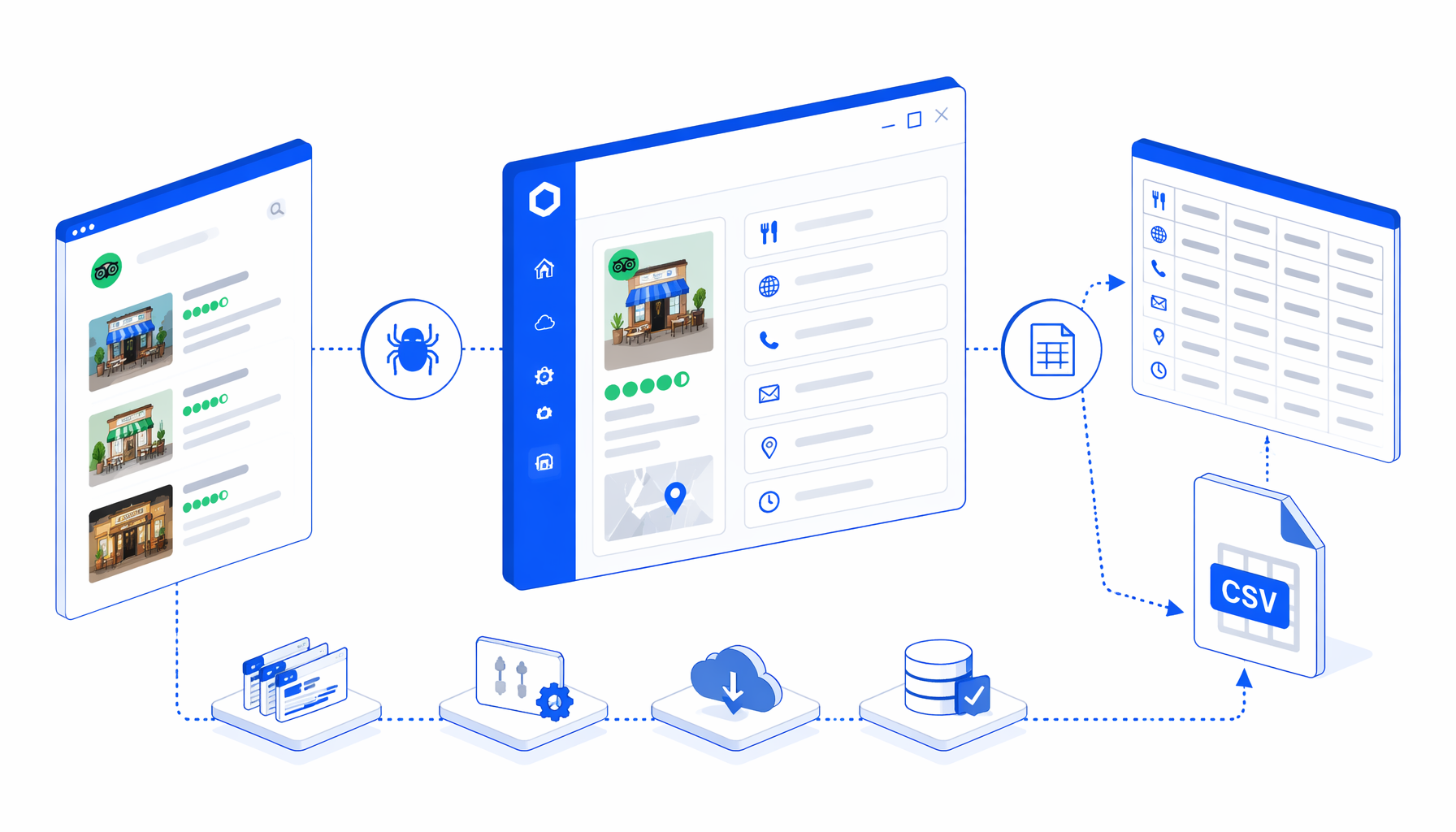
What the Tripadvisor restaurant detail workflow does
The JSON export is the authoritative workflow definition. In plain English, the flow is:
Navigate URL list -> Wait for Page Load -> Wait for body
-> CAPTCHA check -> optional short pause -> JavaScript extraction
-> Structured Export -> Loop Continue
Navigate stores the restaurant detail URLs. The wait blocks give each page time to render. The CAPTCHA condition looks for challenge iframes or scripts and routes the flow through a short pause when they appear. The JavaScript extraction block reads JSON-LD first, then falls back to visible page elements and known sample-preview values when available. Structured Export writes the normalized fields to CSV with headers and append mode enabled. Loop Continue advances to the next URL.
| Block | Purpose | Validation check |
|---|---|---|
| Navigate | Holds the Tripadvisor restaurant URLs | Replace the bundled Berlin samples with your approved list. |
| Wait blocks | Stabilize dynamic pages before extraction | Increase waits only after confirming pages are genuinely slow. |
| CAPTCHA check | Detects challenge markup | Pause or stop when verification appears; do not automate around it. |
| JavaScript extraction | Normalizes title, website, phone, email, address, and hours | Inspect one live page and one CSV row side by side. |
| Structured Export | Appends rows to CSV | Confirm filename, save folder, headers, and append mode. |
Runbook
How to scrape Tripadvisor restaurant details to CSV
Import the template
Open Tripadvisor Restaurant Scraper for Detail Pages, download the JSON, and import it into UScraper.
Replace the URL list
Open the Navigate block and paste your approved Tripadvisor restaurant detail URLs. Keep the source URLs intact so every CSV row can be traced back to the page that produced it.
Set the export path
Structured Export writes tripadvisor-restaurant-scraper-detail.csv. Change the save location to your project folder before client, audit, or recurring research runs.
Run a short validation batch
Process five to ten pages while watching the browser. Stop if Tripadvisor shows CAPTCHA, access challenges, blank pages, or repeated HTTP errors.
Compare rows to pages
Open the CSV and verify restaurant title, website, phone, email, address, and hours against the loaded page before you scale the run.
Because file mode is append, reruns add rows to the same file. For repeatable research, use a dated filename or clear the test file before running the same URL set again.
Output
Tripadvisor restaurant scraper CSV columns
The workflow exports one row per accessible restaurant detail URL. The column names follow the current template JSON, including French labels for title, address, and weekdays.
tripadvisor-restaurant-scraper-detail.csvColumn
URL_original
The Tripadvisor restaurant detail URL opened during the loop.
Column
Titre
Restaurant title from JSON-LD, page heading, or fallback extraction.
Column
Website
Official restaurant website when an outbound link is visible.
Column
Phone
Primary phone number from structured data or tel links.
Column
Email address when a mailto link or known preview value is available.
Column
Adresse
Street address and locality as available on the page.
Column
Dimanche
Sunday opening hours.
Column
Lundi
Monday opening hours.
Column
Mardi
Tuesday opening hours.
Column
Mercredi
Wednesday opening hours.
Column
Jeudi
Thursday opening hours.
Column
Vendredi
Friday opening hours.
Column
Samedi
Saturday opening hours.
For validation, sort the CSV by URL_original, then open three source links: the first row, a middle row, and the last row. Confirm the restaurant title, outbound website, phone, address, and hours. Treat missing email as common, not automatically wrong; many restaurant pages simply do not expose a public email.
Tool choices
UScraper vs Octoparse, Web Scraper, Apify, and code
There are several best Tripadvisor scraper tools depending on how you want to operate. Octoparse has a Tripadvisor restaurant detail template, Web Scraper has a marketplace scraper for restaurant pages, Apify offers hosted Tripadvisor actors, and Python guides from scraping vendors show how engineers can build custom parsers. Those are useful references, but the trade-off is usually ownership of the run.
| Approach | Good fit | Trade-off |
|---|---|---|
| UScraper local desktop app | Analysts who want a no-code CSV workflow from known URLs | You maintain selectors and supervise access challenges. |
| Hosted actors | Teams that prefer managed infrastructure and dashboards | Data and execution typically run through a hosted platform. |
| Browser-extension or cloud templates | One-off no-code extraction experiments | Template fields may differ from the CSV shape you need. |
| Python scraper | Engineers building a tested pipeline | Highest maintenance cost when markup or anti-bot behavior changes. |
| Official API or partner route | Production apps, licensing clarity, stable contracts | Requires eligibility, terms review, and an API integration path. |
For a simple Octoparse Tripadvisor scraper alternative, use UScraper when your input is already a list of restaurant pages and your goal is a local CSV containing contact fields and hours. Use hosted or official options when procurement, scale, or redistribution rights matter more than local spreadsheet custody.
Troubleshooting
Common Tripadvisor scraping issues
Blank cells usually mean the restaurant does not publish that field, the page returned a challenge, lazy content did not finish loading, or the DOM changed. Re-run one URL with the browser visible before changing every selector.
Next step
Download the Tripadvisor restaurant pages scraper workflow
Use this article as the runbook and the template page as the download path. Import the current JSON from Tripadvisor Restaurant Scraper for Detail Pages, run a small validation batch, and keep the template library bookmarked for adjacent restaurant, hotel, and map-based workflows. For more tutorials and comparisons, browse the UScraper blog.