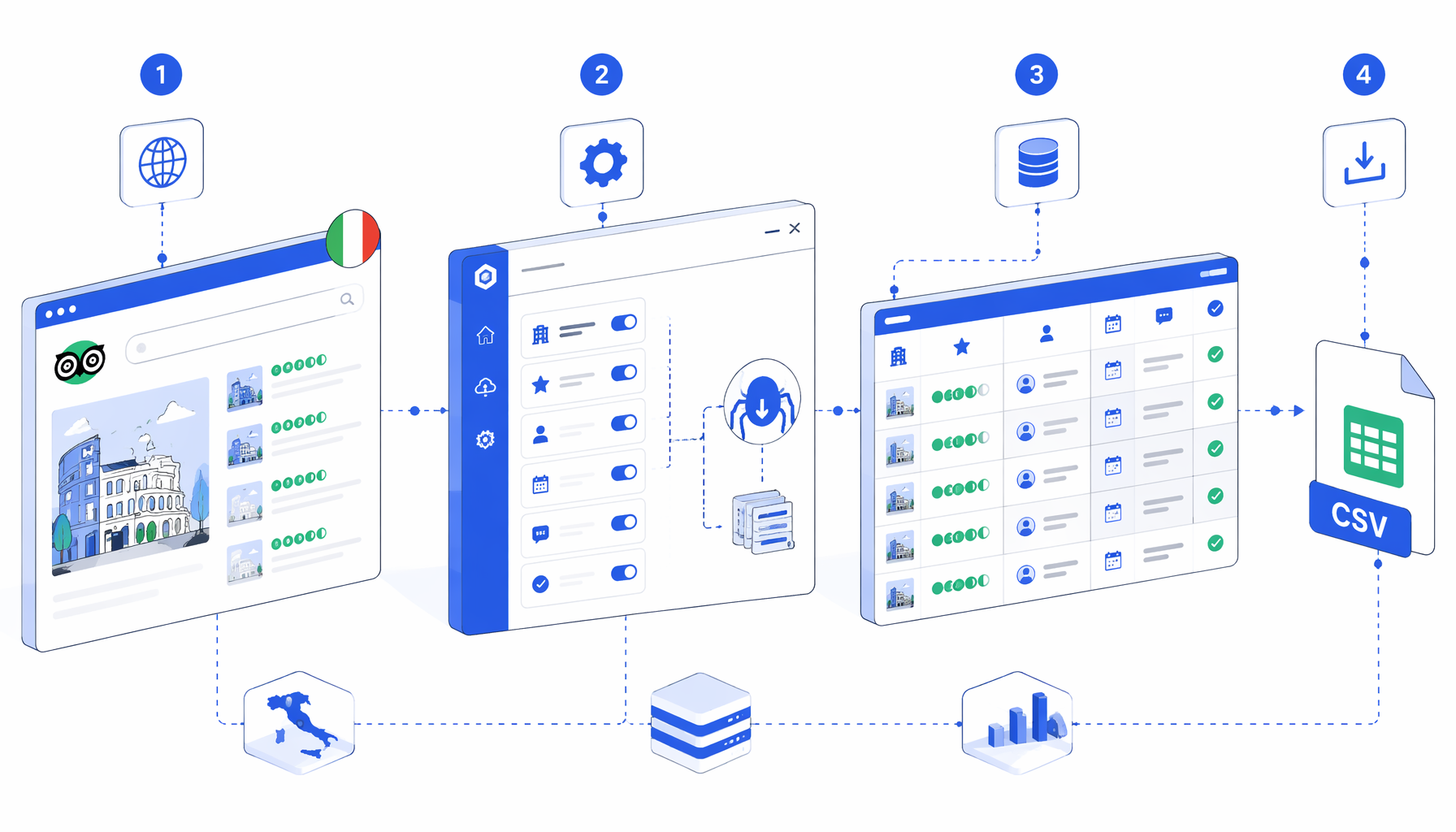
This tutorial shows how to scrape Tripadvisor reviews from Italian hotel review pages into CSV with UScraper. You will import the workflow, replace the sample Tripadvisor.it URLs, confirm the export path, run one hotel first, and validate review rows before scaling.
Before you start
Prerequisites for a Tripadvisor hotel review scraper
You need UScraper installed as a local desktop app, a folder for the CSV export, and one or more Tripadvisor.it hotel review URLs that your team is allowed to process. Use the Tripadvisor Hotel Review Scraper for Italy template as the download path; it contains the maintained JSON workflow, selectors, waits, pagination loop, and diagnostic export branch.
This tutorial is for controlled research from pages you can inspect in a normal browser. It is not a guide to bypass CAPTCHA, DataDome, 403 pages, sign-in walls, account areas, payment flows, private dashboards, or technical access controls.
Review Tripadvisor's current Terms of Use, robots.txt, and any internal legal or data policy before automation. If you need a contracted feed for a product, review Tripadvisor's Content API overview and API terms instead of treating a browser export as a redistribution license.
Technical access is not permission. Keep batches modest, collect only the fields you need, stop when access challenges appear, and get legal review before commercial reuse.
Workflow anatomy
What the Tripadvisor Italy review workflow does
The JSON export is the authoritative workflow definition. In plain English, the template does four jobs: load each input URL, wait for Tripadvisor's dynamic page state, export review rows when cards are visible, and write a diagnostic row when review cards are not visible.
Navigate URL list -> Wait for Page Load -> Wait for body -> Sleep
-> Review-card guard -> Expand "read more" text -> Structured Export
-> Next-page check -> Optional pagination click -> Loop Continue
The fallback branch matters. Many Tripadvisor scraping tutorials show the happy path only: fetch HTML, parse review cards, write CSV. Real review exports also need to handle blocked pages, consent variants, locale changes, and layout drift. This template writes a row with blocked_datadome_or_403 or no_review_cards_visible instead of hiding the failure.
| Workflow block | Purpose | Validation check |
|---|---|---|
| Navigate | Stores multiple Tripadvisor.it review URLs | Replace samples with approved hotel review links. |
| Wait blocks | Gives dynamic content time to render | Keep them for the first run; tune only after QA. |
| Review-card guard | Checks common Tripadvisor review containers | If false, the diagnostic branch runs. |
| Inject JavaScript | Clicks visible "altro", "leggi di più", "leggi tutto", "more", or "read more" controls | Confirm full review text is visible before export. |
| Structured Export | Writes one row per visible review card | Verify filename, folder, headers, and append mode. |
| Pagination check | Looks for Italian or English next-page links | Stop when the next link disappears or is disabled. |
Runbook
How to scrape Tripadvisor reviews to CSV
Import the workflow
Open the Tripadvisor Hotel Review Scraper for Italy template page, download the JSON file, and import it into UScraper.
Replace the URL list
In Navigate, replace the sample Decumani Hotel URLs with approved Tripadvisor.it ShowUserReviews hotel review URLs. Keep the full URL because the path can carry hotel, location, and review context.
Keep waits and guards
Leave the page-load wait, body wait, manual challenge window, review-card guard, review-expansion JavaScript, pagination check, and blocked-page export branch in place for the first run.
Confirm the CSV destination
Structured Export writes crawler-recensioni-hotel-tripadvisor.csv with headers enabled and append mode on. Change the save folder to your project directory before client or research runs.
Run one hotel first
Watch the browser while the first URL loads. If Tripadvisor shows CAPTCHA, DataDome, a 403 interstitial, or no visible review cards, stop and inspect the diagnostic row instead of adding more URLs.
Validate, then scale gradually
Compare the CSV against the browser for hotel name, reviewer, rating, review date, stay date, title, content, helpful votes, and extraction status. Add more hotels only after the first sample is clean.
Because the file mode is append, rerunning the same URL can duplicate rows. For repeatable Tripadvisor hotel review research, use a dated filename, clear test rows before a clean run, or keep separate CSVs for test, production, and rerun batches.
Output
CSV fields for Italian hotel reviews
The workflow exports Italian column names because the bundle is built around Tripadvisor.it hotel review URLs. Page-level hotel fields repeat on each row so you can group reviews by property after combining several hotels.
crawler-recensioni-hotel-tripadvisor.csvColumn
pagina_attuale
Final Tripadvisor.it URL opened in the browser.
Column
nome_hotel
Hotel name from the page heading, metadata, title, or URL fallback.
Column
recensioni_totali
Total hotel review count when visible.
Column
rating_hotel
Overall hotel rating when exposed by Tripadvisor.
Column
nome_utente
Reviewer display name from the card.
Column
indirizzo_utente
Reviewer location when shown.
Column
rating
Individual review rating.
Column
data_della_recensione
Review publication date.
Column
data_del_soggiorno
Guest stay period when present.
Column
titolo
Review title.
Column
contenuto
Expanded visible review body or blocked-page diagnostic.
Column
voto_utile
Helpful vote count when visible.
Column
stato_estrazione
ok_review_extracted, blocked_datadome_or_403, or no_review_cards_visible.
| Field group | Columns | Why it matters |
|---|---|---|
| Source audit | pagina_attuale, stato_estrazione | Proves which page produced the row and whether extraction succeeded. |
| Hotel context | nome_hotel, recensioni_totali, rating_hotel | Lets analysts group review rows by property. |
| Reviewer context | nome_utente, indirizzo_utente | Useful for QA and dedupe; handle personal data carefully. |
| Review content | rating, data_della_recensione, data_del_soggiorno, titolo, contenuto, voto_utile | Supports sentiment tagging, stay-period analysis, and reputation reporting. |
No CSV sample is bundled with the template. Make your first one-hotel run the sample for your market, browser state, and permissions.
Validation
Validate the Tripadvisor reviews CSV export
Open the CSV beside the browser and audit a few rows before you trust aggregates. Start with the first row, the last row, one row after pagination, and one row where a field is blank. If a row has ok_review_extracted, it should correspond to a visible review card. If it has a blocked status, it should explain why the page did not produce review rows.
| Symptom | Likely cause | Fix |
|---|---|---|
| Only diagnostic rows | Tripadvisor returned a CAPTCHA, DataDome page, 403 interstitial, or no visible review cards | Stop the run, document the status, and do not bypass access controls. |
| Hotel fields are present but review text is blank | Review cards changed, text stayed collapsed, or the selector no longer matches | Inspect one row in the browser, confirm text is visible, then update selectors if needed. |
| Duplicate reviews | Append mode plus a rerun of the same URL or pagination path | Clear test rows, dedupe by pagina_attuale, nome_utente, data_della_recensione, and titolo. |
| Pagination stops early | Next link is hidden, disabled, localized differently, or the page did not finish loading | Watch the browser, confirm the link label, and lengthen waits only after one manual inspection. |
| Mixed languages in dates or buttons | Tripadvisor served a locale variant | Keep the Italian and English expansion labels; add locale-specific labels only after seeing them. |
Alternatives
UScraper vs Python, APIs, and hosted Tripadvisor scrapers
If you searched for scrape Tripadvisor reviews Python, a code path can work: Playwright or Selenium for rendering, BeautifulSoup or DOM evaluation for parsing, custom pagination logic, retries, CSV writers, and ongoing selector maintenance. That gives engineering teams full control, but it also makes your team responsible for every wait, block state, layout change, and compliance decision.
Hosted marketplace scrapers and API-style vendors can be a better choice when you need managed infrastructure, high concurrency, scheduled refreshes, SLAs, or contracted data rights. A local desktop workflow fits a different job: analyst-led review export from known URLs, transparent blocks, local CSV custody, and quick selector edits without writing a new crawler.
| Approach | Best fit | Trade-off |
|---|---|---|
| UScraper template | Known Tripadvisor.it hotel review URLs and supervised CSV export | You still validate selectors, pacing, and platform permissions. |
| Python script | Engineering-owned crawler and custom transformations | You own rendering, pagination, retries, and maintenance. |
| Hosted scraper | Higher volume or managed browser infrastructure | Rows and execution move through a vendor platform. |
| Official or partner API | Product integration, licensing, and contractual certainty | Requires eligibility, terms, and implementation work. |
For related workflows, browse the UScraper template library or continue reading tutorials in the UScraper blog.
FAQ
Frequently asked questions
Tripadvisor review pages can be visible in a browser, but automated access and reuse may still be limited by Tripadvisor terms, robots directives, copyright, privacy law, and local contract rules. Use only URLs you are allowed to access, keep runs modest, do not bypass verification or access controls, and get legal review before commercial reuse.
Use the Tripadvisor Hotel Review Scraper for Italy template when you want the fastest path from approved Italian hotel review URLs to a local CSV, then keep the first run small enough to validate every field before scaling.