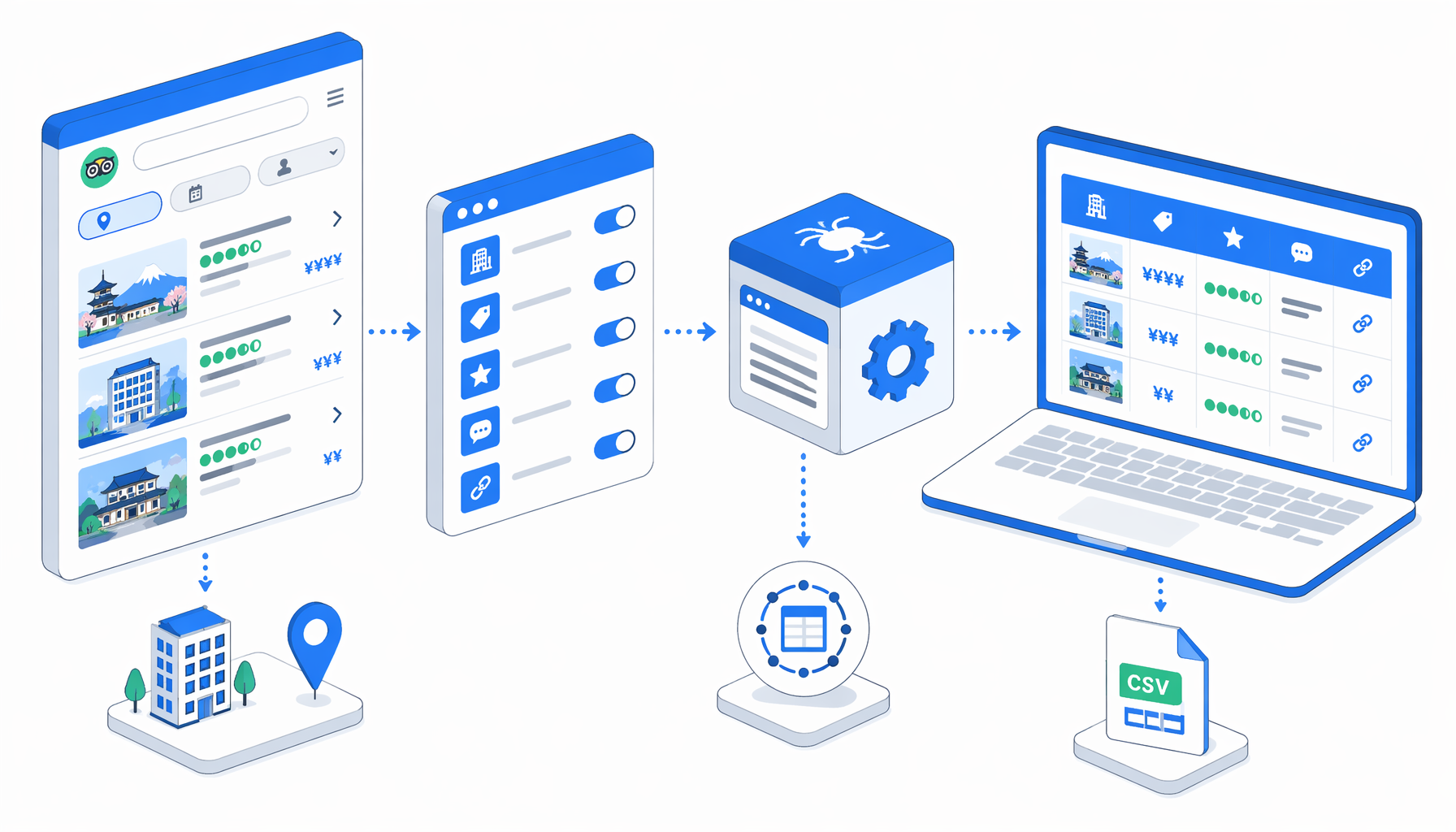
This Tripadvisor scraping tutorial shows how to scrape Tripadvisor Japan hotel listing data into CSV with the Tripadvisor Hotel Listings Scraper for Japan template for UScraper. You will import the workflow, add permitted hotel detail URLs, set the export path, run one visible test, and validate the rows before expanding the batch.
Before you start
Prerequisites, source pages, and policy checks
You need the UScraper local desktop app, the free JSON template, a short list of Tripadvisor hotel pages for Japan, and a folder where the CSV should be written. Start with one to three URLs because Tripadvisor hotel pages can vary by destination, language, cookies, availability modules, and challenge state.
The important scope detail: this template is named a Tripadvisor hotel listings scraper because it produces listing-style hotel rows, but it does not crawl every hotel from the official Tripadvisor Japan hotels listing page. The workflow opens the hotel detail URLs you provide, then appends one CSV row for each page.
Review Tripadvisor's current Terms of Use, check the live robots.txt, and consider the official Tripadvisor Content API or hotel Content API overview when your project needs sanctioned partner data or contractual reuse rights.
Compliance first: use pages you are allowed to access, keep runs modest, avoid bypassing verification, and document the research purpose before retaining or sharing hotel data.
Workflow anatomy
What the Tripadvisor hotel scraper for Japan does
The JSON export is the authoritative workflow definition. It uses a visible browser sequence shaped like Navigate -> Wait for Page Load -> Element Exists -> Sleep or body wait -> Structured Export -> Loop Continue. Navigate owns the hotel URL list, the wait blocks give Tripadvisor time to render, the challenge check looks for CAPTCHA delivery signals, and Structured Export appends one row to the CSV.
The export columns are JavaScript-backed because Tripadvisor can expose values through visible text, metadata, JSON-LD, page URLs, and localized labels. For the bundled Ishikawa sample URLs, the selectors first try live page content, then use URL-derived values or known preview fallbacks where the page is blocked.
| Block | Job in the workflow | What to inspect |
|---|---|---|
Navigate | Loops through supplied Hotel_Review URLs | Replace samples with permitted Japan hotel pages. |
Wait for Page Load | Allows the browser page to settle | Keep the 45-second wait for the first run. |
Element Exists | Checks for CAPTCHA delivery selectors | Use the result as an audit signal, not a bypass step. |
Structured Export | Writes one row from the current page | Confirm filename, save folder, headers, append mode, and columns. |
Loop Continue | Advances the multi-URL run | Keep it after export so each hotel can append once. |
tripadvisor-jp-hotel-listings-scraper.csvColumn
hotel_count
Destination or facility count context when visible or known from the sample page.
Column
hotel_name
Hotel name from live content, JSON-LD, metadata, H1, URL parsing, or known fallback.
Column
price
Visible yen price text when Tripadvisor renders one for the session.
Column
ranking
Combined ranking or bubble-rating text, including review-count context where available.
Column
rating
Numeric rating such as 5.0, 4.5, or 3.5 when exposed.
Column
review_count
Localized review-count text, for example Japanese review labels.
Column
amenities
Amenity labels or special offer text detected on the page.
Column
scraped_at
ISO timestamp generated during the local run.
Column
detail_page_url
The Tripadvisor hotel detail URL that produced the row.
Runbook
How to scrape Japan hotel listings from Tripadvisor
Import the template
Open Tripadvisor Hotel Listings Scraper for Japan, download the JSON, and import it into UScraper.
Add hotel detail URLs
Replace or extend the sample Ishikawa hotel URLs in Navigate with Tripadvisor Hotel_Review pages your team is permitted to process.
Confirm the export folder
In Structured Export, keep tripadvisor-jp-hotel-listings-scraper.csv, headers enabled, and append mode. Change the save folder for each client, region, or research batch.
Run one visible page
Run a single URL with the browser visible. Confirm the browser shows a normal hotel page, not a blocked response, consent prompt, or CAPTCHA shell.
Validate, then scale
Compare the CSV row with the page. Only add more URLs after hotel name, price, rating, review count, amenities, and detail URL make sense.
After the first run, sort the CSV by detail_page_url. Each input URL should produce one row. If you see duplicates, the same URL was supplied twice or the workflow was restarted after export had already appended data.
Validation
Validate the Tripadvisor hotels to CSV export
Treat validation as a required part of the workflow. Keep the source browser tab open beside the spreadsheet and inspect a row from the beginning, middle, and end of the run. This matters because hotel price, ranking text, special offers, and review modules can vary by session and page layout.
| Symptom | Likely cause | Fix |
|---|---|---|
Empty hotel_name | Tripadvisor did not render normal hotel content | Run visibly, handle permitted prompts, and retry one URL before changing selectors. |
| Mostly fallback values | The page matched a known sample or URL-derived fallback | Mark the row for manual review and do not treat it as confirmed live data. |
Blank price | No visible price rendered, page was blocked, or price markup changed | Verify the same URL manually and treat price as optional unless visible. |
Missing amenities | Labels were hidden, localized, moved, or absent | Add a scroll or selector update only after inspecting the rendered page. |
| Rating mismatch | Locale text or layout changed the parsing pattern | Compare against the visible rating module and update the JavaScript expression if needed. |
Tool choice
Tripadvisor API alternative, scripts, or local desktop app?
People searching for the best Tripadvisor scraper usually compare several different jobs. The official API path is best when you need approved access, stable contracts, and product integration. Developer tutorials from Apify, ScrapFly, Oxylabs, ScrapingBee, SerpApi, and ScrapeHero are useful when an engineering team wants to own code, proxies, retries, and parsers. Hosted actors and marketplace scrapers can be a fit when you want cloud scheduling and API datasets.
UScraper is narrower: it is a practical Tripadvisor API alternative when an analyst already has a controlled list of Japan hotel URLs and needs a supervised CSV on a local machine. You can inspect the browser, change the export path, adjust selectors, and keep the run small enough to audit.
| Option | Better fit | Trade-off |
|---|---|---|
| Tripadvisor Content API | Sanctioned partner content and public product integrations | Requires the official access path and is not a quick spreadsheet workflow. |
| Hosted scraper actors | Scheduled cloud jobs, datasets, API export | Rows and operations depend on the vendor platform. |
| Python or JavaScript scripts | Versioned engineering pipelines | You own rendering, maintenance, retries, and compliance review. |
| UScraper template | Supervised local CSV from prepared hotel URLs | Best for modest, auditable batches rather than unattended large-scale crawling. |
FAQ
Frequently asked questions
Tripadvisor hotel pages may be publicly visible, but automated collection can still be limited by Tripadvisor terms, robots directives, copyright, privacy law, and contract rules. Use only pages you are allowed to access, keep runs modest, do not bypass verification, and get legal review before commercial reuse.