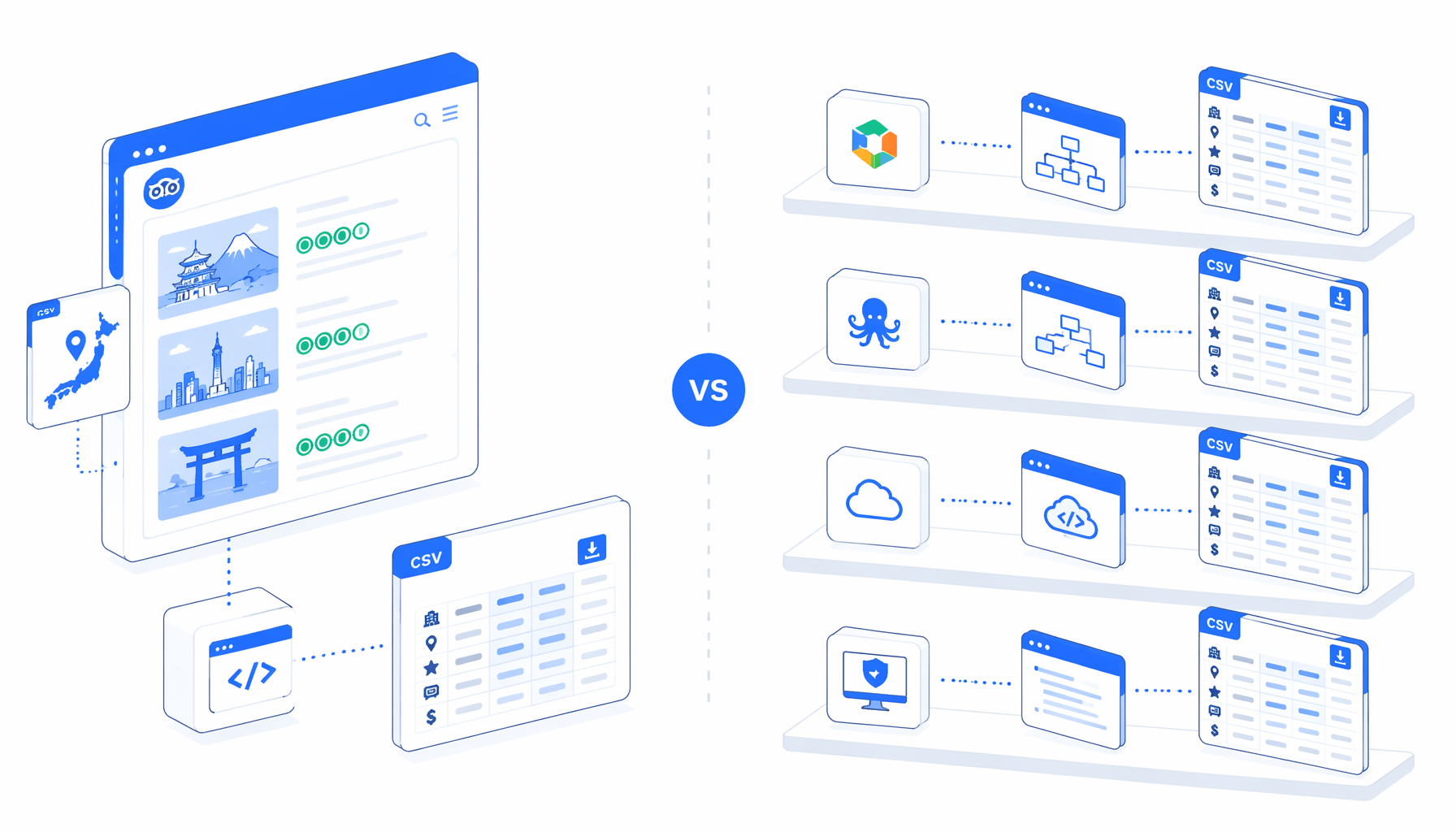
The best Tripadvisor hotel scraper for Japan is not a single tool category. It depends on whether you need sanctioned API access, a hosted actor, a no-code SaaS scraper, custom scripts, or a supervised local desktop app that exports CSV. This comparison looks at Octoparse, Apify, Web Scraper, Browse AI, Thunderbit, managed scraping providers, scripts, and UScraper's Tripadvisor Hotel Listings Scraper for Japan.
Comparison frame
What a Tripadvisor hotel scraper has to solve
Tripadvisor hotel data is awkward because "hotel listing" can mean several things. One tool may start from a destination listing page, follow pagination, and discover hotels. Another may open hotel detail pages directly. A third may extract reviews, images, amenities, or ranking metadata. Before comparing prices, decide whether your job is discovery, detail-page export, review collection, or approved content integration.
For Japan hotel research, the UScraper template is intentionally narrow. It opens supplied Tripadvisor Hotel_Review URLs, waits for the page, checks for challenge-page signals, and appends one row per hotel. It is a practical Tripadvisor API alternative for analysts who need an auditable CSV, not a replacement for official partner access.
The useful question is not "which scraper is strongest?" It is "which workflow gives my team data we can explain, maintain, and use legally?"
Side-by-side
Tripadvisor hotel scraper alternatives compared
| Option | Best fit | Hosting | Code needed | Output | Pricing shape | Main trade-off |
|---|---|---|---|---|---|---|
| Tripadvisor Content API | Approved travel websites, apps, and partner content | Tripadvisor API | Developer integration | API responses | Official access path | Best compliance route, but not a quick CSV workflow |
| Octoparse Tripadvisor hotel listing template | No-code teams starting from listing page URLs | Vendor cloud | Low | CSV/Excel-style exports | SaaS plan limits | Convenient visual setup, less local custody |
| Apify Tripadvisor actor | Hosted scraping jobs, API delivery, and datasets | Apify cloud | Low to medium | Dataset, JSON, CSV, API | Platform plus usage | Strong cloud automation, but run state lives in the platform |
| Apify hotel-focused actor | Hotels plus review-oriented travel data | Apify cloud | Low to medium | Dataset exports | Platform plus actor usage | Good fit for recurring hosted collection |
| Web Scraper marketplace sitemap | Teams comfortable with sitemap-based browser extraction | Browser/cloud workflow | Low to medium | Structured table export | Marketplace/tool pricing | Requires sitemap maintenance and page-flow understanding |
| Browse AI robot or Thunderbit template | Fast no-code table extraction | Vendor cloud/browser workflow | Low | Sheets, CSV, app exports | Subscription or credit model | Fast to start, but rules and limits live in the SaaS layer |
| Managed APIs such as HasData or review-focused tools | Broader travel-data delivery and outsourced infrastructure | Vendor infrastructure | Low | API/data delivery | Usage or subscription | Less selector control, stronger managed-service posture |
| Python or JavaScript scripts | Engineering-owned scraping pipelines | Your infrastructure | High | Whatever you build | Engineering plus proxy/rendering cost | Maximum control, maximum maintenance |
| UScraper Tripadvisor Japan template | Prepared Japan hotel URLs, visible local run, CSV-first export | Local desktop app | Low | Local CSV | Free template; app plan applies | Best for modest audited batches, not unattended fleet-scale crawling |
This is a comparison table, not a ranking. A travel product with public Tripadvisor content should start with official API eligibility. A data engineering team may prefer Apify or scripts. A revenue analyst comparing a controlled set of hotels may prefer UScraper because the workflow is visible and the CSV lands in a local folder.
Where UScraper wins
When UScraper is the better Octoparse or Apify alternative
UScraper wins when the job is controlled, supervised, and CSV-first. The Tripadvisor Hotel Listings Scraper for Japan template includes a multi-URL Navigate block, page-load waits, a CAPTCHA signal check, Structured Export, and Loop Continue. You can inspect the flow, change the save folder, adjust columns, and run one hotel visibly before expanding the URL list.
UScraper wins when hotel URLs and exported rows should stay on machines your team controls. Hosted tools may still be approved internally, but they add vendor storage and cloud execution to the workflow.
Cloud actors win when you need scheduled jobs, API delivery, queueing, remote datasets, and infrastructure that runs without an analyst watching the browser.
Depends. Scripts are best when engineers need tests, version control, and custom parsers. UScraper is better when business users need to maintain a visual flow without owning a codebase.
UScraper wins for prepared Tripadvisor Japan hotel detail URLs. Listing-page discovery, large pagination crawls, or review firehoses may fit other tools better.
The honest limitation: this template is not a magic bulk crawler. Tripadvisor can show consent prompts, locale variants, DataDome challenges, 403 pages, price modules that change by session, and layout changes. The advantage is inspectability. If a row is blank or fallback-only, you can see the browser state and decide whether to retry, update selectors, or exclude the input.
Export shape
What the UScraper Tripadvisor Japan template exports
The JSON workflow is the authoritative definition. It appends one row per supplied hotel URL into tripadvisor-jp-hotel-listings-scraper.csv. The configured selectors first try live page data, then fall back to URL-derived values or known sample-preview values when Tripadvisor blocks live rendering.
tripadvisor-jp-hotel-listings-scraper.csvColumn
hotel_count
Destination or facility-count context when visible.
Column
hotel_name
Hotel name from page content, metadata, JSON-LD, URL parsing, or sample fallback.
Column
price
Visible yen price text when the page renders a price module.
Column
ranking
Combined bubble-rating and review-count text where available.
Column
rating
Numeric rating such as 5.0, 4.5, or 3.5.
Column
review_count
Localized review-count text.
Column
amenities
Amenity labels or special offer text detected on the page.
Column
scraped_at
ISO timestamp generated during the local run.
Column
detail_page_url
The Tripadvisor hotel detail URL that produced the row.
If you need review text, phone numbers, images, deep amenity lists, or listing-page discovery from a destination page, compare this template with hotel detail scrapers, review scrapers, and marketplace actors before committing.
Decision guide
How to pick the right Tripadvisor scraper
Choose the Tripadvisor Content API when your project is a public travel product, mobile app, partner integration, or licensed content use case. Choose Apify when you want hosted actors, API-accessible datasets, scheduled runs, and cloud infrastructure. Choose Octoparse when a no-code team wants a vendor-hosted visual scraper and a listing-page template. Choose Web Scraper, Browse AI, or Thunderbit when fast no-code extraction matters more than local custody. Choose scripts when engineering will own parsing, retries, monitoring, storage, and compliance controls.
Choose UScraper when the requirements are narrower: prepared Japan hotel URLs, visible browser execution, a workflow that analysts can inspect, and CSV output stored locally. Start with the Tripadvisor Hotel Listings Scraper for Japan template, then browse the template library or return to the blog for related tutorials and comparison guides.
FAQ
Frequently asked questions
The best option depends on scale, compliance path, hosting preference, and output. Use the official API for sanctioned product integration, hosted actors for recurring cloud runs, scripts for engineering-owned pipelines, and UScraper when analysts need a local desktop app workflow that exports prepared Japan hotel URLs to CSV.