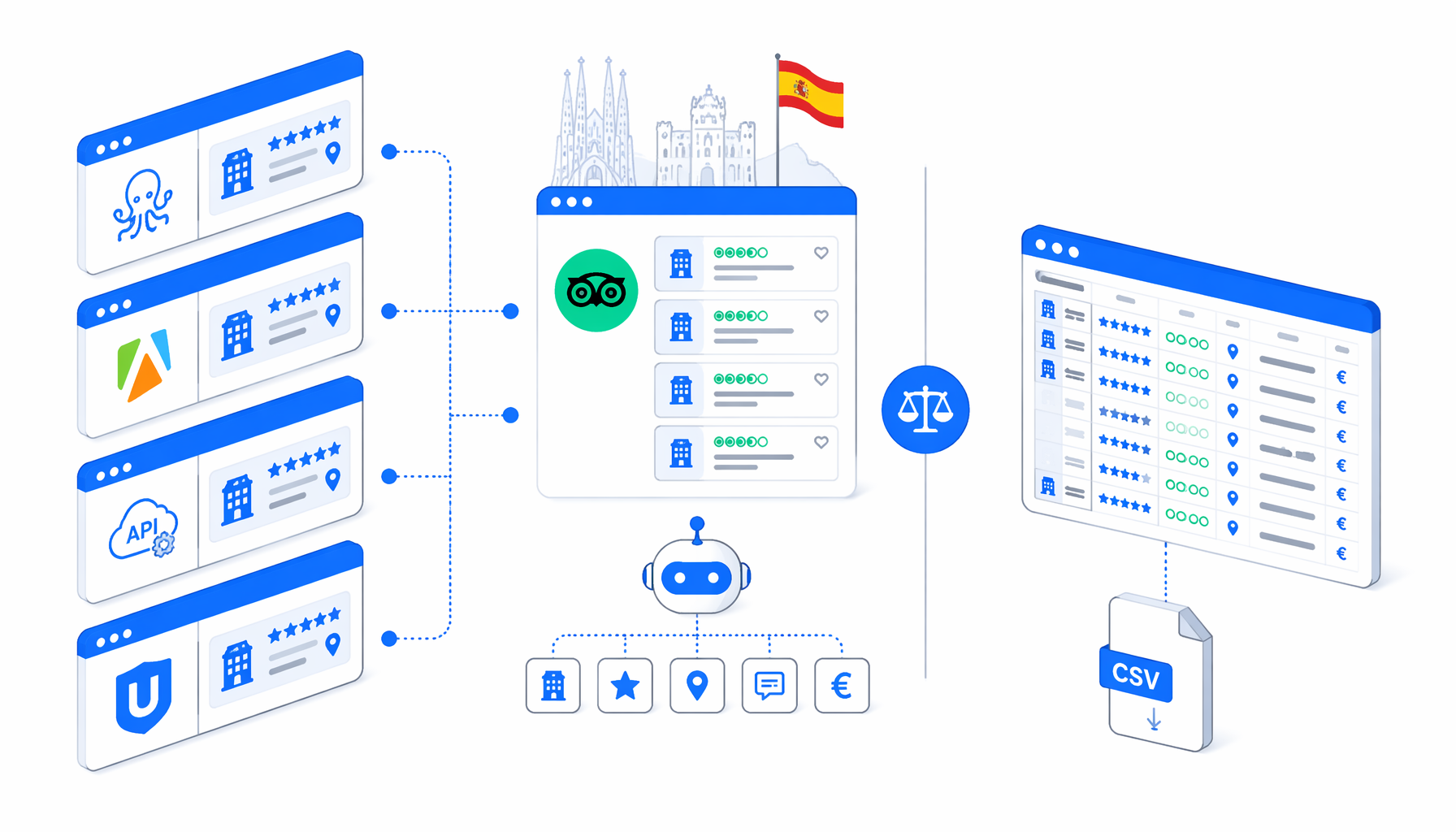
The best Tripadvisor hotel scraper depends on the job: approved partner data, hosted no-code, cloud actors, API pipelines, scripts, or a local CSV. This comparison covers Octoparse Tripadvisor scraper vs Apify, Browse AI, WebScraper.io, Thunderbit, scraper APIs, scripts, and UScraper's Spain hotel listing template.
Decision frame
Best Tripadvisor hotel listing scraper alternatives in 2026
A useful Tripadvisor hotel listing scraper has to answer four questions before the first row is exported: where does the browser run, who maintains the parser, what does pricing meter, and what output format do you get?
Tripadvisor hotels are not a simple static table. Listing and hotel pages can include locale labels, changing price modules, provider cards, consent prompts, rankings, review counts, amenity blocks, and access controls. That is why searches like how to scrape Tripadvisor hotels usually lead to several tool families:
- Official access through the Tripadvisor Content API or hotel content products.
- Hosted no-code templates such as Octoparse, Browse AI, and WebScraper.io.
- Cloud actors and APIs such as Apify, Thunderbit, ScrapingBee, ScrapFly tutorials, and custom scripts.
The real comparison is not "which tool can scrape Tripadvisor?" It is "which tool matches my hosting, compliance, cost, and output requirements?"
Side by side
Octoparse Tripadvisor scraper vs Apify vs UScraper
| Option | Hosting | Code needed | Output | Pricing shape | Best fit | Main trade-off |
|---|---|---|---|---|---|---|
| Official Tripadvisor Content API | Tripadvisor API | Medium | Structured partner API | Commercial API or partner terms | Approved travel products | Not a quick spreadsheet workflow |
| Octoparse Tripadvisor scraper | Vendor platform with cloud options | Low | Hotel name, price, rating, URL, CSV/Excel exports | SaaS plans; verify current Octoparse pricing | Hosted no-code task setup | Less local custody |
| Apify Tripadvisor hotel actors | Apify cloud | Low to medium | Dataset, JSON, CSV, Excel, API | Platform usage, actor cost, compute, proxy, and storage; verify Apify pricing | Scheduled cloud jobs and APIs | Cost is job-shaped |
| Browse AI robot | Vendor cloud | Low | Listing rows and monitors | Subscription or credit model | Quick no-code robots | Less parser control |
| WebScraper.io marketplace | Extension plus cloud options | Low | Scraper output for cloud or local workflows | Cloud plan and credit model; verify WebScraper.io pricing | Teams already using Web Scraper Cloud | Custom logic can become fiddly |
| Thunderbit | AI scraper extension/cloud workflow | Low | Excel, Google Sheets, Airtable, Notion style exports | AI scraper subscription or credits | Fast manual extraction and enrichment | Less deterministic than hand-maintained selectors |
| ScrapingBee, ScrapFly, or similar APIs | Provider infrastructure | Medium | JSON, HTML, API responses | Request, credit, or bandwidth pricing | Backend ingestion | Requires code and schema ownership |
| Open-source Python scripts | Your machine or server | High | Whatever you build | Engineering time plus proxies/rendering | Versioned parser control | You own breakage and retries |
| UScraper + Spain hotel template | Local desktop app | Low | CSV from supplied Spain hotel URLs | Free template; app licensing applies | Auditable local batches | Not a hands-off cloud fleet |
Where UScraper fits
Where UScraper and the Spain hotel template win
Start with the Tripadvisor Hotel Listing Scraper for Spain when the job is a controlled list of hotel detail URLs and the deliverable is a CSV. The template is not trying to crawl every hotel in Spain from one search page. It opens each supplied Tripadvisor hotel URL, waits for the page, handles common consent labels, runs Structured Export, and appends one row per URL.
That narrower scope is the point. UScraper is stronger when an analyst wants to watch the page load, inspect the block graph, adjust waits, change the save folder, and see exactly which columns are exported. The visual flow is easy to audit: Set Window Size -> Navigate -> Wait for Page Load -> Sleep -> Inject JavaScript -> Structured Export -> Loop Continue.
tripadvisor_hotel_listados_scraper.csvColumn
numero_de_alojamientos
Visible hotel or accommodation count context when present.
Column
titulo
Page title or URL-derived title fallback.
Column
hotel_name
Hotel name from H1, metadata, or the URL slug.
Column
url_de_pagina_de_detalles
Source Tripadvisor hotel detail URL.
Column
precio
Visible EUR, USD, or localized price when rendered.
Column
rating
Bubble rating or rating label.
Column
numero_de_opiniones
Visible review count in Spanish or English.
Column
ota_recomendada
Detected provider labels such as Booking, Agoda, Expedia, or Hotels.com.
Column
info
Ranking, value, or hotel context text.
Column
amenities
Detected amenity labels such as Wi-Fi, pool, parking, breakfast, bar, spa, gym, or beach.
Column
hora_actual
Timestamp generated during the local export.
The cost story is also simpler for this use case. The template is free, and the workflow writes to your configured local folder. You are not paying an actor run meter or hosted result credit inside the template itself, although the UScraper app has its own licensing.
Where alternatives win
When hosted tools, APIs, or scripts are better
UScraper is not the right answer for every Tripadvisor project. If a product will show Tripadvisor content to users, review the official API first. If a team needs nightly feeds across many destinations, Apify, WebScraper.io Cloud, Octoparse Cloud, or managed APIs may be easier to operate. If engineers need tests, queues, and Git review, a script can be cleaner.
The official Tripadvisor API path is the safer first stop when the project needs partner terms, stable access, or redistribution rights.
Compliance
Tripadvisor scraper API alternative and compliance checks
Publicly visible hotel pages are not automatically free to collect, store, or reuse. Before any Tripadvisor scraper API alternative goes into production, review the live Tripadvisor Terms of Use, robots directives, privacy obligations, copyright or database rights, contracts, and local law.
Do not bypass CAPTCHA, DataDome, login walls, paywalls, or technical access controls. Keep test runs small, preserve source URLs, and separate research use from redistribution. For sanctioned commercial use, compare scraping tools against the official Content API.
Decision guide
Which Tripadvisor hotel scraper should you choose?
UScraper wins. The workflow is visible, runs in a local desktop app, and exports the configured hotel fields to tripadvisor_hotel_listados_scraper.csv.
Hosted tools win. Apify, Octoparse Cloud, WebScraper.io Cloud, or managed APIs are a better fit when the job needs recurring remote runs and centralized logs.
Official API routes win. Start with Tripadvisor's content products when permissions, licensing, and stable partner access matter.
It depends. Scraper APIs and scripts are better for JSON ingestion. UScraper is better when a business user needs to inspect a browser run and hand off a CSV.
Browse the UScraper template library for hotel workflows, or return to the blog for more scraper comparisons.
FAQ
Use the official Content API for approved integrations, Apify or scraper APIs for cloud pipelines, Octoparse or Browse AI for hosted no-code work, scripts for engineering control, and UScraper for local CSV exports from approved Spain hotel URLs.