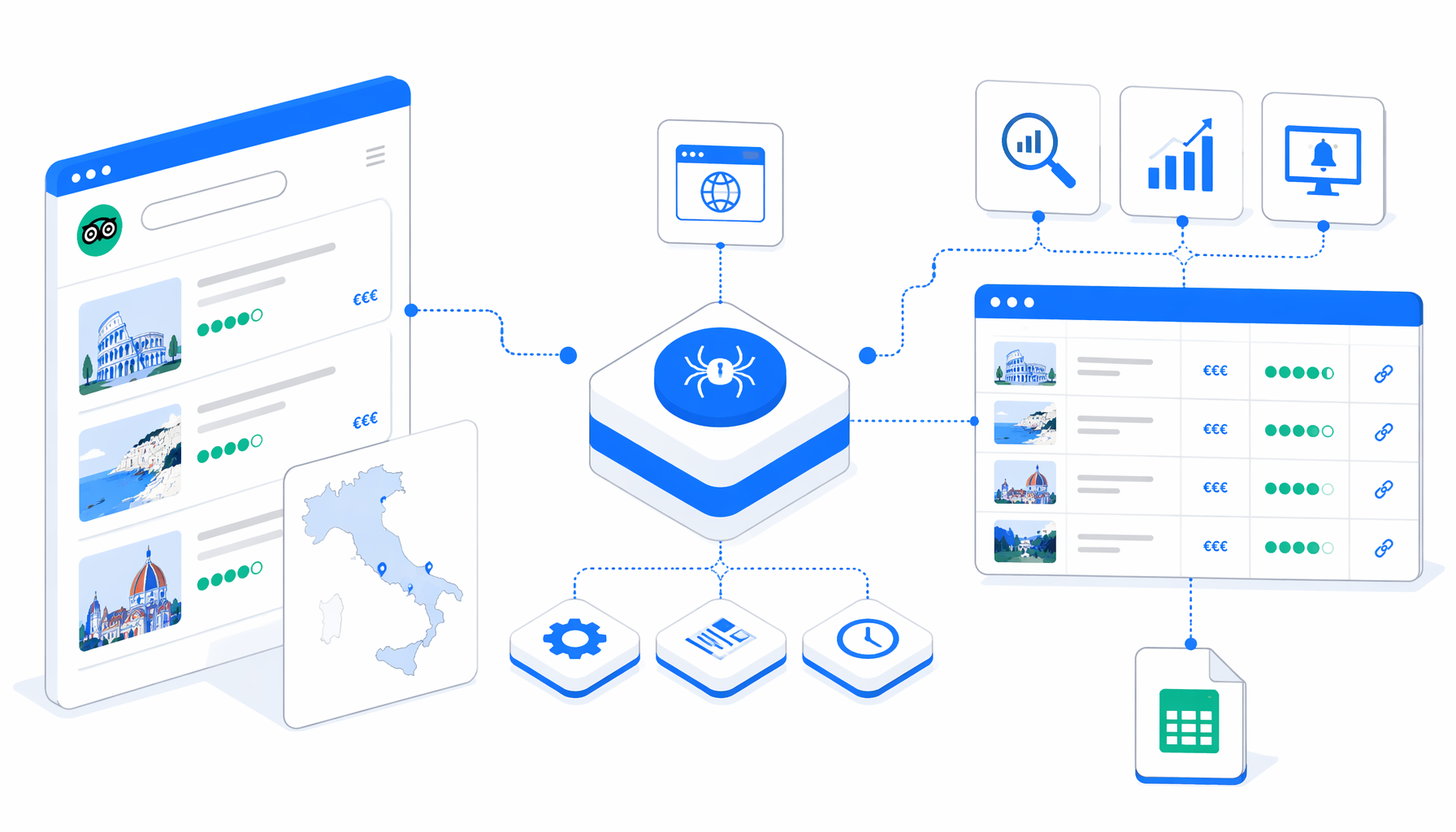
Tripadvisor hotel data scraping for Italy is useful when the question is specific: which hotels appear for Milan, Rome, Venice, Florence, Naples, Sicily, or another destination, what visible price and rating signals are present, and which detail pages should be reviewed next. The Tripadvisor Hotel Scraper for Italy template turns that browser work into a local CSV workflow in UScraper.
Problem
Italy hotel research breaks when it stays in browser tabs
A hotel researcher can open the Tripadvisor Italy hotels page, filter a city, copy a few names, and paste prices into a spreadsheet. That works for five properties. It fails when a newsroom needs evidence, an SEO team needs entity coverage, or a monitoring team needs to compare the same destination every week.
Manual collection loses the source page, collection date, page language, ranking context, and blanks. A hotel can appear with no visible price. A rating without review volume can overstate confidence. A city page can paginate, reorder, or show a challenge instead of hotel cards. A controlled Tripadvisor hotel list scraper is not about grabbing "all Tripadvisor data"; it is about turning a defined, permitted listing page into rows that can be checked later.
The practical deliverable is a dated CSV for one travel research question, not a claim that every Tripadvisor page can or should be automated.
Personas
Who uses Tripadvisor Italy hotel data?
| Persona | Pain | Useful CSV outcome |
|---|---|---|
| Travel researchers | Destination research turns into screenshots, notes, and inconsistent spreadsheets. | Compare hotel name, detail URL, visible price, rating, and review count for one Italy destination. |
| Newsrooms | Reporters need a source trail that editors can audit. | Preserve listing URL, detail URL, visible fields, and blank-field signals beside each selected hotel. |
| SEO teams | Destination briefs need hotel entities, not only generic hotel keywords. | Build content briefs from hotel names, review depth, price visibility, and city-specific listing coverage. |
| Monitoring teams | Rechecking competitive sets by hand is slow and easy to distort. | Re-run the same approved listing URL and compare CSV versions over time. |
| Agencies | Client work needs a handoff file, not an analyst's browser session. | Deliver a local CSV that can be filtered, deduped, annotated, and attached to a report. |
Use the export to shortlist hotels for one city, region, or route. The detail URL becomes the audit key, while price, rating, and review count help decide which pages deserve manual review.
Workflow
How the template turns hotel listings into structured export
The JSON workflow is intentionally narrow. It opens a Tripadvisor.it hotel listing page in the local desktop app, waits for client-side rendering, checks for common DataDome challenge frames, waits once for manual resolution when needed, checks whether hotel listing rows are available, exports visible rows, and follows the next-page link until pagination ends or rows disappear.
The bundled sample starts with a Milan hotel listing URL, but the Navigate block can be changed to another approved Italy listing page. The Structured Export block writes rows in append mode, so pagination can add results to the same file.
crawler-lista-hotel-tripsdvisor.csvColumn
Url_inserito
Current Tripadvisor listing URL opened in the browser.
Column
Parola_chiave
Destination keyword inferred from the heading, title, or URL path.
Column
Nome_dell_hotel
Visible hotel name from each listing card.
Column
Prezzo
Visible price text when Tripadvisor exposes one.
Column
Valutazione
Rating parsed from visible labels or card text.
Column
Recensioni_totali
Total review count parsed from the listing card.
Column
Pagina_dei_dettagli
Absolute Tripadvisor hotel detail URL for dedupe and review.
Use cases
Concrete workflows for Tripadvisor hotel data scraping
1. Destination supply snapshots
Pick one destination, such as Milan, Rome, Venice, Florence, or Naples. Run the template against the approved listing URL and export the visible hotel cards. The output helps a researcher answer practical questions: which hotels appear, which ones show prices, which properties have deeper review volume, and which detail pages should be inspected manually.
2. SEO entity and content audits
Search keywords like "hotels in Athens Greece" or "hotels in Singapore" show how competitive hotel SERPs can be, even outside Italy. For Italy-focused SEO work, listing exports help teams move from generic keyword volume to entity-level research: hotel names, destination language, visible price signals, and review depth. Use the CSV beside your broader template library research rather than relying on copied notes.
3. Newsroom and evidence preparation
Reporters often need to organize selected properties before publication. A CSV with source URL, detail URL, hotel name, price visibility, rating, and review count is easier to review than a pile of tabs. If a run returns blank fields or zero rows, treat that as a signal to inspect manually, not as evidence that the hotel has no data.
4. Competitive monitoring
Monitoring works only when the inputs stay stable. Use the same listing URL, browser profile, language, currency, and export path. Then compare CSV versions by Pagina_dei_dettagli. This can show whether a monitored set gained new listing rows, lost visible prices, changed review counts, or needs selector maintenance.
Define the research question
Decide whether the run supports destination research, SEO enrichment, editorial evidence, or monitoring. The question determines the listing URL and review process.
Choose an approved listing page
Start from one Tripadvisor Italy hotel listing URL your team is allowed to process. Keep the first run narrow so errors are easy to inspect.
Run the template locally
Import the Tripadvisor Hotel Scraper for Italy, replace the sample URL, confirm the CSV folder, and run a short validation pass.
Audit before analysis
Compare the browser view with the CSV. Validate hotel names, detail URLs, price blanks, rating format, review counts, and duplicate detail pages before drawing conclusions.
API vs scraping
When to use Tripadvisor's API instead
If your product needs sanctioned Tripadvisor content, public redistribution, application integration, stable API responses, or contract-backed access, start with Tripadvisor's official Content API and API terms. The API path is built for approved partners and production integrations.
Use UScraper when the job is a supervised research export: visible listing rows, a modest run, a local CSV, and an analyst who can inspect the browser state. Hosted tools and scraper APIs can be better for scheduling, parallel execution, datasets, and developer pipelines. The local desktop app pattern is better when custody, transparency, and spreadsheet review matter more than high-volume collection.
For adjacent guidance, read the step-by-step Tripadvisor Italy scraping tutorial, compare Tripadvisor scraper alternatives, or browse more UScraper articles in the blog library.
FAQ
Who should use a Tripadvisor hotel list scraper for Italy?
Use it when researchers, newsrooms, SEO teams, agencies, or monitoring teams need a reviewable CSV of visible hotel listing fields from pages they are allowed to process. It is not a shortcut for broad, unsupervised collection.
What does the UScraper Italy hotel template export?
The template exports Url_inserito, Parola_chiave, Nome_dell_hotel, Prezzo, Valutazione, Recensioni_totali, and Pagina_dei_dettagli to crawler-lista-hotel-tripsdvisor.csv.
When should I use the Tripadvisor Content API instead?
Use Tripadvisor's official Content API route when the project needs approved partner access, public display rights, stable API responses, production integration, or contractual permission to use Tripadvisor content.
Is Tripadvisor hotel data scraping a compliance risk?
Yes. Tripadvisor terms, robots directives, access controls, copyright, privacy rules, database rights, and local law may affect automated collection. Review current rules, keep runs modest, and avoid bypassing verification.
Why can a Tripadvisor hotel scraper return zero rows?
Zero rows usually mean the browser saw a CAPTCHA, consent state, blocked session, regional layout, empty listing page, or changed hotel-card markup instead of normal listing rows. The template ends gracefully rather than treating a challenge page as hotel data.