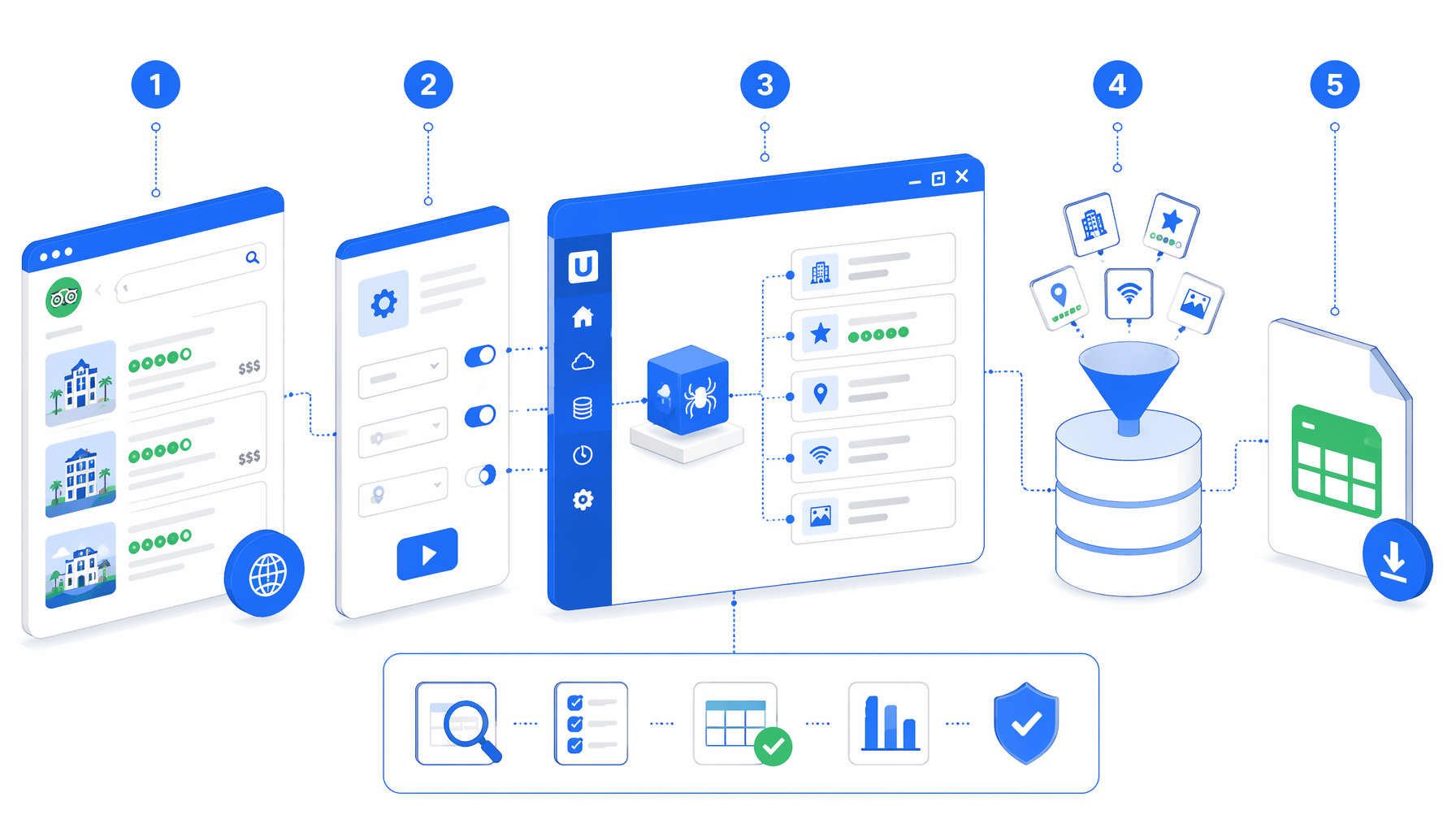
This tutorial shows how to scrape Tripadvisor hotels from prepared hotel detail URLs into CSV with the Tripadvisor Hotel Details Scraper template for UScraper. You will import the workflow, replace URLs, set the export path, and validate access_status.
Before you start
Prerequisites for a Tripadvisor hotel details scraper
You need UScraper installed as a local desktop app, the Tripadvisor Hotel Details Scraper template, and a short list of hotel detail URLs your team is allowed to process. Start with three to five URLs because Tripadvisor pages vary by country domain, language, consent state, and access response.
This guide is for supervised detail enrichment, not a broad crawler. The workflow does not search a city, log into private dashboards, bypass CAPTCHA, collect booking-only data, or guarantee every field on every locale.
Review Tripadvisor's Terms of Use, robots.txt, and official Content API route before automation. Use the Content API for partner integrations or redistribution; use a local scraper for modest internal research exports you can inspect.
Technical access is not permission. Use approved URLs, collect only needed fields, and stop when access challenges appear.
Workflow anatomy
What the Tripadvisor hotel scraper workflow does
The exported JSON is the authoritative definition of the workflow. In plain English, it runs:
Set Window Size -> Navigate URL list -> Wait for Page Load -> Sleep
-> Inject JavaScript -> Sleep -> Wait for body -> Structured Export
-> Loop Continue
Navigate stores the hotel URLs. The waits give Tripadvisor time to render content or show verification. Inject JavaScript installs window.__TA_GET(...), clicks visible accept or expand controls, scrolls, reads JSON-LD when available, and records blocked states. Structured Export writes the configured columns. Loop Continue advances.
| Workflow block | Purpose | What to check |
|---|---|---|
| Set Window Size | Opens a consistent large viewport | Keep the default unless fields hide. |
| Navigate | Holds the list of Hotel_Review URLs | Replace sample Valencia URLs with approved hotel pages. |
| Wait and Sleep blocks | Let content or verification states settle | Increase waits only after watching a slow run. |
| Inject JavaScript | Expands visible controls and creates extraction helpers | Re-test when Tripadvisor changes layout or locale text. |
| Structured Export | Appends one hotel row to CSV | Confirm filename, folder, headers, and append mode. |
| Loop Continue | Moves to the next URL | Keep it after export so every URL gets one chance to write. |
Runbook
How to scrape Tripadvisor hotel data to CSV
Import the template
Open Tripadvisor Hotel Details Scraper, download the JSON, and import it into UScraper.
Replace the sample URLs
Open Navigate and paste approved Tripadvisor Hotel_Review links. Keep the country domain and language when your report depends on localized fields.
Set the export destination
In Structured Export, change the save folder to your project directory. Keep headers and append mode enabled for one combined CSV.
Run one hotel first
Run a single URL while watching the browser. If you see consent, missing content, verification, or CAPTCHA, resolve access questions before continuing.
Validate, then batch
Compare the first row against the live page, then widen the URL list only after names, ratings, amenities, images, and status fields look sane.
Append mode means rerunning the same URLs writes more rows. Clear test rows or add a date to the filename before production runs.
Output
CSV output and field validation
The companion template exports Spanish column names because the source workflow was modeled from Tripadvisor.es pages. Rename them after export if your team needs English headers.
| Column group | Fields | Validation check |
|---|---|---|
| Hotel identity | titulo, clasificacion, direccion, url_del_hotel | One input URL should create one row and one hotel name. |
| Contact and source | telefono, hotel_website, pagina_url | Treat phone and website as optional because not every page exposes them. |
| Rating signals | rating, opiniones, rating_ubicacion, rating_limpieza, rating_servicio | Compare one row against the browser before trusting aggregates. |
| Hotel attributes | servicios_de_la_propiedad, servicios_de_habitacion, tipos_de_habitacion, idiomas | Blank cells often mean collapsed sections, locale changes, or layout drift. |
| Nearby and media | restaurantes_en_un_radio_de_1_km, atracciones_en_un_radio_de_1_km, imagen_url1 to imagen_url3 | Check that image URLs are hotel images, not verification assets. |
| Run audit | hora_actual, access_status | Filter blocked_or_captcha rows before analysis. |
tripadvisor_hotel_detalles_scraper.csvColumn
titulo
Hotel name from structured data, heading, fallback sample, or URL slug.
Column
direccion
Address from JSON-LD or visible page content.
Column
rating
Overall Tripadvisor rating for the current locale.
Column
opiniones
Visible review count or structured review count.
Column
servicios_de_la_propiedad
Property amenity text after expand controls.
Column
imagen_url1
First non-verification image URL.
Column
pagina_url
Hotel detail URL for audit and dedupe.
Column
access_status
page_loaded or blocked_or_captcha.
Sample rows
1 of many
| titulo | direccion | rating | opiniones | servicios_de_la_propiedad | imagen_url1 | pagina_url | access_status |
|---|---|---|---|---|---|---|---|
| Hotel Malcom and Barret | Avenida Ausias March 59, Valencia | 4,8 | 2879 opiniones | Wifi, gimnasio, bar, restaurante | https://... | Hotel_Review-g187529... | page_loaded |
Troubleshooting
Common issues when scraping Tripadvisor hotels
| Symptom | Likely cause | Fix |
|---|---|---|
| CSV has headers but no hotel rows | The browser never reached the Structured Export step or the page did not expose body in time | Run one URL, extend waits slightly, and watch the browser state. |
access_status is blocked_or_captcha | Tripadvisor returned verification, CAPTCHA, DataDome, or a blocked page | Stop the batch. Do not bypass the challenge. Review permission, pacing, and API fit. |
| Amenities are blank | The amenities panel did not render, did not expand, or used new locale text | Add a scroll step, rerun one page, then update the helper if the page changed. |
| Phone or website is blank | Tripadvisor did not publish the field or hid it behind an interaction | Treat these fields as optional and avoid filling unknown values by guesswork. |
| Duplicate rows appear | The same URL was pasted twice or a rerun appended to an old CSV | Dedupe by url_del_hotel or clear the file before rerunning. |
Python tutorials, hosted scraping APIs, Apify actors, and no-code cloud scrapers can all be valid choices. Use Python for full code ownership, hosted infrastructure for high-volume scheduling, and UScraper for supervised CSV exports where analysts inspect the browser, blocks, and file locally.
FAQ
Tripadvisor hotel scraper FAQ
Tripadvisor hotel pages can be publicly visible, but automated access and reuse may still be restricted by Tripadvisor terms, robots directives, copyright, privacy law, contract rules, and local regulations. Use only URLs you are allowed to process, avoid bypassing access controls, keep runs modest, and get legal review before commercial reuse.
Next step
Download the Tripadvisor hotel details scraper
When you are ready to run the workflow, download the JSON from Tripadvisor Hotel Details Scraper and keep this tutorial open for validation. For adjacent travel workflows, browse the UScraper template library, or read more CSV export tutorials in the UScraper blog.