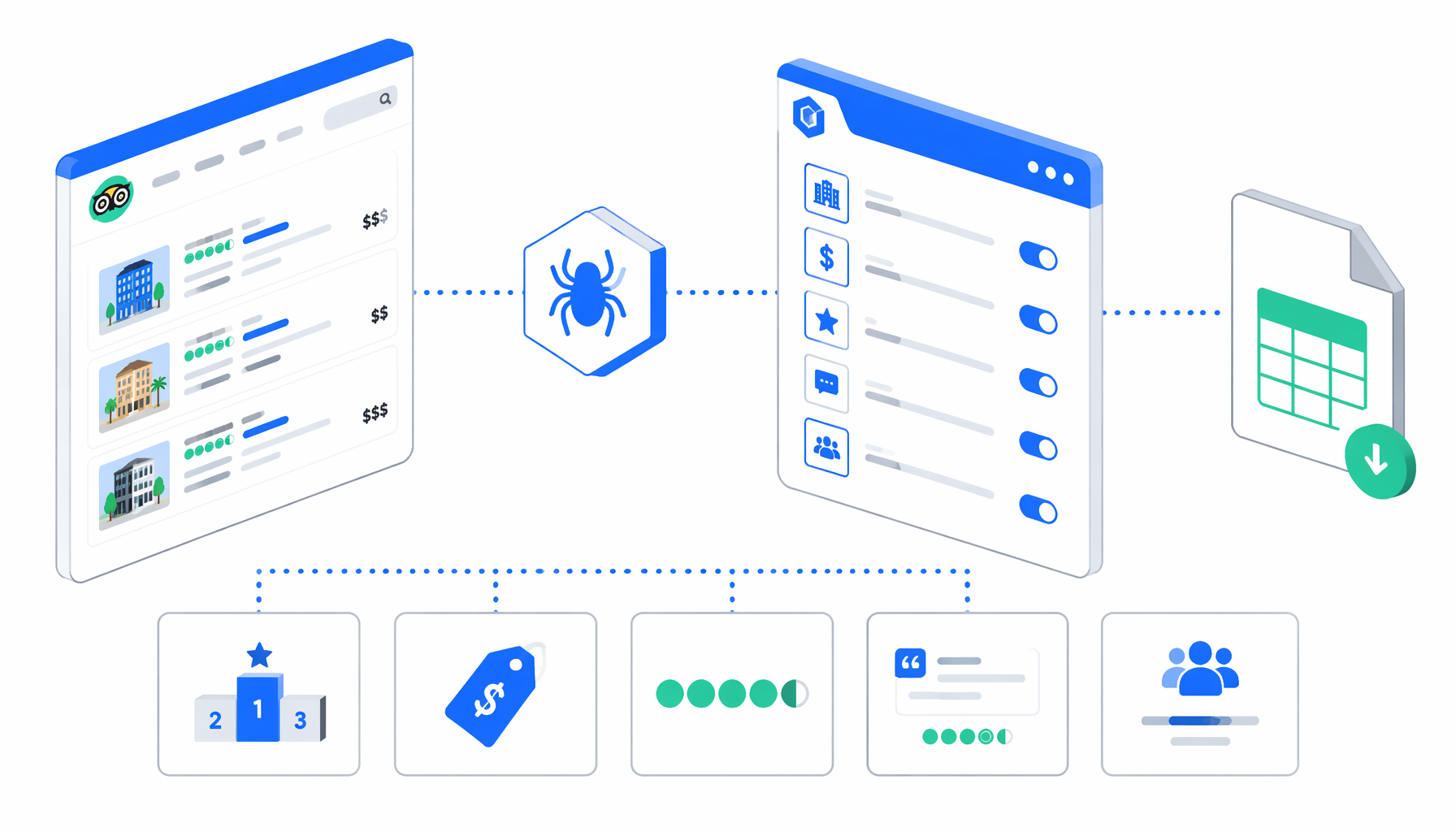
This tutorial shows how to scrape Tripadvisor hotels from listing pages into CSV with UScraper's Tripadvisor Hotel Info Scraper. You will import the template, choose listing URLs, set the export path, run the pagination offsets, and validate rankings, prices, ratings, review counts, snippets, and diagnostic rows before using the file.
Before you start
Prerequisites, scope, and permission checks
You need UScraper installed as a local desktop app, the free Tripadvisor Hotel Info Scraper template, and Tripadvisor listing URLs your team is allowed to process. The bundled workflow starts with Tripadvisor France URLs for London hotels and uses predictable -oa30 offsets through 10 pages.
This guide covers visible hotel listing cards. It does not cover private dashboards, login-only data, booking flows, hidden endpoints, CAPTCHA bypassing, or republishing Tripadvisor content. Before automation, review Tripadvisor's Terms of Use, the official Content API, and the Terra platform documentation if your project needs approved content access.
Technical access is not permission. Keep runs proportionate, preserve source URLs, do not defeat access controls, and use official API or partner routes when your use case needs contractual rights.
Choose the path
Tripadvisor API vs scraping: which path fits?
A Tripadvisor hotel scraper template is useful when an analyst needs a reviewable spreadsheet from pages they can inspect in a browser. The official API path is different: it is better for approved travel products, stable contracts, and permitted reuse inside an application.
| Path | Best fit | Trade-off |
|---|---|---|
| Tripadvisor Content API or Terra | Approved integrations, location content, partner products, and redistribution rights | Requires access, integration work, and an approved use case. |
| UScraper template | Internal research, destination scans, comp-set shortlists, and local CSV review | Selectors and waits may need maintenance when Tripadvisor changes pages. |
| Hosted tools such as Octoparse or Apify | Scheduled cloud runs, vendor infrastructure, datasets, or API-style retrieval | Data custody, pricing, and scraper behavior depend on the vendor environment. |
| Python scraper | Engineering-owned parsing, tests, queues, retries, and custom schemas | Requires code, monitoring, compliance review, and ongoing maintenance. |
The UScraper workflow is closest to an inspectable no-code alternative to a hosted Tripadvisor hotel scraper template. It is not a substitute for official permission or a hands-off cloud scraping operation.
Workflow anatomy
What the Tripadvisor hotel info scraper does
The JSON export is the authoritative workflow definition. In plain English, the flow runs:
Set Window Size -> Navigate -> Wait for Page Load -> Sleep
-> Element Exists -> Structured Export -> Sleep -> Loop Continue
The Navigate block includes 10 Tripadvisor France listing URLs for London hotels:
https://www.tripadvisor.fr/Hotels-g186338-London_England-Hotels.html
https://www.tripadvisor.fr/Hotels-g186338-oa30-London_England-Hotels.html
...
https://www.tripadvisor.fr/Hotels-g186338-oa270-London_England-Hotels.html
That offset list avoids fragile next-button clicks. Each URL becomes one loop iteration, and every successful hotel row appends to the same CSV. The row selector checks several common card patterns, including hotel review links, data-automation hotel cards, data-testid property cards, and older listing containers.
If hotel rows exist, the true branch exports hotel fields. If not, the false branch exports one body row with the source URL, page number, blank hotel fields, and a commentaire value such as BLOCKED_BY_DATADOME_CAPTCHA or NO_HOTEL_ROWS_FOUND. That distinction matters because a blocked page should never be treated as a valid zero-result destination.
tripadvisor-hotel-info-scraper.csvColumn
Page_URL
The listing URL opened during the current loop iteration.
Column
classement
Hotel ranking parsed from visible text or calculated from the page offset and card index.
Column
nom
Hotel name from the card title, Hotel_Review link, or title text fallback.
Column
détail_url
Absolute Tripadvisor hotel detail URL for follow-up enrichment.
Column
image_url
First visible hotel-card image URL when available.
Column
prix
Visible price text, usually present only when Tripadvisor exposes pricing for the session.
Column
note
Rating parsed from labels, title text, or visible card copy.
Column
nombre_avis
Review count such as 1 842 avis or equivalent review text.
Column
site_hôtel
Tripadvisor commerce or hotel website link when present.
Column
auteur_avis
Reviewer name when a snippet module appears in the listing card.
Column
commentaire
Review snippet or diagnostic message for blocked and unmatched pages.
Column
Numéro_de_la_page
Page number calculated from the -oa offset.
Runbook
How to scrape Tripadvisor hotel info to CSV
Import the template
Open Tripadvisor Hotel Info Scraper, download the JSON workflow, and import it into UScraper.
Run the bundled London test
Keep the sample Tripadvisor France London URLs for the first run. A known URL list helps separate workflow issues from custom destination changes.
Set the export folder
In Structured Export, confirm tripadvisor-hotel-info-scraper.csv, keep headers enabled, keep append mode on, and choose a project-specific local folder.
Watch the first page load
Let the browser reach the listing page, wait up to 45 seconds for page load, pause for dynamic modules, and then check whether hotel rows are present.
Validate the CSV
Open the CSV after one or two URLs. Compare nom, détail_url, prix, note, and nombre_avis against the browser before trusting a larger file.
Replace URLs carefully
After validation, replace the Navigate URLs with approved hotel listing pages for your own destination. Keep language, filters, and sort order stable while testing.
Append mode is useful because every offset lands in one file. It can also mix old test rows with production rows. Clear the CSV or use a dated filename before a final run.
Quality checks
Validate the Tripadvisor hotels CSV before analysis
Open the CSV beside the browser. Spot-check at least the first page, one middle offset, and the last configured offset if the run completed. Sort by détail_url to find duplicates, and filter commentaire for diagnostics before handing the file to a stakeholder.
| Check | Why it matters |
|---|---|
Page_URL matches the intended destination | Confirms the run used the correct listing URLs and filters. |
nom and détail_url match visible cards | Confirms the row selector is catching hotels, not navigation or ads. |
classement increments across offsets | Helps detect repeated pages or offset mistakes. |
| Price blanks are explainable | Tripadvisor may hide prices by date, session, region, or availability state. |
| Diagnostic rows are separated | BLOCKED_BY_DATADOME_CAPTCHA and NO_HOTEL_ROWS_FOUND are QA signals, not hotel data. |
For a two-stage hotel research workflow, use this article to build the listing CSV first, then send selected détail_url values into a detail-page workflow from the broader UScraper template library. You can also browse related tutorials from the UScraper blog when the job shifts from hotel info to reviews, restaurants, maps, or booking sites.
Troubleshooting
Common issues and fixes
Tripadvisor hotel pages can be visible in a browser, but automated extraction may still be limited by Tripadvisor terms, robots directives, copyright, privacy law, database rights, contract rules, and access controls. Review the current rules, use only pages you are allowed to access, avoid bypassing verification, keep runs modest, and get legal review before commercial reuse.