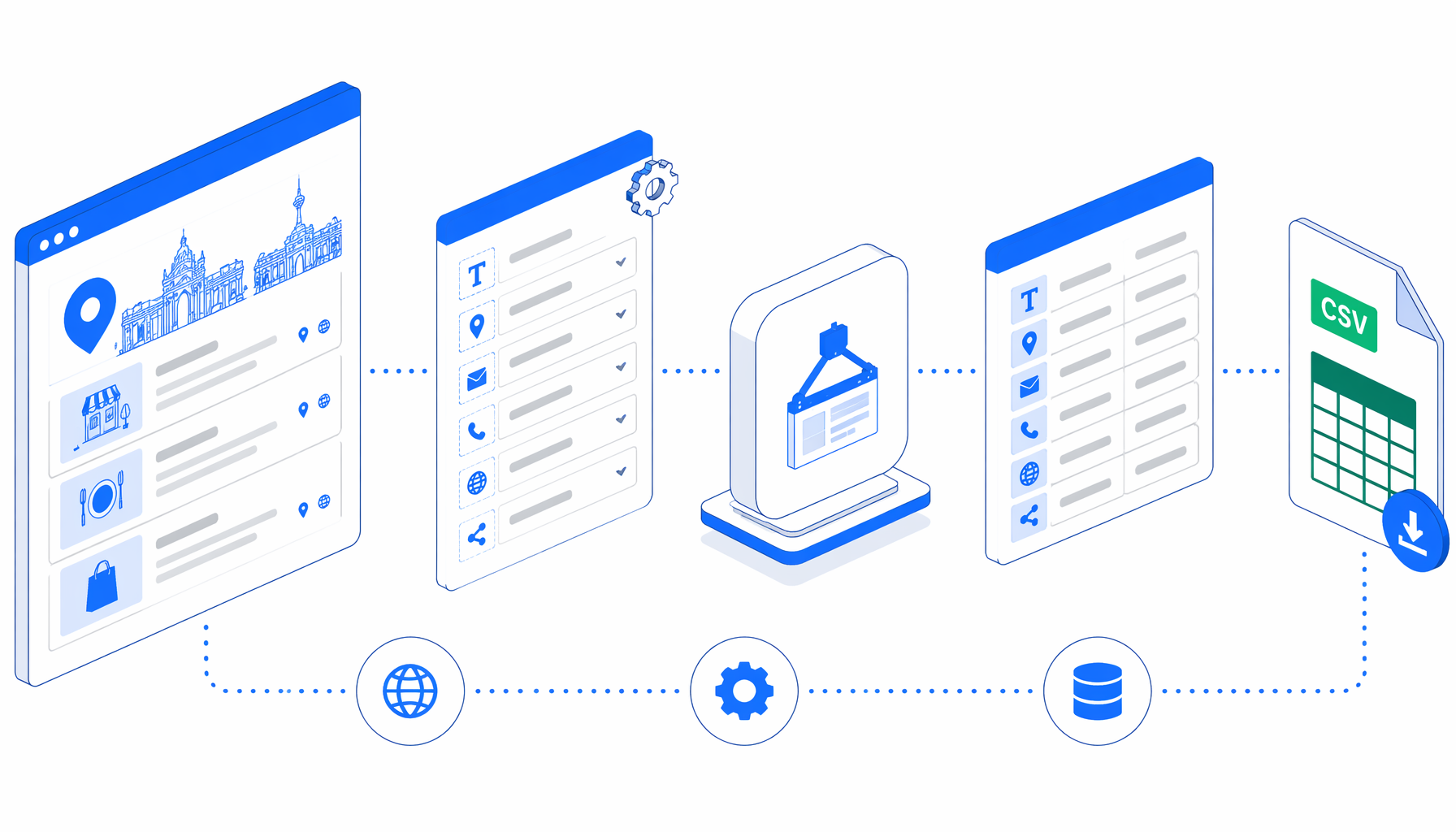
This tutorial shows how to scrape Todo Esta en Madrid listings into CSV with the TodoEstaEnMadrid Scraper by URL for UScraper. You will import the workflow, set the export folder, run a small validation pass, and check the contact fields.
CSV
9
URL
Visible QA
Local
Before you start
Prerequisites and source checks
You need UScraper installed as a local desktop app, the TodoEstaEnMadrid scraper template, one public Todo Esta en Madrid URL, and a folder where the CSV can be written. Start with one narrow page, not the whole site.
Todo Esta en Madrid is useful because it combines several discovery surfaces: the official directory homepage, area and neighborhood pages, category pages, municipal-market pages, route pages, and individual shop detail pages. The source is a city-commerce directory, but public visibility is not the same as unrestricted reuse.
Treat the first run as a policy and quality check. Review current source terms and robots directives, collect only the fields you need, keep the URL list with your export, and do not automate around logins, blocked pages, or access controls.
Workflow anatomy
How the TodoEstaEnMadrid scraper works
The JSON template is the authoritative workflow definition. In plain English, the flow is:
Navigate -> Wait for Page Load -> Sleep -> Scroll -> Sleep
-> Inject JavaScript -> Wait for Element -> Structured Export -> End
The workflow opens the input URL, waits for rendering, scrolls once to trigger delayed content, then runs JavaScript extraction. That step scans visible business cards and embedded JSON, filters navigation labels, separates websites from social links, and writes clean rows into a hidden container. Structured Export reads that container and creates a fresh CSV.
The template also includes a fallback layer. If the live page withholds usable business rows, it avoids exporting sparse category text and uses clean preview-style records instead. Use that for column-shape testing, not as a substitute for live-page validation.
| Stage | What it does | What to verify |
|---|---|---|
| Navigate | Opens the Todo Esta en Madrid URL you provide | The page is a listing, category, route, or detail surface |
| Wait and scroll | Gives rendered cards and lazy content time to appear | Business names and contact blocks are visible |
| Inject JavaScript | Builds normalized rows from cards and structured data | Non-business labels are not exported as names |
| Wait for Element | Confirms extracted rows exist before export | Row count is greater than zero |
| Structured Export | Writes a local CSV with headers | Filename and folder are correct |
Runbook
How to scrape Todo Esta en Madrid listings to CSV
Pick a focused input URL
Choose a public Todo Esta en Madrid page that already shows the businesses you want: a subcategory, neighborhood, market, route, or individual listing surface. Avoid starting from broad news or homepage sections.
Import the template
Open TodoEstaEnMadrid Scraper by URL, download the JSON workflow, and import it into UScraper.
Replace the sample URL
In the Navigate block, paste your selected Todo Esta en Madrid URL. Keep the first run to one URL so you can inspect every exported row.
Set the export folder
In Structured Export, confirm todoestaenmadrid-scraper-url.csv, headers enabled, create mode, and a project-specific local save location.
Run and validate
Run the workflow visibly, open the CSV, compare several rows against the browser, and only then repeat the process for more categories or neighborhoods.
Use a fresh filename or folder for each campaign, neighborhood, or client.
Output
TodoEstaEnMadrid business fields exported
The export shape comes from the Structured Export block in the JSON. No CSV sample is bundled with this post, so use the column summary below and the template JSON as the source of truth.
todoestaenmadrid-scraper-url.csvColumn
nombre
Business or establishment name.
Column
descripcion
Cleaned description or business summary when present.
Column
domicilio
Street address, market location, or visible location text.
Column
correo
Email from mailto links or visible text.
Column
telefono
Phone number from tel links or visible contact text.
Column
sitio_web
External website, separated from social profiles when possible.
Column
red_social_1
First detected social URL.
Column
red_social_2
Second detected social URL.
Column
red_social_3
Third detected social URL.
For validation, sort by nombre and inspect domicilio, telefono, sitio_web, and the social columns. Blank cells are normal when the source page does not expose a field. Bad exports show menu labels in nombre, long category paragraphs in descripcion, duplicates, or one generic entry.
Troubleshooting
Common Todo Esta en Madrid scraping issues
| Symptom | Likely cause | Fix |
|---|---|---|
| Empty CSV | The page did not render business cards before export | Increase waits, run visibly, and confirm rows appear before Structured Export |
| Category labels as names | The URL is too broad or the page layout changed | Use a narrower subcategory, area, market, route, or detail page |
| Missing email or phone | The source listing does not expose that field | Keep the blank cell and verify manually before outreach |
| Social link in website column | The page only exposes a social URL | Move it during cleanup or update the extractor rule |
| Very few rows | No enabled next-page control was available on that page | Process another specific listing URL instead of forcing pagination |
Alternatives
UScraper, Octoparse, Apify, or custom code?
Octoparse has a TodoEstaEnMadrid URL template, and generic cloud scrapers such as Apify Web Scraper can crawl pages when you configure selectors and pagination. Custom Scrapy or Playwright code gives more control, but adds setup, hosting, and selector maintenance.
| Option | Best fit | Trade-off |
|---|---|---|
| UScraper template | Local, inspectable CSV exports from known Todo Esta en Madrid URLs | You still need to validate each source page and keep runs supervised |
| Octoparse template | Users already working inside Octoparse projects | Cloud workflow behavior and plan limits may not match local QA needs |
| Apify or custom crawler | Larger engineering-led crawling and scheduling | More configuration, code, or hosted infrastructure to maintain |
Use the UScraper template when you want a visible local desktop workflow and a CSV you can inspect immediately.
Frequently asked questions
Todo Esta en Madrid shows public business-directory pages, but automated collection may still be limited by website terms, robots directives, privacy rules, copyright, database rights, and local law. Review the current source policies, keep runs modest, avoid access-control bypassing, and get legal review before commercial use.
Next step
Download the template and run the first page
Open the TodoEstaEnMadrid Scraper by URL template, import the JSON into UScraper, and run one focused URL. After the CSV passes review, repeat the process for neighboring categories and compare related guides in the UScraper blog or the template library.