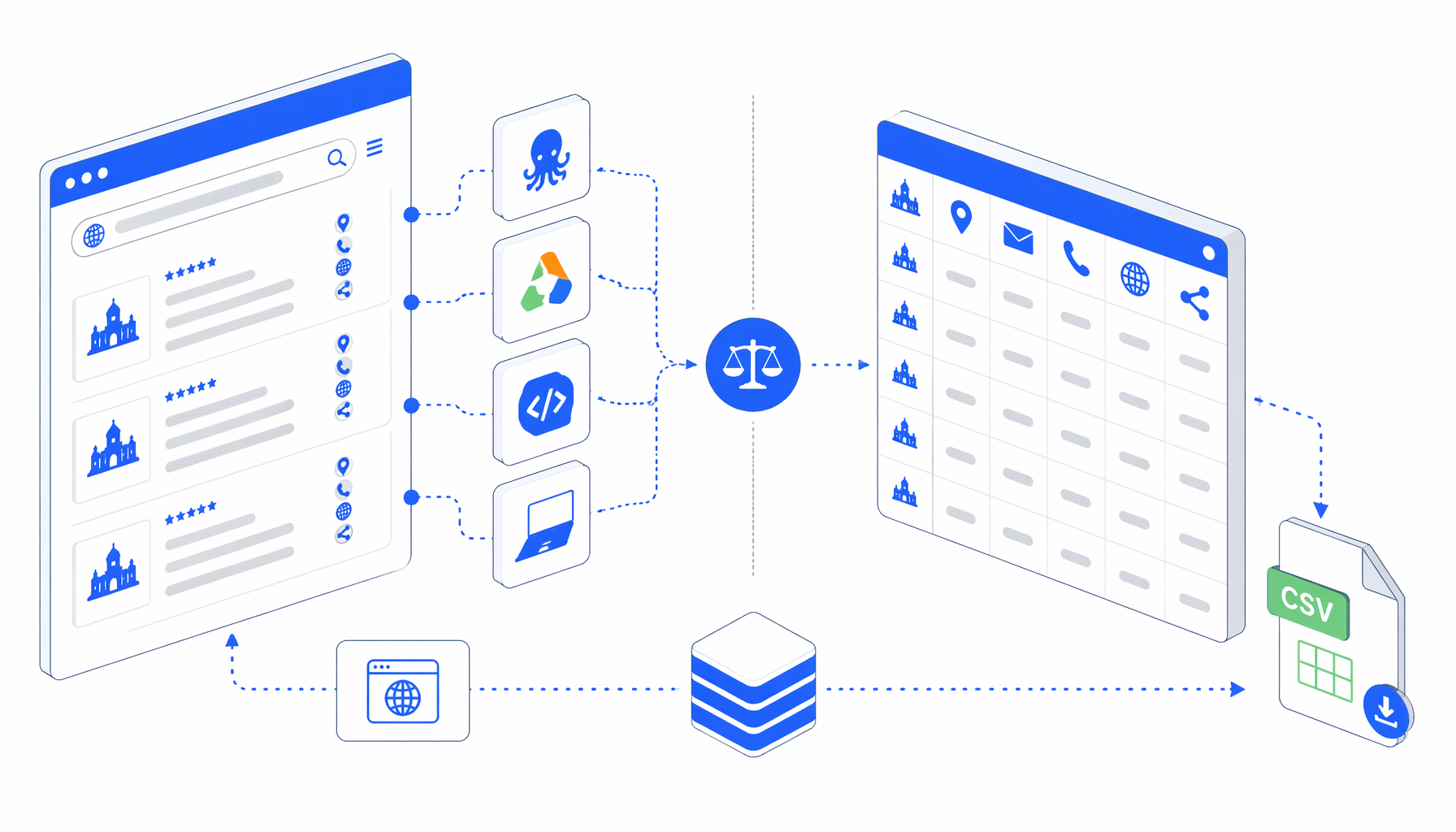
The best Todo Esta en Madrid scraper is not one fixed tool. It depends on whether you want an Octoparse-style SaaS template, an Apify actor, a ParseHub visual project, a Python or JavaScript scraper, or UScraper's TodoEstaEnMadrid Scraper by URL for local CSV exports from known directory URLs.
Comparison frame
What a Todo Esta en Madrid scraper has to solve
Todo Esta en Madrid is a city-commerce directory tied to Madrid's official digital commerce program. It groups shops, hospitality businesses, services, municipal markets, neighborhoods, routes, and category pages into browsable local surfaces for Madrid business discovery, store audits, local SEO checks, and lead-list preparation.
The hard part is not only collecting rows. A TodoEstaEnMadrid data extraction workflow has to load dynamic pages, wait for rendered cards, separate business records from navigation text, and answer operating questions: where does the browser run, who maintains selectors, what does the export look like, and what pricing meter applies?
The practical question is not "can this scrape a page?" It is "which workflow gives us the right hosting model, data custody, output shape, and maintenance path for Madrid directory research?"
Side-by-side
Todo Esta en Madrid scraper alternatives compared
| Option | Best fit | Hosting | Code needed | Output shape | Pricing shape | Main trade-off |
|---|---|---|---|---|---|---|
| Octoparse TodoEstaEnMadrid template | Teams already using Octoparse templates | Vendor SaaS | Low | Table export, CSV, Excel-style files depending on plan | SaaS plan, task, and cloud limits | Convenient exact template, but vendor-hosted workflow |
| Apify Web Scraper or actor marketplace | Hosted jobs, datasets, APIs, and automation chains | Vendor cloud | Low to medium | JSON, CSV, dataset API | Platform usage, actor pricing, proxies, and storage | Strong orchestration, less local custody |
| ParseHub visual projects | Point-and-click extraction from directory-style pages | Vendor app/cloud | Low to medium | Tables, CSV, JSON | Plan limits and run speed limits | Flexible, but project maintenance still matters |
| Crawlee or Scrapy | Engineering-owned crawlers | Your environment | Medium to high | Whatever your pipeline writes | Developer time, infrastructure, proxies, monitoring | Maximum control, maximum upkeep |
| UScraper + TodoEstaEnMadrid Scraper by URL | Local CSV from selected category or listing URLs | Local desktop app | Low | CSV with 9 directory fields | Free template; desktop license applies | Best for inspectable local runs, not cloud fleets |
This is a comparison, not a universal ranking. A production data product may need queues and APIs. A marketing or research team often needs something narrower: paste a Todo Esta en Madrid URL, run one visible browser flow, export CSV, and review the contact fields.
Where UScraper wins
When UScraper is the better TodoEstaEnMadrid scraper
UScraper is strongest when the input is already known: a Todo Esta en Madrid category, subcategory, market, route, or listing page your team has reviewed. The TodoEstaEnMadrid Scraper by URL template opens the URL, waits, scrolls once to trigger delayed content, scans visible business cards and embedded JSON, filters sparse category records, and writes todoestaenmadrid-scraper-url.csv.
The bundled workflow definition is the authoritative sample because there is no separate CSV file in the bundle. It exports these columns:
| CSV column | What it captures | Why it matters |
|---|---|---|
nombre | Business or establishment name | Main identity for dedupe and review |
descripcion | Listing summary, hours, or profile text when available | Helps qualify the business before outreach |
domicilio | Street address or location text | Supports neighborhood and coverage analysis |
correo | Email address when visible | Useful for manual, compliant follow-up |
telefono | Phone number when visible | Adds contact context for verification |
sitio_web | Non-social website URL | Supports enrichment and SEO audits |
red_social_1 to red_social_3 | Facebook, Instagram, X, LinkedIn, YouTube, TikTok, or similar links | Shows active channels and alternate contact paths |
The visible flow is the advantage. You can inspect Navigate, waits, scroll, JavaScript extraction, row container creation, and Structured Export. If a page returns blank data, the operator can see whether the problem is loading, consent UI, selector drift, missing pagination, or unavailable fields.
Where alternatives win
When Octoparse, Apify, ParseHub, or scripts make more sense
Choose Octoparse if your team already runs Octoparse, wants the exact SaaS template, and prefers cloud task management over local workflow custody. Its English and Spanish template pages are directly relevant for octoparse todoestaenmadrid alternative searches.
Choose Apify when you need cloud actors, datasets, APIs, schedules, run history, and automation links into other systems.
Choose ParseHub for visual projects your team can maintain. Choose Crawlee, Scrapy, Playwright, or Selenium scripts when engineering owns version control, tests, retries, proxies, and storage.
UScraper wins when extracted Madrid business rows should be saved to a local CSV folder and reviewed before import into CRM, spreadsheets, or enrichment tools.
Cloud platforms win when jobs must run unattended, publish data through APIs, retry at scale, or connect to downstream systems without an operator.
Depends. Octoparse, ParseHub, and UScraper are all no-code or low-code paths. The real difference is hosted execution versus a visible local desktop app flow.
Scripts win when you need tests, queues, versioned parsers, custom storage schemas, observability, and engineering-owned compliance gates.
Policy
Directory scraping still needs permission review
Todo Esta en Madrid pages may be publicly viewable, and the official Madrid context describes the program as a digital showcase for local commerce and services. That does not automatically mean every automated use is allowed. Review the live site, the official participation page, applicable terms, robots directives, copyright, database-right rules, privacy obligations, and outreach laws before commercial use.
Decision guide
Which Madrid business directory scraper should you pick?
Pick Octoparse for the fastest hosted template path. Pick Apify for cloud actors, datasets, and APIs. Pick ParseHub for visual projects that your team is comfortable maintaining. Pick Crawlee or Scrapy when engineers own the scraper as production software.
Pick UScraper when the job is narrower and spreadsheet-first: you have approved Todo Esta en Madrid URLs, want an editable visual workflow, want the run to happen in a local desktop app, and need nombre, descripcion, domicilio, correo, telefono, sitio_web, and social links in CSV. Start with the TodoEstaEnMadrid Scraper by URL template, compare more workflows in the template library, review license details on UScraper pricing, or return to the blog for related scraper comparisons.
FAQ
Todo Esta en Madrid scraper FAQ
The best option depends on scale, hosting, code tolerance, output format, and maintenance. Use hosted platforms for cloud automation, scripts for engineering-owned pipelines, and UScraper for an inspectable local desktop app workflow that exports selected directory URLs to CSV.