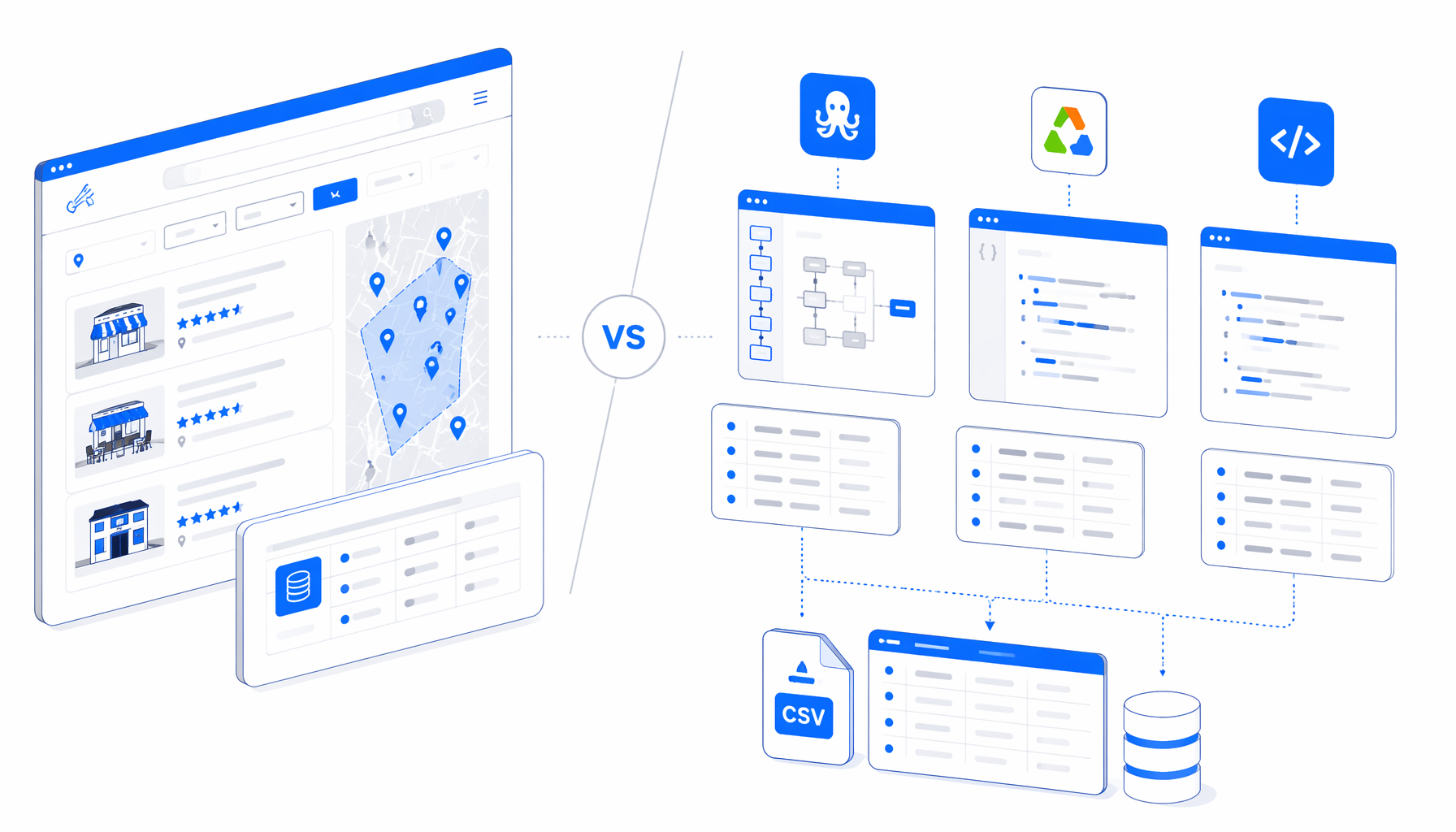
The best Tabelog scraper for area listings is not automatically the biggest cloud platform. It depends on whether you need a hosted scraper API, a no-code marketplace template, a maintainable Python script, or a local desktop app that turns a controlled restaurant URL list into CSV. This comparison focuses on Octoparse, Apify, managed scraper vendors, scripts, and UScraper's Tabelog Store Listings Scraper by Area.
Comparison frame
What a Tabelog by-area scraper has to solve
Searches like how to scrape Tabelog, best Tabelog scraper, and Tabelog scraper comparison usually hide different jobs. One team may only need a first-pass restaurant list for a station area. Another may need ratings, addresses, budgets, reviews, and menu details. A developer may want a scraper API. An analyst may only want a CSV that can be spot-checked against the browser.
For the by-area listings use case, the hard parts are practical rather than glamorous: collect the right restaurant URLs, avoid mixing unrelated areas, wait for pages to render, handle optional fields, keep source URLs for audit, and stop when Tabelog presents CAPTCHA, verification, login, or restricted content.
Before automating, review Tabelog's current rules and robots.txt. Public visibility is not the same thing as unrestricted automated reuse.
Side-by-side
Tabelog scraper alternatives compared
| Option | Best fit | Hosting | Code needed | Output shape | Pricing shape | Main trade-off |
|---|---|---|---|---|---|---|
| UScraper + Tabelog Store Listings Scraper by Area | Local CSV from a controlled area URL list | Local desktop app | Low | CSV: area, genre, store_name, page_url | Free template plus app plan | Best for inspectable local runs, not fleet-scale crawling |
| Octoparse Tabelog templates | No-code teams that want a hosted visual scraper | Vendor ecosystem and cloud options | Low | Table exports such as CSV or Excel-style files | SaaS plans, task limits, and cloud resources | Convenient marketplace flow, but less local custody |
| Apify Tabelog actors | Developer workflows, recurring runs, datasets, and APIs | Apify cloud | Low to medium | Dataset, JSON, CSV, API delivery | Platform usage plus actor-specific pricing | Strong orchestration, but cloud-first |
| Bright Data or managed scraper APIs | Enterprise data collection and managed delivery | Vendor infrastructure | Low to medium | API responses, datasets, or contracted delivery | Usage, record, request, or contract pricing | Powerful for scale, often too heavy for one research CSV |
| Thunderbit or AI no-code scrapers | Fast operator-led extraction from visible pages | Browser extension or cloud-assisted workflow | Low | Spreadsheet-style structured rows | Subscription or credit-style plans | Quick setup, but output quality still needs QA |
| ParseHub, ScrapeStorm, and generic visual builders | Mixed web extraction projects beyond Tabelog | Vendor app and cloud options | Low | CSV, JSON, or spreadsheet exports | Tiered SaaS | Flexible, but setup varies by page complexity |
| Python, Scrapy, or Playwright scripts | Engineering-owned parsers and pipelines | Your infrastructure | High | Any schema you build | Engineering time plus hosting/proxy/API cost | Maximum control, maximum maintenance |
The table is not a universal ranking. If your team needs scheduled cloud jobs and API access, Apify or a managed data scraper API may be the right answer. If your team wants a no-code hosted template, Octoparse or Thunderbit may be faster. If your actual deliverable is a reviewed CSV for a known area, a smaller local workflow can be easier to defend.
Where UScraper wins
When the local desktop app route is better
The Tabelog Store Listings Scraper by Area is intentionally narrow. The workflow opens configured Tabelog restaurant detail URLs, waits for the page load and an h1, runs Structured Export, and appends one CSV row per URL.
That shape is useful when a researcher has already defined the area and wants a reviewable export rather than a black-box data feed. The browser run is visible. The workflow graph is editable. The export folder is chosen locally. The columns are compact enough for quick QA.
CSV
4
URL list
Load + h1
Local run
| UScraper field | How it is used |
|---|---|
area | Groups restaurants by breadcrumb area so you can filter one city, ward, or station cluster. |
genre | Captures the primary restaurant category when it is visible on the page. |
store_name | Gives the human-readable restaurant name for review and deduplication. |
page_url | Preserves traceability back to the source page before enrichment or handoff. |
The bundle does not include a separate CSV sample, so the JSON workflow definition is the authoritative sample of the export. It also makes the limitation clear: selectors can break when Tabelog changes markup, and a by-area URL queue is only as good as the URLs you put into it.
Where others win
When cloud actors, scraper APIs, or scripts make more sense
Choose Octoparse when the buyer is comparing an Octoparse Tabelog scraper alternative and mainly wants hosted no-code extraction, a visual builder, and a larger template ecosystem.
Choose Apify when the comparison is Apify Tabelog scraper vs Octoparse and the requirement leans developer: actors, datasets, scheduled runs, webhooks, API calls, and repeatable cloud jobs.
Choose Bright Data, Scrapebit, Spider, or another managed provider when procurement wants outsourced infrastructure, support, and delivery guarantees more than selector-level workflow visibility.
Choose Python, Scrapy, or Playwright when engineering wants versioned parsers, tests, queues, logs, storage, and full control over failure handling. The trade-off is that every layout change becomes your maintenance work.
UScraper wins when the browser run, export folder, and restaurant rows should stay in a local desktop workflow.
Apify and hosted vendors win when remote jobs, queues, webhooks, and programmatic delivery are core requirements.
Octoparse wins when marketplace breadth and hosted visual scraping matter more than local output custody.
Scripts win for engineering control. UScraper wins when non-developers need to inspect and adjust a visual flow without owning a codebase.
Decision guide
Pick by workflow, not vendor logo
Use this decision path before buying or rebuilding anything:
- Pick UScraper for known Tabelog restaurant URLs, a visible local desktop app run, editable blocks, and CSV output.
- Pick Octoparse or Thunderbit for hosted no-code extraction when the team already works inside those tools.
- Pick Apify for cloud actors, scheduled jobs, datasets, and scraper API style handoff.
- Pick managed scraper vendors for procurement-led data delivery at larger scale.
- Pick Python or Scrapy when engineers need custom parsing, tests, databases, and source-control review.
For the local route, start with a five to ten URL validation batch. Confirm that row count matches accessible input URLs, click several page_url values, and compare the exported area, genre, and store_name against the live browser page. Then widen the area list gradually.
For a step-by-step setup, read the Tabelog area scraper tutorial. For adjacent workflows, browse the UScraper template library or the UScraper blog.
Prefer a local template workflow when the work is periodic, supervised, and CSV-first. Prefer hosted infrastructure when recurring automation, support, and retries justify cloud metering.
FAQ
FAQ
What is the best Tabelog area scraper alternative?
The best Tabelog area scraper alternative depends on hosting, code tolerance, output format, scale, and compliance review. UScraper is strongest for local CSV exports from a controlled URL list. Octoparse and Thunderbit fit hosted no-code teams. Apify and scraper APIs fit cloud automation. Python or Scrapy scripts fit engineering-owned parsing.
How does UScraper compare with Octoparse for Tabelog by-area listings?
Octoparse offers hosted Tabelog templates and a large no-code scraping ecosystem. UScraper is better when the operator wants a local desktop app, visible workflow blocks, editable selectors, a controlled restaurant URL list, and a CSV written to a chosen local folder.
Is Apify better than Octoparse for Tabelog scraping?
Apify is usually better for developers who need cloud actors, datasets, APIs, queues, and scheduled runs. Octoparse is usually easier for no-code operators who prefer a visual scraper environment. UScraper is the simpler choice when the deliverable is a supervised local CSV rather than a cloud pipeline.
What does the UScraper Tabelog area template export?
The UScraper template writes tabelog-store-listings-by-area-scraper.csv with area, genre, store_name, and page_url columns. The workflow opens configured Tabelog restaurant detail URLs, waits for page readiness, and appends one row per URL.
Is it legal to scrape Tabelog store listings by area?
Legality depends on permission, jurisdiction, access method, source rules, robots directives, data type, volume, and downstream use. Review Tabelog rules and robots.txt, do not bypass CAPTCHA or access controls, keep runs modest, and get legal advice before commercial reuse or redistribution.