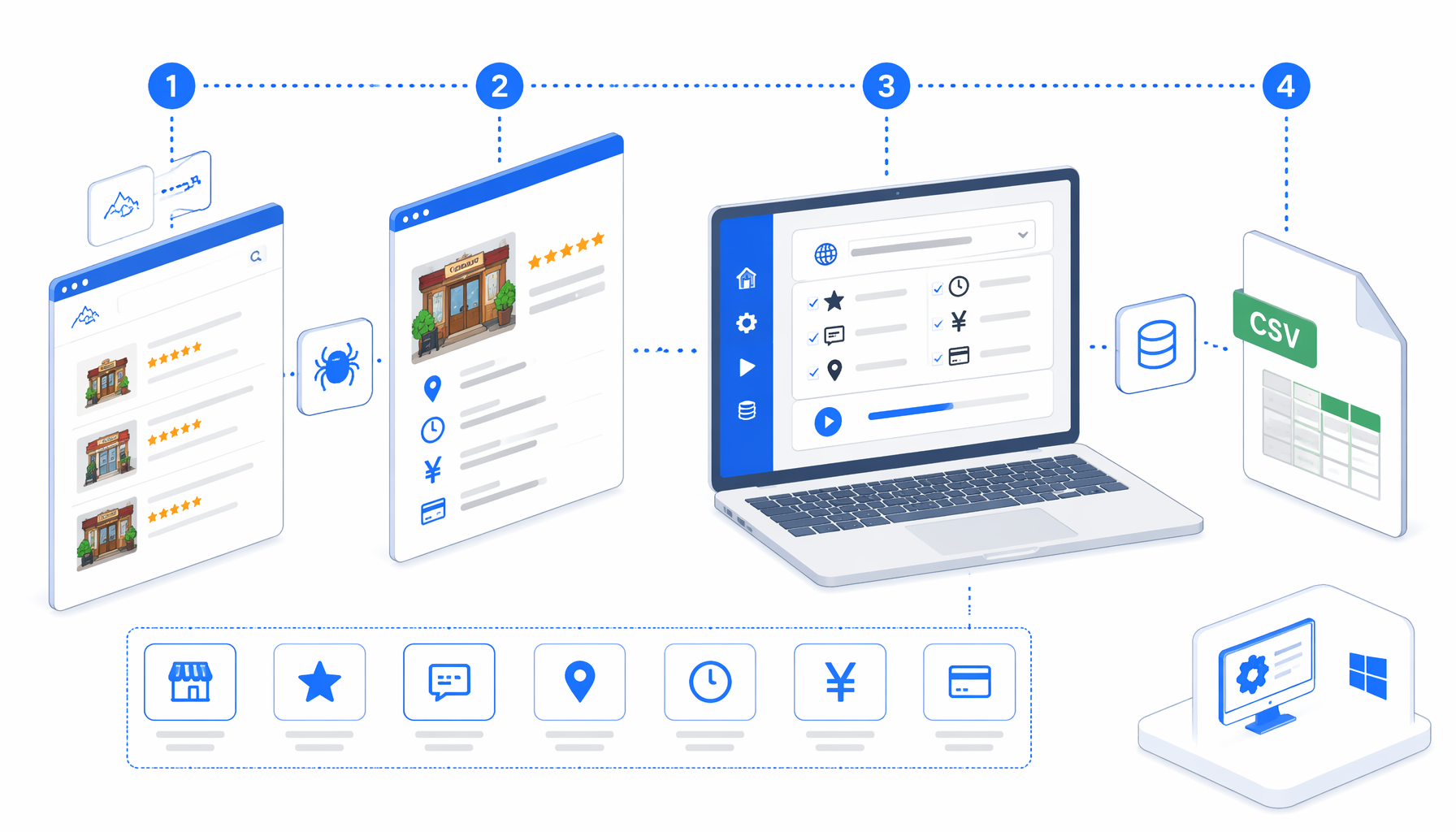
This Tabelog scraper tutorial shows how to turn approved restaurant detail URLs into a structured CSV with the Tabelog Restaurant Scraper for Store Details for UScraper. You will prepare URLs, import the workflow, choose an export path, run a small validation batch, and troubleshoot the fields that commonly drift on Tabelog pages.
Before you start
Prerequisites for a Tabelog scraper tutorial
You need UScraper installed as a local desktop app, the template JSON from the related page, a writable export folder, and a short list of Tabelog restaurant detail URLs. Start with three to five URLs. A small batch proves that the page loads, the selectors still match the current layout, and the CSV path is correct before append mode creates a larger file.
Use Tabelog's English restaurant guide and restaurant listing page for manual research and URL discovery, then keep the final URL queue beside the exported CSV. Before automation, review Tabelog's current rules and robots.txt. This article covers browser-visible restaurant pages only; it is not guidance for bypassing login prompts, CAPTCHA, paywalls, verification pages, or source restrictions.
Technical access is not permission. Collect only the fields you need, keep request volume conservative, and get legal review before commercial resale, redistribution, enrichment, or model-training use.
Workflow anatomy
How the Tabelog restaurant data scraper works
The JSON export is the authoritative workflow definition. The bundled graph follows a direct sequence:
Navigate -> Wait for Page Load -> Wait for Element
-> Structured Export -> Sleep -> Loop Continue
Navigate owns the list of Tabelog restaurant URLs. Wait for Page Load gives the browser time to finish loading. Wait for Element waits for a visible h2, which is the readiness signal used by the bundle. Structured Export reads the rendered page body and writes fixed CSV columns. Sleep adds a one-second pause, and Loop Continue advances to the next URL.
| Workflow block | What it controls | What to verify |
|---|---|---|
| Navigate | Restaurant detail URL list | One source URL should map to one CSV row. |
| Wait blocks | Page readiness | The restaurant heading is visible before export. |
| Structured Export | CSV filename, save folder, headers, append mode, and columns | Replace the sample local path with your own folder. |
| JavaScript columns | Field extraction from Tabelog's rendered table and metadata | Empty cells often mean optional fields or layout drift. |
| Loop Continue | Multi-URL batching | The run should advance without manual copy-paste. |
Output
Tabelog details exported to CSV
The workflow writes one row per restaurant detail URL. No CSV sample shipped with the bundle, so treat the JSON export shape as the source of truth and validate the first rows against the live page before using the data downstream.
Tabelog-Store-list-detail-Scraper.csvColumn
Restaurant_name
Visible restaurant name from the main page heading.
Column
Page_URL
Current Tabelog detail page URL.
Column
Star_rating
Rating parsed from page metadata or visible rating elements.
Column
Number_Of_Reviewers
Visible review-count text where present.
Column
Categories
Genre/category text from the restaurant information table.
Column
Tel_for_reservation
Reservation contact field when displayed.
Column
Address
Address text cleaned of map helper copy.
Column
Transportation
Access or nearest transport instructions.
Column
Operating_hours
Opening-hour text from the detail table.
Column
Budget
Budget or review-aggregate budget field.
Column
Method_of_payment
Payment method text where Tabelog exposes it.
For quality control, sort by Page_URL. Every approved input URL should produce one traceable row. Then spot-check Restaurant_name, Address, Operating_hours, and Budget against the browser.
Runbook
How to scrape Tabelog restaurant details to CSV
Import the workflow
Open the related template page, download the hosted JSON, and import it into UScraper. Keep an unchanged copy of the original bundle for rollback.
Prepare the URL queue
Collect restaurant detail URLs for one project, area, cuisine group, or competitor set. Remove duplicates, tracking parameters, and pages that are not restaurant profiles.
Replace sample URLs
Open the Navigate block and paste your approved URLs into navigate.urls. Keep the first validation run to three to five pages.
Set the export path
In Structured Export, replace the bundled local save path with a writable project folder and confirm headers plus append mode.
Run visibly
Watch the browser open each Tabelog page. Stop if the site shows login, CAPTCHA, verification, or content you are not allowed to access.
Validate before scaling
Open the CSV, compare several rows with their source pages, then expand the URL list only when names, ratings, address, hours, and budget fields look correct.
Validation
Common issues when scraping Tabelog
| Symptom | Likely cause | Practical fix |
|---|---|---|
| CSV is empty | The page never reached the expected heading or the save folder is not writable | Run one URL, watch the browser, and update the export path. |
| Rating or reviewer count is blank | The page does not expose that value or the selector no longer matches | Treat optional fields as nullable and retest selectors on three URLs. |
| Address includes map helper text | The source table changed or cleaning logic missed a phrase | Adjust the Address column cleanup and rerun a sample. |
| Old rows are mixed with new rows | Append mode wrote into an existing file | Archive the previous CSV or change the filename before a new project. |
| Garbled Japanese text in a spreadsheet | The file was opened with the wrong encoding | Import the CSV as UTF-8 instead of double-clicking it. |
For a discovery-first workflow, pair this details scraper with the Tabelog Store List Scraper. For adjacent Japan restaurant sources, browse the UScraper template library or review other tutorials in the UScraper blog.
Alternatives
Tabelog scraper vs Octoparse, Apify, and Python
Octoparse offers Tabelog templates for store lists and detail pages, which can be convenient if your team already runs extraction there. Apify actors fit hosted runs, APIs, schedules, and cloud storage. A Tabelog scraping Python project fits engineering teams that need custom retries, tests, database writes, and repository-based review.
UScraper fits a different operating model: visible local browser runs, editable visual blocks, direct CSV custody, and analyst-friendly validation before scale.
| Approach | Best fit | Trade-off |
|---|---|---|
| UScraper template | Supervised local desktop workflow and direct CSV review | Not a hosted API or scheduler by default. |
| Octoparse template | Teams already using Octoparse projects | Different runtime, pricing model, and data custody path. |
| Apify actor | Hosted actor runs, API access, and scheduled jobs | More cloud configuration and third-party processing. |
| Python scraper | Engineering-owned pipelines and custom storage | Requires code maintenance when Tabelog changes. |
FAQ
Tabelog scraping FAQ
Tabelog pages may be publicly visible and still governed by source rules, robots directives, copyright, database rights, privacy law, and local regulations. Review current policies, keep runs modest, avoid bypassing access controls, and get legal review before commercial reuse or redistribution.