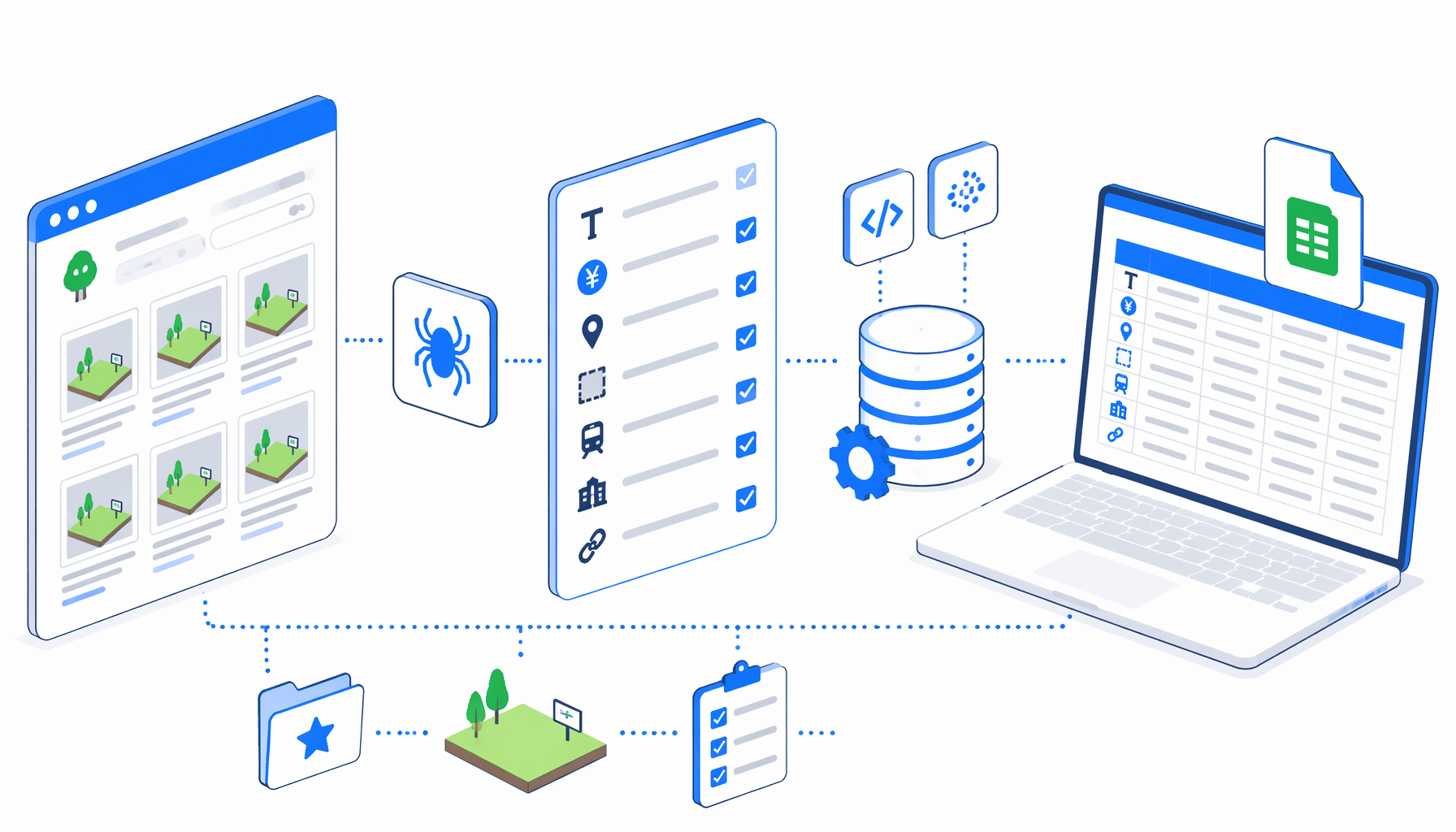
This tutorial shows how to scrape SUUMO land listings from search-result pages into CSV with the SUUMO Land Listings Scraper template for UScraper. Prepare a source URL, import the workflow, validate one page, then let pagination collect more land listing cards.
Before you start
Prerequisites for SUUMO land data extraction
You need UScraper installed as a local desktop app, the current SUUMO Land Listings Scraper template, and a writable CSV folder. You also need one focused SUUMO land search URL. Start from a page like the official SUUMO land-for-sale search and narrow it by area, station, price band, or another research filter.
Before automation, review the current SUUMO terms and crawler directives. This is a technical workflow, not legal advice.
Technical access is not permission. Do not bypass CAPTCHA, login walls, verification screens, rate limits, account controls, or other access restrictions. Keep collection narrow, documented, and proportionate to the research question.
Workflow anatomy
How the SUUMO land listings scraper works
The JSON export is the authoritative workflow definition. The template opens a SUUMO search-results URL, waits for listing cards, exports every visible .property_unit row, checks whether the Japanese 次へ next-page link exists, clicks it when present, and loops until no next page remains.
CSV
14
Next loop
Local review
One page first
| Workflow block | What it does | What to check |
|---|---|---|
| Navigate | Opens the configured SUUMO land search URL | Replace the sample URL. |
| Wait for page and element | Waits for .property_unit cards | Increase waits if rows look incomplete. |
| Structured Export | Appends one CSV row per listing card | Confirm filename, folder, headers, and append mode. |
| Element Exists | Checks for 次へ inside pagination | Stop if pagination loops. |
| Click + wait loop | Moves to the next result page | Validate page numbers and row counts. |
The template extracts from search pages because land inventory changes and detail URLs can expire. The export still keeps the detail URL when the card exposes it, so reviewers can open selected listings manually.
Runbook
How to scrape SUUMO property data to CSV
Review the source URL
Open the SUUMO land search page and confirm that the visible rows match the project scope. Save the exact URL beside your run notes.
Import the template
Open the SUUMO land listings scraper template, download the JSON workflow, and import it into UScraper.
Replace the Navigate URL
In the Navigate block, paste your approved SUUMO search URL. Keep one workflow copy per region when runs need separate audit trails.
Set the CSV folder
In Structured Export, confirm suumo-land-listings-scraper.csv, headers, append mode, and the local save location before running.
Run one page first
Export one page and compare several rows against the browser: title, price, location, access, land area, agency, phone, and URLs.
Expand after validation
When page one passes QA, allow the 次へ loop to append more pages. Stop if the same URL repeats or field values shift into the wrong columns.
Output
SUUMO land scraper CSV fields
There is no bundled CSV sample for this post, so use the export shape and the JSON workflow together. The JSON defines selectors, filename, append mode, and pagination. This table explains field intent.
| CSV column | What it captures | Validation note |
|---|---|---|
区別 | Static category value, set to land | Useful when joining with other SUUMO exports. |
タイトル | Listing card heading | Required for a usable row. |
詳細ページ_URL | Absolute detail URL when available | Open a few links manually before analysis. |
物件名 | Property or listing name | May be blank when the card does not expose it. |
販売価格 | Published sale price text | Preserve the original Japanese price text before normalization. |
所在地 | Address or location text | Spot-check ward, city, and prefecture. |
沿線_駅 | Rail line, station, and walking access | Treat as text unless you parse it later. |
専有面積 | Land area fallback from visible area fields | For land listings, validate that the value represents land area. |
間取り | Price per tsubo fallback | The label is inherited from a generic field slot, so document it. |
バルコニー | Building coverage and floor-area ratio fallback | Validate coverage/FAR before financial modeling. |
会員名, 電話番号 | Agency or member name and visible phone number | Some cards may not publish every contact field. |
Original_URL | Source search URL without the page parameter | Use it for audit, grouping, and reruns. |
suumo-land-listings-scraper.csvColumn
タイトル
Listing card title.
Column
詳細ページ_URL
Resolved detail URL.
Column
販売価格
Sale price text.
Column
所在地
Location text.
Column
沿線_駅
Line and station access.
Column
専有面積
Land area field.
Column
間取り
Price per tsubo fallback.
Column
バルコニー
Coverage and FAR fallback.
Column
会員名
Agency or member company.
Column
電話番号
Visible contact number.
Column
Original_URL
Normalized source URL.
Validation
Validate SUUMO land listing data before analysis
A SUUMO land data extraction run is only useful if the CSV survives spot checks. Open the CSV beside the browser while the first result page is fresh. Check the first, middle, and last rows. If pagination ran, repeat the check later.
Start with identity fields: title, detail URL, price, and location should point to the same listing. Then review area, agency, and phone fields. Unusual card layouts can produce blanks.
Alternatives
SUUMO scraper alternative: local app, cloud template, API, or code?
Searches for best SUUMO scraping tool usually compare operating models. Cloud templates, actors, scraper APIs, custom scripts, managed vendors, and a local desktop workflow can all be reasonable.
| Route | Best fit | Trade-off |
|---|---|---|
| UScraper template | Supervised CSV review, visible browser flow, editable local workflow | You own pacing, selector maintenance, and QA. |
| Cloud no-code template | Teams already standardized on hosted browser automation | Run context and data handling depend on the provider setup. |
| Actor, scraper API, or managed vendor | Scheduled jobs, API delivery, cloud datasets, contracted pipelines | Requires more governance, budget control, and production monitoring. |
| Custom Python or Selenium | Full control over parsing, storage, and retries | More code to maintain when SUUMO layout or access behavior changes. |
UScraper is a practical SUUMO scraper alternative when the deliverable is an analyst-reviewed CSV from a known search page. Use a managed provider or approved API when the project needs high-frequency refreshes, redistribution rights, or production integration.
FAQ
SUUMO land listings scraper FAQ
SUUMO land listing pages may be publicly visible and still governed by SUUMO terms, robots directives, copyright, database rights, privacy law, real estate rules, and local regulations. Review current rules, avoid restricted areas, and get legal advice before commercial reuse.
Next step
Start with the maintained template
Use this tutorial as the runbook, then download the SUUMO Land Listings Scraper template. Import the JSON, replace the sample URL, run one page, validate the CSV, and then collect additional pages. For adjacent workflows, browse all UScraper templates or the UScraper blog.