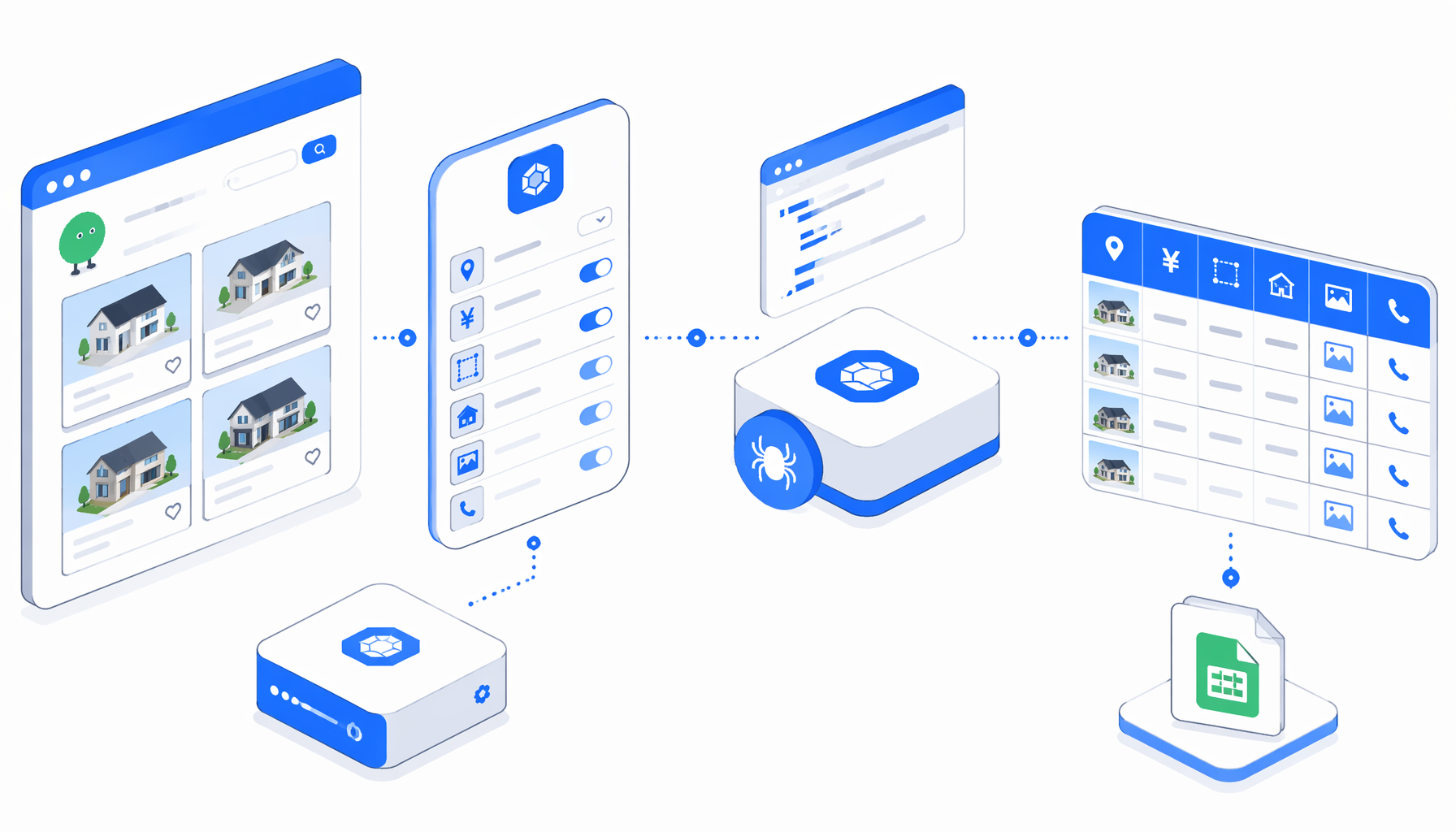
This tutorial shows how to scrape SUUMO detached-house detail pages into CSV with the SUUMO Detached House Details Scraper template. You will prepare current detail URLs, import the workflow, set the export path, validate Japanese property fields, and handle expired pages without building a scraper from scratch.
Before you start
Prerequisites for scraping SUUMO property details
You need UScraper installed as a local desktop app, the SUUMO Detached House Details Scraper template, a local export folder, and a short list of current SUUMO detached-house detail URLs you are allowed to process. The workflow is built for detail pages under paths such as suumo.jp/chukoikkodate/..., not broad search crawling or map exploration.
Start by collecting three to five live URLs from a saved shortlist, a manual search, or SUUMO's used detached house search entry point. Keep that first batch intentionally small. A short run proves that pages load, the export folder is writable, Japanese text is preserved in CSV, and the fields still match the current page layout.
Review SUUMO's current terms of use and your own data policy before automation. Public visibility is not unrestricted reuse, and real estate data can carry contractual, privacy, copyright, database, and downstream publishing constraints.
Technical access is not permission. Keep batches modest, collect only fields you need, stop when an access challenge appears, and keep source URLs beside the exported file.
Workflow
How the SUUMO scraper tutorial workflow works
The exported JSON is the authoritative workflow definition. In plain English, the flow is:
Set Window Size -> Navigate -> Wait for Page Load -> Sleep
-> Inject JavaScript -> Wait for Element -> Structured Export
-> Loop Continue
The Navigate block stores the detail URL list. Loop Continue advances through that list, so every successful iteration should map to one CSV row. There is no listing pagination in this template because the input is already a set of detail pages.
The JavaScript helper does three important things. First, it normalizes page text so Japanese labels and values are easier to compare. Second, it detects unavailable listings by checking the page title and body text for common expired-page signals. Third, it reads neighboring values for labels such as 所在地, 価格, 交通, 土地面積, 建物面積, 築年月, and 用途地域.
| Workflow stage | What it does | What to verify |
|---|---|---|
| Navigate | Opens each configured SUUMO detail URL | Replace bundled samples with current detail pages |
| Page guards | Waits for load, sleeps briefly, then waits for body | The real property page is visible |
| JavaScript helper | Detects unavailable pages and exposes label-based values | Japanese fields are not blank on active pages |
| Structured Export | Appends fixed CSV columns | Filename, headers, and local folder are correct |
| Loop Continue | Moves to the next URL | One intended row per URL is produced |
Runbook
How to scrape SUUMO detached house details to CSV
Import the workflow
Open SUUMO Detached House Details Scraper, download the JSON, and import it into UScraper.
Replace sample URLs
In Navigate, replace the bundled sample links with current SUUMO detached-house detail URLs. Keep the first validation batch short.
Keep the guards
Leave the page-load wait, one-second sleep, JavaScript helper, and body wait in place so each page can settle before export.
Set the CSV destination
In Structured Export, confirm suumo-detached-house-details-scraper.csv, headers, append mode, and the local save folder for this project.
Run and compare
Compare the first rows against the browser: price, location, transportation, land area, building area, zoning, member name, contact, and page_status.
Scale after QA
Add more URLs only after active pages export correctly and expired rows are understood. Use a dated folder or fresh CSV for repeat runs.
Because file mode is append, reruns add rows to the same CSV. Clear the file, change the filename, or use a dated folder before repeating a URL list.
Output
CSV fields from SUUMO detached house pages
The bundle does not include a static CSV sample. Use the export shape below together with the JSON workflow definition: the JSON controls the parser, while your first validation run proves that the fields still match today's SUUMO layout.
suumo-detached-house-details-scraper.csvColumn
property_url
The processed SUUMO detail URL from location.href.
Column
page_status
active_or_unknown or expired_or_unavailable.
Column
property_name
Cleaned H1, property heading, or page title.
Column
property_type
Published type or detached-house fallback for chukoikkodate URLs.
Column
price
Published sale price text.
Column
location
Address from 所在地 or 住所.
Column
transportation
交通 text with station, rail, bus, or walking details.
Column
floor_plan
間取り when available.
Column
land_area
土地面積 or 敷地面積.
Column
building_area
建物面積 or 建築面積.
Column
built_date
築年月, completion timing, or age text.
Column
zoning
用途地域 when published.
Column
image_1
First filtered property image URL.
Column
member_name
Broker, selling company, or information provider.
Column
contact
Published inquiry or telephone text when visible.
Column
extracted_at_1
ISO timestamp recorded during export.
For QA, sort by property_url and filter page_status. Active rows should have a name, price, location, and at least one area field. Expired rows can legitimately have blank property and image columns.
Tool choice
SUUMO scraper API alternative vs no-code tools
Searches like suumo scraper api alternative, best SUUMO scraping tool, and SUUMO property data scraping usually come from two different teams. One needs a governed feed or hosted API. The other needs a reviewable spreadsheet from a known list of property URLs.
Use UScraper when you want a local, inspectable no-code workflow for selected SUUMO detached-house detail URLs and CSV output.
The practical wedge for this tutorial is narrow on purpose: known SUUMO detached-house detail URLs in, CSV out, with visible QA before scale.
Troubleshooting
Common SUUMO scraping issues
| Symptom | Likely cause | Fix |
|---|---|---|
expired_or_unavailable rows | Listing expired or the page did not expose property content | Keep the row for audit, then replace the URL with a current detail page |
| Blank price or area fields | Labels moved, page layout changed, or the page did not render fully | Inspect one active URL and update the label list or waits |
| Repeated rows | Append-mode rerun or duplicate source URLs | Dedupe by property_url and clear the CSV before reruns |
| Image columns contain no URLs | Expired page, image module blocked, or filtering removed non-property assets | Check the browser page and adjust image filters only if needed |
| Japanese text looks broken | Spreadsheet opened the CSV with the wrong encoding | Import as UTF-8 instead of double-clicking in an older spreadsheet workflow |
FAQ
SUUMO scraper FAQ
SUUMO pages can be visible in a browser and still be governed by terms, robots directives, copyright, database rights, privacy rules, and real estate data rules. Review current source policies, keep runs modest, avoid bypassing access controls, and get legal review before commercial reuse.
Next step
Download the SUUMO detached house scraper template
Use SUUMO Detached House Details Scraper as the download path, then keep this tutorial open while you validate the first CSV. For adjacent workflows, browse all UScraper templates or return to the UScraper blog.