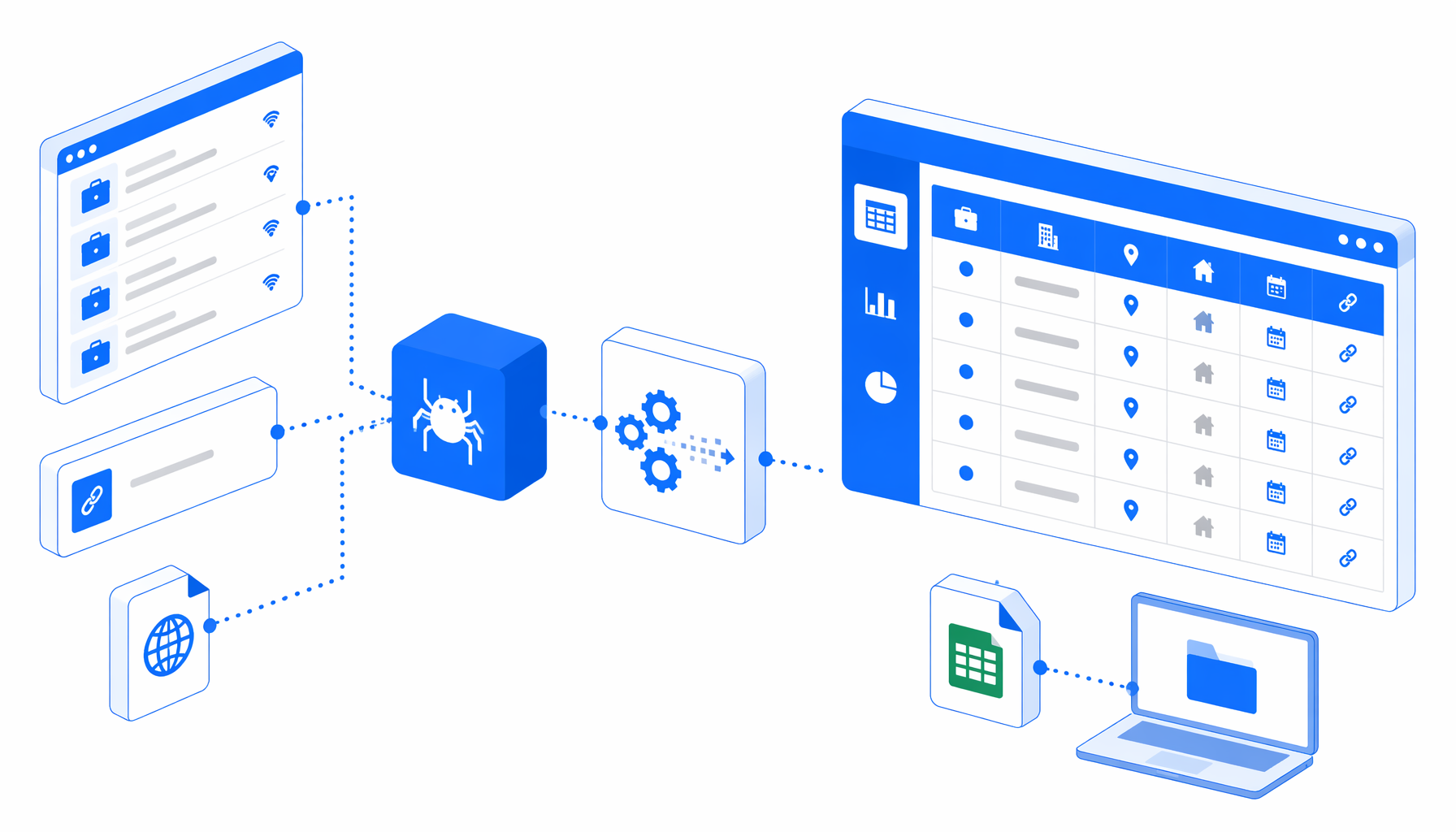
A Stepstone listing scraper is useful when a team has specific search URLs and needs repeatable Stepstone job data extraction, not a full job-board mirror. The Stepstone Listing Scraper by URL turns approved Stepstone listing pages into a local CSV with job titles, company names, locations, home-office signals, descriptions, publish timing, job URLs, and logo URLs.
Use-case fit
Why Stepstone job data matters for market analysis
Stepstone listings are not just recruiting leads. They are visible signals about hiring demand, role wording, work-location expectations, employer activity, and how fast job markets are moving. Stepstone's own newsroom uses platform data in labor-market analysis, including its 2026 salary report based on more than 1.3 million data points and a 2026 career-change listings analysis.
For most teams, the useful question is narrower than "how to scrape Stepstone jobs at scale?" It is: "Can we turn these Stepstone search results into rows our team can audit?" A clean export helps recruiters, journalists, SEO teams, and analysts work from the same evidence.
A job listing export is useful only when every row keeps its source URL. Without the URL, the row becomes a loose claim instead of evidence someone can verify.
Personas
Who uses a Stepstone job listing scraper?
| Persona | Pain | Useful CSV outcome |
|---|---|---|
| Recruiting research | Browser tabs make it hard to compare employers across cities and role filters. | Sort titles, companies, locations, home-office text, and publish timing before manual outreach or enrichment. |
| Newsrooms | Labor-market stories need evidence from visible listings, not screenshots scattered across reporters' notes. | Preserve job URLs, description snippets, employer names, and locations for editorial checking. |
| SEO teams | Job-board pages reveal how employers phrase roles, benefits, remote work, and location intent. | Build content briefs from job titles, descriptions, city wording, and home-office signals. |
| Monitoring teams | Weekly listing snapshots are tedious when copied by hand. | Re-run the same URLs and compare new, removed, or changed rows after dedupe. |
| Market analysts | Keyword-based searches need structured output before charting or segmentation. | Export one row per listing card, then group by role, region, employer, or posting freshness. |
Workflow
How the URL workflow turns listings into CSV
The bundled workflow is listing-focused. It opens one or more Stepstone search URLs, waits for the page, handles common consent prompts, waits for visible job cards, exports rows, checks for a Next, Weiter, or Naechste pagination control, and appends later pages to the same CSV.
The JSON export is the authoritative sample of the workflow definition. Its Structured Export block writes stepstone-listing-scraper-by-url.csv with these columns:
{
"fileName": "stepstone-listing-scraper-by-url.csv",
"fileMode": "append",
"columns": [
"job_titel",
"titel_url",
"name_des_unternehmens",
"standort",
"home_moeglich",
"job_beschreibung",
"erscheinen",
"image_url"
]
}
| Column | Why it matters |
|---|---|
job_titel | Role naming, seniority clues, and keyword analysis. |
titel_url | Source traceability and dedupe key. |
name_des_unternehmens | Employer activity and account targeting. |
standort | City, region, and location clustering. |
home_moeglich | Remote, home-office, or mobile-work signal when visible. |
job_beschreibung | Short listing text for classification and manual review. |
erscheinen | Freshness signal for monitoring. |
image_url | Employer logo or listing image context when available. |
Because Stepstone pages use dynamic generated classes, the selectors rely on fallback patterns such as job-card containers, links containing /stellenangebote--, visible text, and common location or home-office phrases. Treat the first run as calibration.
Collect URLs
Build a narrow list of Stepstone search URLs your team is allowed to process.
Import template
Add the Stepstone template to the UScraper local desktop app and replace the sample Navigate URLs.
Run a small test
Export the first page, open the CSV, and compare several rows with the browser.
Let pagination append
When rows look correct, allow the Next or Weiter loop to collect later pages into the same CSV.
Analyze and archive
Deduplicate by job URL, add a run date, and store the CSV with notes about filters and source URLs.
Options
Stepstone API vs scraper alternatives
There is no universal stepstone scraper alternative. The right route depends on permission, scale, custody, and whether the output is research evidence or production infrastructure.
| Route | Best fit | Trade-off |
|---|---|---|
| Official StepStone API or Jobfeed | Sanctioned integrations, employer posting workflows, feed relationships, and production systems. | Requires the right access path and integration work; start with the StepStone API knowledge base when this is the business requirement. |
| Commercial job data feed | Large recurring datasets, normalized schemas, and analytics pipelines. | Higher vendor dependency; useful when the job is ongoing ingestion rather than a one-off research batch. |
| Hosted scraper API | Developer teams that want cloud scheduling, proxy handling, or API delivery. | Easier to scale, but data custody, run logs, pricing, and retries live inside the vendor model. |
| Custom script | Engineering teams that need parser ownership, tests, queues, and deployment control. | Highest control and highest maintenance cost when Stepstone changes layout. |
| UScraper template | URL-based research, newsroom checks, SEO audits, monitoring snapshots, and local CSV review. | Best for controlled batches; not a replacement for official access or guaranteed large-scale feeds. |
Examples
Concrete Stepstone scraper workflows
A recruiting analyst tracks customer-service listings in Germany. The export is grouped by employer, location, publish timing, and home-office signal, then shortlisted for manual review.
Pair this workflow with the UScraper template library for adjacent sources, or browse the UScraper blog for more scraper use cases.
Guardrails
Compliance and quality guardrails before you run
Review Stepstone's current robots.txt and general terms of use before collecting data. Robots rules, page access, terms, privacy obligations, database rights, and copyright can all affect what you should do with automated output. This article is a workflow guide, not legal advice.
Quality matters too. Keep runs modest, avoid bypassing access controls, save the source URL with every row, and do not treat blank fields as zero values. A missing home_moeglich value may mean the card did not mention remote work, the layout changed, or the selector missed a field.