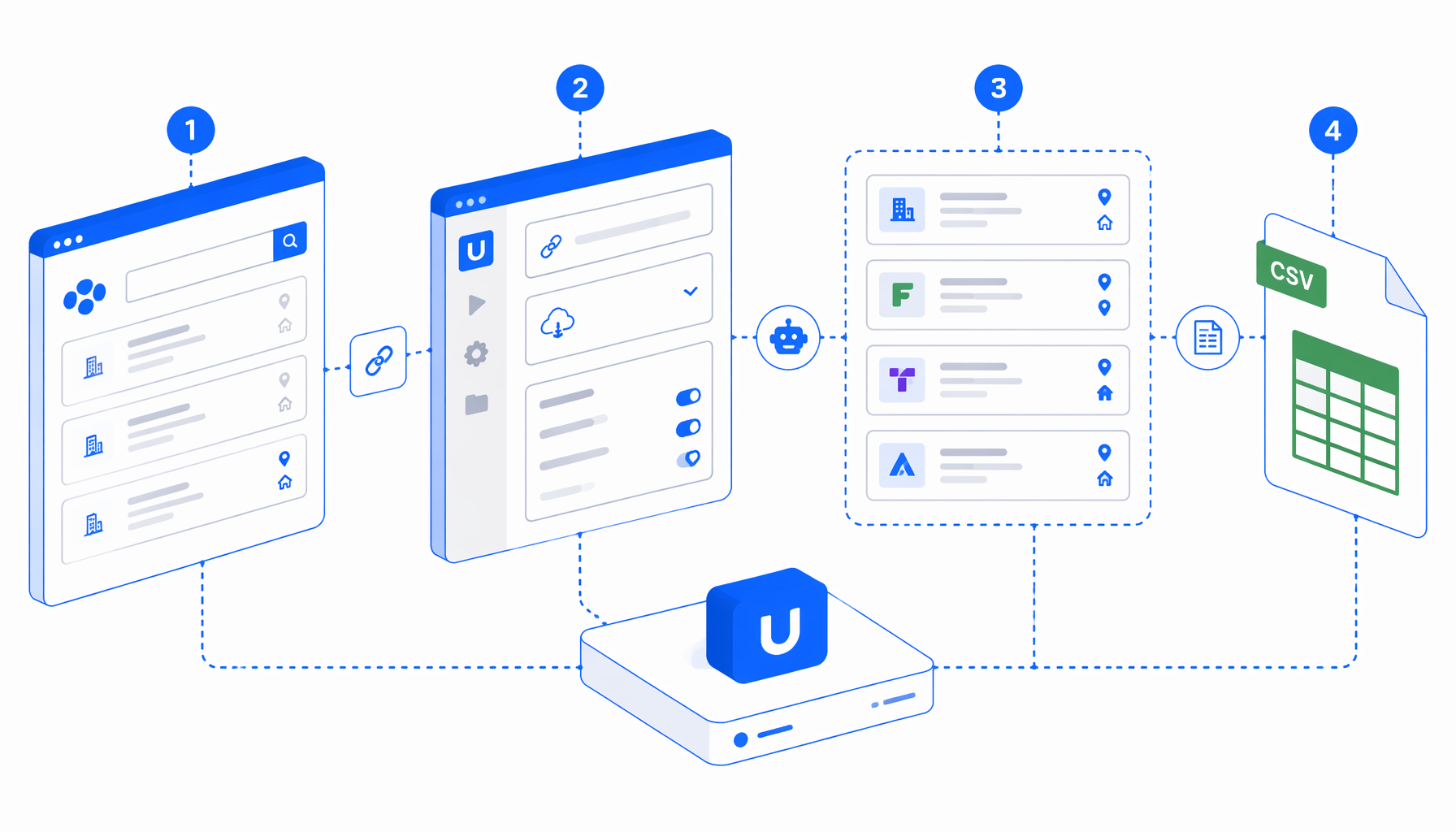
This Stepstone job scraper tutorial shows how to turn Stepstone Germany listing or search URLs into a structured CSV with the Stepstone Listing Scraper by URL template for UScraper. You will import the workflow, replace URLs, set the export path, run pagination, and validate rows.
Before you start
Prerequisites, scope, and policy checks
You need UScraper installed as a local desktop app, a Stepstone listing or search URL you are allowed to process, and a project folder for the CSV export. Start with one narrow query, such as a single role and city, so the first run proves the row shape before you widen the batch.
This guide covers public listing-result cards. It does not cover candidate data, employer dashboards, logged-in pages, applications, CAPTCHA bypassing, or private account areas. Before recurring exports, review the current Stepstone robots.txt, Stepstone terms, and your legal basis for collecting job-board data.
A scraper is a collection method, not a permission model. Keep runs deliberate, document why the data is needed, and use approved API or partner routes when the use case requires contractual access.
API or scraper
Stepstone API alternative: when scraping fits
Stepstone publishes API and XML JobFeed documentation for approved integration workflows. That route is better when you have Stepstone-side access, need stable contracts, or are posting and managing jobs through a governed channel.
The UScraper template solves a different problem: scrape Stepstone job listings that already render in your browser and turn them into a spreadsheet for recruiting research, labor-market snapshots, competitor hiring checks, or internal analysis.
| Approach | Best fit | Trade-off |
|---|---|---|
| UScraper template | Browser-visible listing URLs, CSV research batches, operator QA | Selectors and waits may need updates when Stepstone changes layout. |
| Official Stepstone API or JobFeed | Approved integrations, posting workflows, governed exchange | Requires access, onboarding, and API implementation. |
| Hosted scraping tools | Cloud scheduling, API delivery, managed infrastructure | Output shape, pricing, retries, and data custody depend on the vendor. |
| Python or Selenium scraper | Full engineering control | You own pagination, blocking states, tests, selectors, and maintenance. |
Workflow anatomy
How the Stepstone listing scraper by URL works
The JSON export is the authoritative workflow definition. In plain English, the flow is:
Set Window Size -> Navigate -> Wait for Page Load -> clear consent
-> Wait for listing cards -> Structured Export -> check Next/Weiter
-> click pagination -> wait -> export again -> continue next URL
The Navigate block contains multiple Stepstone search URLs. Structured Export reads one visible listing card per row and writes the same CSV in append mode. Pagination is click-based: the workflow checks for enabled Next, Weiter, or Naechste controls, clicks when a next page exists, waits again, then returns to export.
Because Stepstone can generate class names dynamically, the workflow uses practical selectors and JavaScript fallbacks: job links containing /stellenangebote--, card containers such as article, visible company and location text, home-office phrases, time elements, and image URLs.
| Workflow block | What it does | Validation point |
|---|---|---|
| Block | What to check | Why it matters |
| --- | --- | --- |
| Navigate | Approved Stepstone URLs replaced the samples | Input URLs define the batch. |
| Structured Export | Headers, append mode, and save folder are correct | Prevents mixed or misplaced CSVs. |
| Pagination loop | Next/Weiter advances to a new page | Prevents repeated job URLs. |
Runbook
How to scrape Stepstone job listings to CSV
Import the template
Open the Stepstone Listing Scraper by URL page, download the JSON workflow, and import it.
Replace the listing URLs
In Navigate, replace the bundled examples with your own Stepstone search URLs. Keep one URL per input.
Confirm waits and consent handling
Leave the page-load wait, consent JavaScript, sleep, and listing-card wait in place for the first run.
Set the export destination
In Structured Export, confirm the filename, headers, append mode, and a project-specific local save folder.
Run one page, then widen
Run one URL, compare rows against the browser, then add more URLs after key fields look correct.
Output
What the Stepstone CSV export includes
The export shape is German because it mirrors the template columns, which makes the CSV easy to compare against Stepstone.de pages.
stepstone-listing-scraper-by-url.csvColumn
job_titel
Visible job title.
Column
titel_url
Absolute job detail URL.
Column
name_des_unternehmens
Company name.
Column
standort
Location label.
Column
home_moeglich
Remote or home-office phrase.
Column
job_beschreibung
Card description or teaser.
Column
erscheinen
Publish time or date phrase.
Column
image_url
Logo or image URL.
After the first run, sort by titel_url, check duplicates, and open several detail URLs manually. Blanks in standort, home_moeglich, or erscheinen are not always errors; some cards omit fields.
Troubleshooting
Common Stepstone scraping issues
Confirm the browser reached a normal result page and cards include links with /stellenangebote--. Fix consent, verification, or no-results states before changing columns.
FAQ
Stepstone job scraper FAQ
Is it legal to scrape Stepstone job listings?
Stepstone listings may be visible in a browser, but automated collection can still be limited by terms, robots directives, privacy law, copyright, database rights, and local rules. Avoid bypassing access controls and get legal advice before commercial reuse.
Do I need the Stepstone API for this tutorial?
No. The workflow opens supplied listing URLs and exports visible job-card fields. Official Stepstone API or JobFeed routes are better when you have approved integration access and need a governed data contract.
What does the Stepstone listing scraper export?
The CSV is named stepstone-listing-scraper-by-url.csv and includes job_titel, titel_url, name_des_unternehmens, standort, home_moeglich, job_beschreibung, erscheinen, and image_url.
Why are some Stepstone fields blank?
Blank fields usually mean the card did not expose that value, a prompt changed the page, filters produced a different layout, or Stepstone changed markup. Run one page first and compare the CSV against the browser.
Where does the Stepstone CSV go?
The stock template writes the CSV to the folder configured in Structured Export. Because the workflow runs locally, the file stays on the machine or folder you choose unless you add sync or upload steps.
Next step
Download the Stepstone scraper template
Use the Stepstone Listing Scraper by URL template as the import path, then return here while you configure URLs and validate the first export. For adjacent workflows, browse the UScraper template library or the UScraper blog.