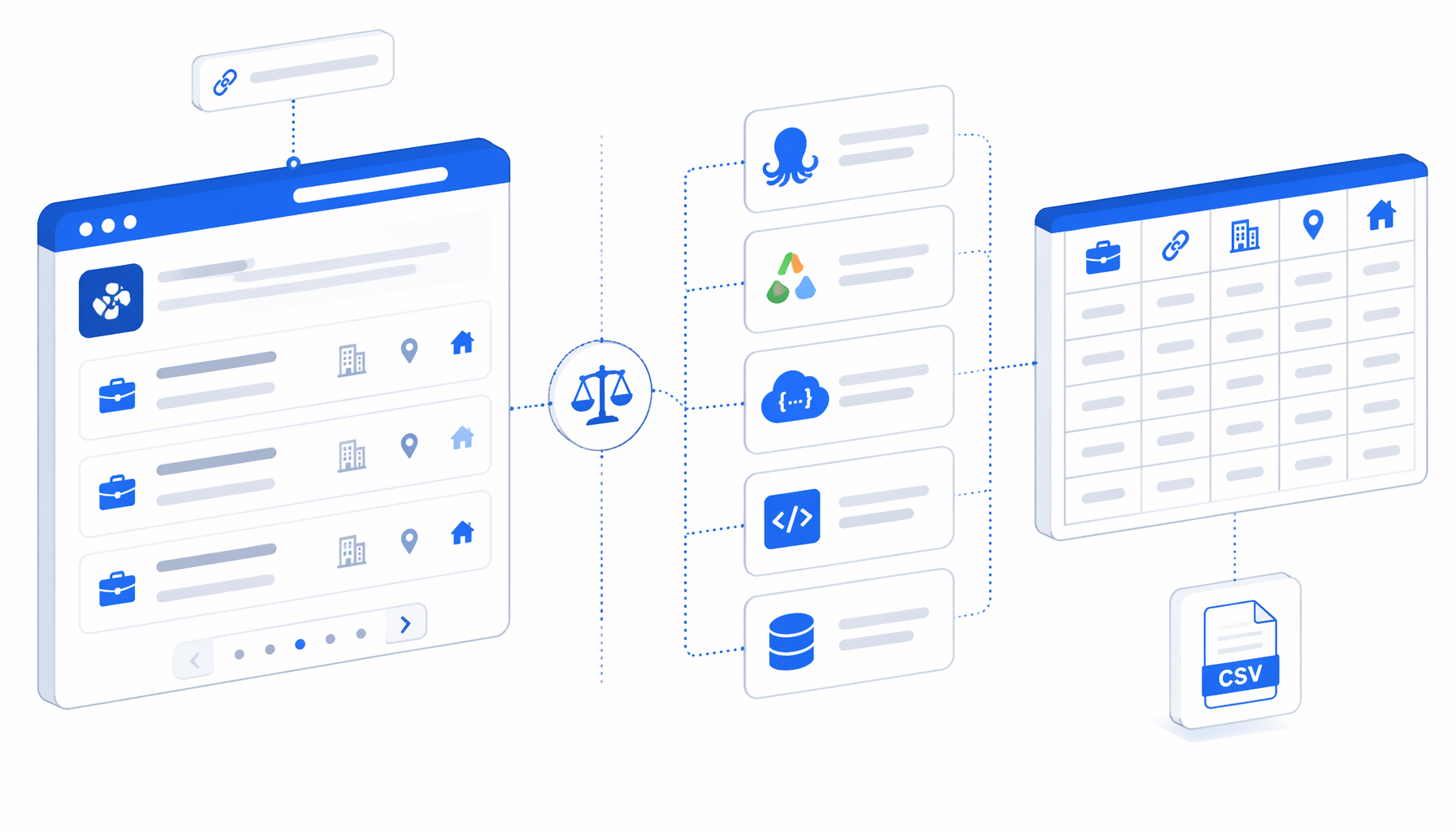
The best Stepstone scraper is not just the tool that collects the most rows. For recruiting research and labor-market monitoring, the right choice depends on permission, hosting, pricing, code tolerance, and whether the deliverable is an auditable CSV. This comparison covers Octoparse, Apify, scraper APIs, scripts, and UScraper's Stepstone Listing Scraper by URL.
Comparison frame
What a Stepstone jobs scraper has to solve
Stepstone listings look simple until you need repeatable rows. A useful Stepstone jobs scraper has to handle consent prompts, rendered cards, German and English pagination labels, dynamic class names, missing fields, and links that can expire. Most searches for "how to scrape Stepstone" end up comparing official access, Apify-style actors, Octoparse-style no-code tools, scraper APIs, scripts, and local desktop workflows.
The practical question is not "can this scrape Stepstone?" It is "which workflow creates rows you can legally use, explain, maintain, and afford?"
Side-by-side
Stepstone scraper alternatives compared
| Option | Best fit | Hosting | Code needed | Output shape | Pricing shape | Main trade-off |
|---|---|---|---|---|---|---|
| Official StepStone API / feed | Approved job posting, apply, or partner integrations | StepStone-approved API route | Developer integration | Contracted XML, feed, or API payloads | Commercial relationship dependent | Strongest permission route, not a quick public listing export |
| Octoparse Stepstone templates | No-code teams that prefer hosted visual extraction | Vendor cloud | Low | Cloud table, CSV, Excel-style exports | SaaS plans and task limits | Fast setup, but vendor-hosted execution |
| Apify Stepstone actors | Recurring cloud jobs, datasets, APIs, and orchestration | Apify cloud | Low to medium | Dataset, JSON, CSV, XLSX, API access | Platform plus actor or usage meters | Strong automation, less local custody |
| Scraper APIs | Software teams that want browser and proxy infrastructure abstracted | Vendor infrastructure | Medium | API responses your code stores | Request, credit, browser, or plan pricing | Infrastructure is handled, but parsing and compliance remain yours |
| Open-source scripts | Engineering-owned pipelines, tests, and custom storage | Your infrastructure | High | Whatever your code writes | Engineer time plus browser/proxy/storage cost | Maximum control, maximum maintenance |
| UScraper + Stepstone Listing Scraper by URL | Analyst-led exports from known listing/search URLs | Local desktop app | Low | CSV with 8 job listing fields | Free template; app license, not per-record cloud metering | Best for inspectable local CSV work, not fleet-scale scraping |
Where UScraper wins
When the local desktop app approach is the better fit
The UScraper workflow is narrow: open Stepstone listing/search URLs, wait for job cards, handle common consent prompts, export fields, click Next, Weiter, or Naechste pagination, and append all pages into one CSV.
The companion Stepstone Listing Scraper by URL template exports the fields defined in the bundled workflow JSON:
| UScraper column | What it captures | Why it matters |
|---|---|---|
job_titel | Visible job title or main link text | Row identity and dedupe. |
titel_url | Absolute Stepstone job detail URL | Source verification. |
name_des_unternehmens | Company name | Employer analysis. |
standort | City, region, or country text | Market coverage. |
home_moeglich | Home-office, remote, hybrid, or mobiles Arbeiten text | Flexible-work signals. |
job_beschreibung | Listing teaser or card text | First-pass classification. |
erscheinen | Visible publish time or datetime value | Freshness review. |
image_url | Logo or listing image URL | QA and enrichment. |
The main advantage is inspectability. You can see the Navigate block, waits, consent handler, export columns, row selector, pagination condition, and save location. If Stepstone changes markup, a non-engineer can still inspect what failed.
Where cloud wins
When Octoparse, Apify, scraper APIs, or scripts make more sense
Choose Octoparse for hosted no-code extraction and cloud exports. Choose Apify for scheduled cloud runs, datasets, logs, APIs, queues, proxy settings, and developer orchestration. Choose a scraper API or managed provider when engineers want browser and proxy infrastructure handled by a vendor. Choose scripts when developers need tests, queues, retries, and custom database writes. The hidden cost is not the first script; it is selector maintenance after the site changes.
UScraper is strongest when a bounded CSV workflow should run without per-row cloud metering. Hosted tools are easier to justify when retries, scale, and shared datasets are worth the usage meter.
API and compliance
Is a Stepstone scraper API the same as the official API?
No. Treat them as different categories.
The official StepStone API and job-feed route is for approved integrations, customer feeds, application flows, and contractual exchange. Third-party Stepstone scraper API products usually extract visible pages and return structured data.
Official access is about permission and integration. Scraper APIs are about extraction infrastructure. For redistribution, job aggregation, public datasets, or legal exposure, review StepStone's terms, robots directives, contractual rights, privacy obligations, and local law.
Decision guide
Which Stepstone scraping tool should you pick?
Pick official StepStone API or feed access for approved integrations. Pick Octoparse for hosted no-code scraping. Pick Apify for recurring cloud jobs, datasets, and API automation. Pick scraper APIs when your software needs extraction infrastructure. Pick scripts when engineers need complete control and accept maintenance.
Pick UScraper when the job is narrower and more reviewable: import the free template, paste approved Stepstone listing URLs, run a small test, inspect the CSV, then scale only as far as your use case allows. Start with the Stepstone Listing Scraper by URL template, browse more job-board workflows in the UScraper template library, or compare related extraction guides from the UScraper blog.
FAQ
FAQ
What is the best Stepstone scraper alternative?
It depends on scale, permission, hosting, and output. Use official StepStone access for approved integrations, Apify or scraper APIs for hosted automation, Octoparse for hosted no-code scraping, scripts for engineering-owned pipelines, and UScraper for local CSV workflows.
How does UScraper compare with Octoparse for Stepstone?
Octoparse provides hosted no-code Stepstone templates and cloud exports. UScraper runs in a local desktop app, exposes the visual block flow, and writes CSV to a configured folder. Octoparse is stronger for vendor-hosted tasks; UScraper is stronger for local custody and inspectable selectors.
Should I use an Apify actor or a local desktop app for Stepstone scraping?
Use Apify when you need cloud runs, datasets, APIs, scheduling, and developer orchestration. Use UScraper when an analyst needs to open known listing URLs, inspect the browser run, adjust waits or selectors, and export CSV without building a hosted pipeline.
Is there a Stepstone scraper API?
Yes, but separate official access from scraper infrastructure. StepStone has official API and feed documentation for approved customers and partners. Third-party scraper APIs can collect visible job pages, but they are not the same as an official StepStone integration and should be reviewed for terms, data rights, pricing, and reliability.
Is it legal to scrape Stepstone job listings?
It depends on permission, jurisdiction, fields, volume, and downstream use. Review current StepStone policies, robots directives, copyright, privacy rules, database rights, and local law. Do not bypass access controls, and get legal advice before commercial use.