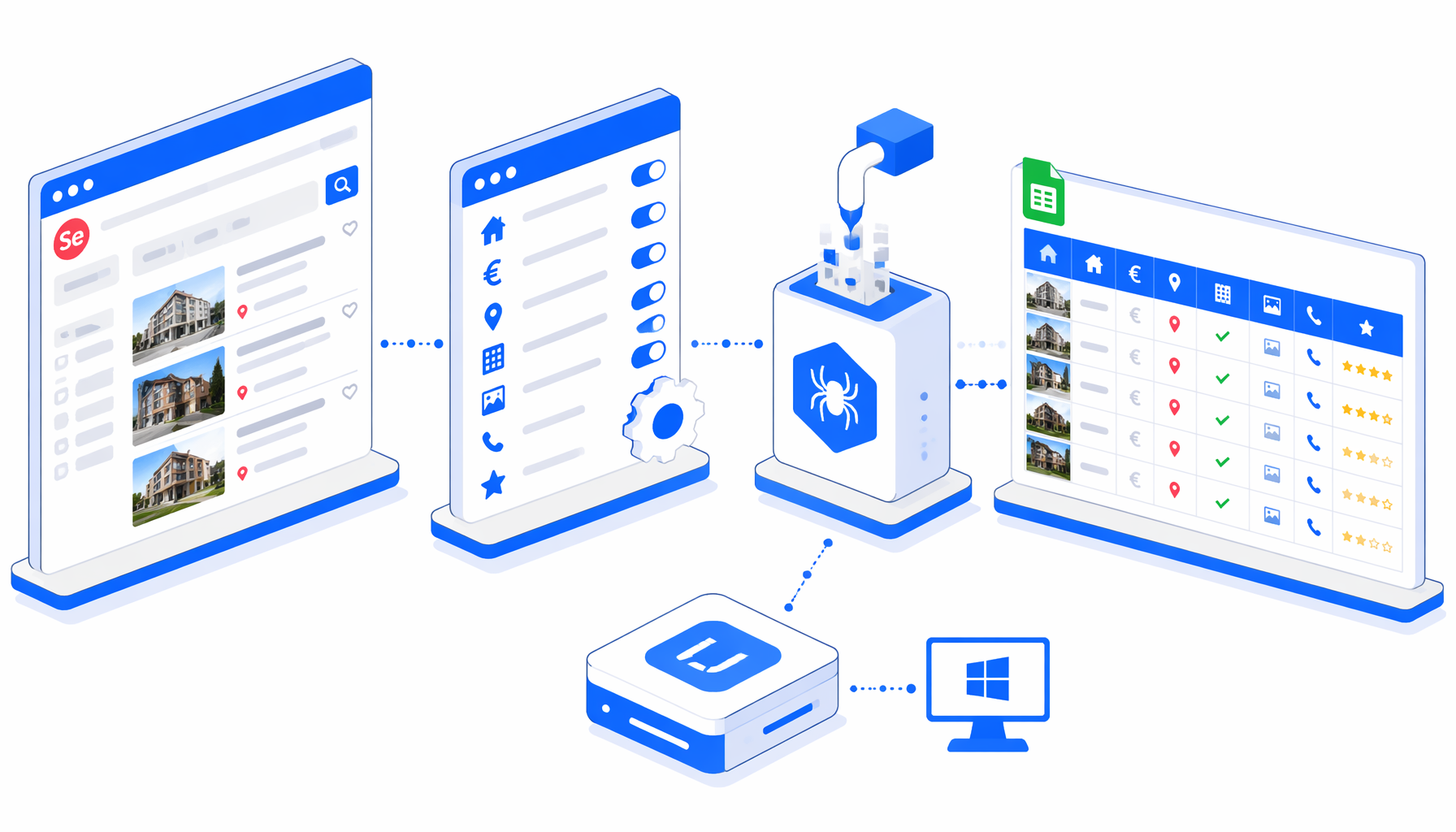
This SeLoger scraper tutorial shows how to scrape SeLoger sale listing detail pages into CSV with the SeLoger Scraper for Sale Listings CSV template for UScraper. You will review access rules, import the workflow, replace sample property URLs, set the export path, run one validation page, and decide when a SeLoger API alternative is a better fit.
Before you start
Prerequisites and SeLoger access checks
You need UScraper installed as a local desktop app, the SeLoger sale listings scraper template, a writable export folder, and a short list of SeLoger property detail URLs you are allowed to process. This template is designed around known detail pages, not broad discovery from search pages.
Before running any SeLoger scraping tools, review the official SeLoger robots.txt and SeLoger terms of use. The robots file includes disallowed paths for several listing, API, search, and query patterns, while the CGU defines the conditions for using the site and app. Treat those rules as part of the project brief, not as an afterthought.
Technical access is not the same as permission. Keep the first run visible, stop on verification pages, and document why each URL is being collected.
Workflow shape
What the SeLoger scraper template does
The JSON export defines a compact browser workflow:
Navigate -> Wait for Page Load -> Sleep -> Inject JavaScript
-> Sleep -> Wait for Element -> Structured Export -> Loop Continue
Navigate holds the input property URLs. The wait blocks give the listing page time to render. The JavaScript interaction step clicks likely consent, "see more", and phone reveal controls when they are visible. Structured Export reads the current page and appends a row to the CSV. Loop Continue advances to the next URL in the list.
| Export area | CSV columns | Validation check |
|---|---|---|
| Agency and contact | agences_immobilieres, telephone, rating | Confirm the agency and phone are visible in the browser before expecting them in CSV. |
| Price | prix_total, prixunitaire_m2 | Compare currency, spacing, and price per m2 against the listing page. |
| Property facts | type_de_logement, tag, annee_de_construction, exposition, ascenseur | Optional facts vary by property type, so blank cells can be normal. |
| Location and copy | adresse, description, description_du_professionnel | Check address granularity and long text truncation before importing into a CRM. |
| References | url_du_page_detaille, photo | Store the page URL for auditability and treat photo URLs as references, not licensed media. |
Runbook
How to scrape SeLoger listings to CSV
Review the source pages
Open each target SeLoger detail URL manually. Remove expired listings, blocked pages, account-only pages, and URLs outside the scope you are allowed to collect.
Import the workflow
Open the template page from the UScraper templates library, download the JSON workflow, and import it into the desktop app.
Replace sample URLs
In the Navigate block, replace the three sample SeLoger URLs with your approved detail pages. Keep the first batch to one to three URLs.
Set the export path
In Structured Export, confirm seloger-scraper-bien-a-vendre.csv, headers enabled, append mode, and a folder that is specific to this project.
Run and inspect
Run one URL while watching the browser. Compare agency, price, price per m2, address, description, photo, phone, and rating against the live page before adding more URLs.
If the first row is clean, add URLs in small batches. If the row is empty or partial, do not immediately scale. Reopen the browser tab, check whether a consent layer, DataDome check, CAPTCHA, removed listing, or phone reveal gate changed the page state.
Output
Export shape and sample workflow definition
There is no bundled CSV sample for this template, so the JSON workflow is the authoritative sample. The extraction intent is: open supplied SeLoger sale detail pages and export property information equivalent to an Octoparse-style sale listing template.
{
"fileName": "seloger-scraper-bien-a-vendre.csv",
"fileMode": "append",
"columns": [
"agences_immobilieres",
"prix_total",
"prixunitaire_m2",
"type_de_logement",
"tag",
"adresse",
"description",
"url_du_page_detaille",
"description_du_professionnel",
"annee_de_construction",
"exposition",
"ascenseur",
"photo",
"telephone",
"rating"
]
}
Append mode is useful for multi-URL runs, but it can also preserve bad test rows. During validation, use a clean folder, a dated filename, or delete the first test CSV after you confirm the selectors.
Alternatives
SeLoger API alternatives and scraping tools
ScrapFly has a developer tutorial focused on Python, reverse engineering, JSON parsing, and anti-blocking. Octoparse publishes a SeLoger "biens a vendre" template that extracts price, room, description, and related listing fields from URL input. Apify actors expose SeLoger extraction through cloud runs and APIs. Lobstr, ScrapingBee, and Piloterr position SeLoger endpoints as API-style data products.
| Option | Best fit | Trade-off |
|---|---|---|
| UScraper template | Analysts who want a visible desktop run and local CSV export | You maintain selectors and access state when SeLoger changes. |
| Python scraper | Developers who need custom parsing and version-controlled code | Requires engineering time, dependency updates, and anti-bot handling. |
| Hosted actor or API | Teams that need cloud scheduling or developer integration | Pricing, account setup, data custody, and provider limits vary. |
| Manual copy-paste | One-off checks with a handful of properties | Slow, inconsistent, and hard to audit. |
Use UScraper when the task is a controlled research export from known URLs. Choose an API provider when you need service-level guarantees, managed infrastructure, or integration into a production system.
Troubleshooting
Common issues when scraping SeLoger
The page may not have finished rendering, the listing may be unavailable, or SeLoger may have returned a consent, DataDome, CAPTCHA, or device-check state. Run one URL visibly, wait for the property content, then export again.
FAQ
FAQ
Is it legal to scrape SeLoger listings?
SeLoger pages can be publicly reachable and still governed by terms, robots guidance, database rights, privacy rules, and anti-abuse controls. Review the official rules, keep volumes modest, avoid bypassing access controls, and get legal review before commercial reuse or redistribution.
Do I need a SeLoger API for this tutorial?
No. This tutorial uses supplied detail-page URLs and a UScraper workflow that exports to CSV. Use an official or licensed API route when you need contractual access, service levels, redistribution rights, or production integration.
What does the SeLoger scraper export?
The template exports agency, total price, price per m2, property type, feature tags, address, description, detail URL, professional description, construction year, exposure, elevator, photo, phone, and rating.
Why are some SeLoger fields empty?
Empty fields usually mean the listing did not expose that section, the page showed a consent or verification state, the phone was not revealed, or SeLoger changed part of the page structure. Validate in the browser before scaling.
How many SeLoger URLs should I run at once?
Start with one to three detail URLs, inspect the CSV, and only add small batches after the exported rows match the live pages. Practical scale depends on permission, pacing, page availability, anti-bot checks, and selector maintenance.
Next step
Download the SeLoger scraper template
Open the SeLoger Scraper for Sale Listings CSV template, import the JSON into UScraper, and run one approved detail URL as a validation pass. You can browse more ready-made workflows in the templates library or return to the UScraper blog for comparison and scraping tutorials.