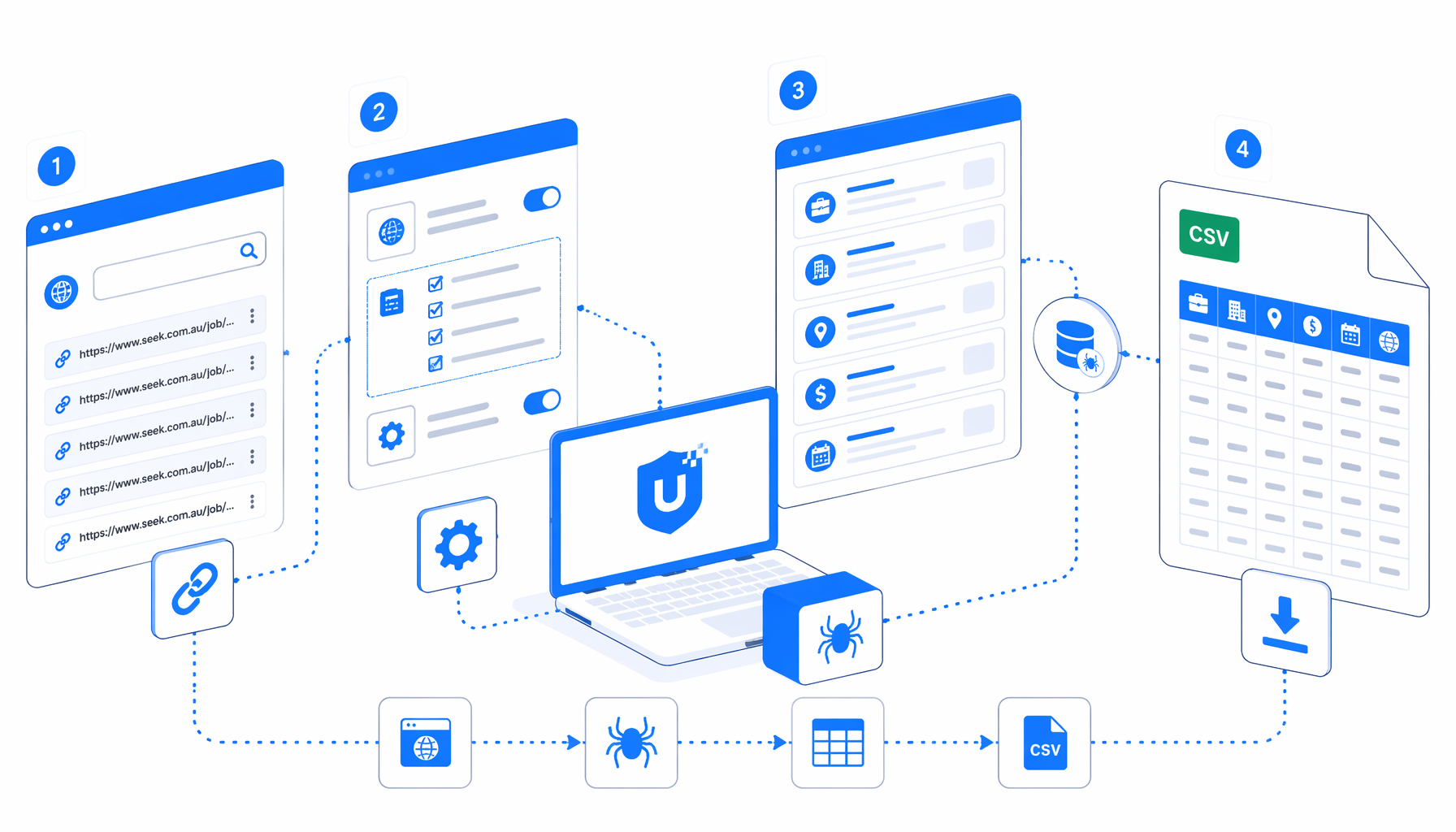
This SEEK job scraper tutorial shows how to turn approved SEEK Australia search or listing URLs into a structured CSV with the SEEK Job Scraper by URL template for UScraper. You will prepare the input URL, import the workflow, set the export path, run pagination, and validate the file before using it for recruiting research.
Before you start
Prerequisites, scope, and policy checks
You need UScraper installed as a local desktop app, a SEEK listing URL you are allowed to review, and a folder for the export. Start from the official SEEK Australia jobs page, apply the keyword, classification, location, salary, work type, remote, and listed-time filters you actually need, then copy the final browser URL.
This tutorial covers public search-result and listing pages. It does not cover employer dashboards, candidate records, private account pages, applications, messages, login-only data, CAPTCHA bypassing, or any attempt to defeat access controls. Before recurring runs, review the current SEEK robots.txt, the SEEK terms, and your own legal basis for collecting job data.
A scraper is an extraction method, not a permission model. Keep runs modest, document why the data is being collected, and stop when the site asks for verification.
Workflow anatomy
How the SEEK listing scraper by URL works
The JSON export is the authoritative workflow definition. In plain English, the flow is:
Navigate -> Wait for Page Load -> Sleep -> Confirm job cards
-> Structured Export -> Detect Next URL -> Navigate Next -> repeat
The Navigate block owns the input list. You can use one URL for a narrow role search or several URLs for different locations, classifications, or salary filters. The row guard checks for SEEK job-card articles before exporting, so the workflow does not write blank rows when a page has no visible listings.
Pagination is handled by JavaScript URL navigation instead of a fragile button click. The workflow reads enabled Next links, writes the next URL into a hidden marker, moves to that URL, waits for the page, and loops until no safe next page remains. That design is useful on pages where sticky headers, overlays, or disabled pagination controls can make click automation unreliable.
| Workflow block | What it does | Validation point |
|---|---|---|
| Navigate | Opens each configured SEEK listing or search URL | One input URL should map to a reproducible search. |
| Wait and Sleep | Gives the rendered page time to load job cards | Increase waits if cards appear late or partially. |
| Element Exists | Confirms normal, premium, standout, or job-card articles | Empty result pages should skip export cleanly. |
| Structured Export | Appends visible card data to seek-listing-scraper.csv | Confirm headers, save folder, and append mode. |
| Inject JavaScript | Finds and opens the next pagination URL | Spot-check that page 2 continues the same search. |
Runbook
How to scrape SEEK jobs to CSV
Prepare the source URL
Build the SEEK search in your browser, then copy the final URL after all filters are applied. Keep that URL beside the CSV so the export can be audited later.
Import the template
Open SEEK Job Scraper by URL, download the workflow JSON, and import it into UScraper.
Replace sample URLs
In Navigate, replace the bundled examples with your approved SEEK URLs. Use separate entries for different role families, cities, classifications, or remote filters.
Set the export path
In Structured Export, confirm seek-listing-scraper.csv, headers, append mode, and a project-specific local save folder.
Run and validate
Run one filtered URL, compare the CSV against the visible page, then widen the input list only after titles, companies, locations, salaries, and dates match.
Append mode is helpful for pagination and multi-URL loops, but it will also preserve duplicate test rows. Use a dated filename or clear the file before a production rerun.
Output
What the SEEK job listing CSV includes
The workflow exports both page context and listing fields. That matters when the same role appears under multiple searches, because the input metadata tells you which keyword, classification, location, work type, salary filter, or listed-time filter produced each row.
| Field group | Columns |
|---|---|
| Input and page metadata | Input_URL, Total_job, Input_keyword, Input_classification, Input_where, Page_title, Page_URL |
| Filters | Filter_Work_types, Filter_Remote, Filter_salary_from, Filter_salary_to, Filter_listed_time |
| Job card data | Job_title, Job_URL, Company, Company_URL, Company_logo_URL, Job_location, Salary |
| Listing details | Bullet_points, Short_intro, If_featured, Job_listing_date |
seek-listing-scraper.csvColumn
Input_URL
The SEEK search or listing page that produced the row.
Column
Job_title
Visible title from the job card.
Column
Company
Employer name when SEEK exposes it on the card.
Column
Job_location
Location text shown for the role.
Column
Salary
Salary text when included on the listing.
Column
Job_listing_date
Visible listed date or freshness text.
Sample rows
1 of many
| Input_URL | Job_title | Company | Job_location | Salary | Job_listing_date |
|---|---|---|---|---|---|
| Customer Support Specialist | Example Services Pty Ltd | Sydney NSW - Remote | AUD 70,000 - 80,000 | Listed 2 days ago |
Alternatives
SEEK scraping alternatives: UScraper, Octoparse, Apify, Browse AI, or code
The best SEEK scraper tool depends on how much control, custody, scheduling, and engineering you need. A local desktop workflow is useful for analyst-led exports where you want browser-level review and a CSV on your machine. A hosted actor or cloud robot can be better when you need scheduling, APIs, and managed infrastructure. Python or Scrapy gives the most control, but it also makes you responsible for rendering, pagination, selector drift, throttling, and validation.
| Option | Best fit | Trade-off |
|---|---|---|
| UScraper template | No-code CSV exports from known SEEK URLs in a local desktop app | You supervise runs and maintain selectors if SEEK changes layout. |
| Octoparse or Browse AI | Visual cloud scraping and reusable hosted tasks | Output shape, pricing, and data custody follow the vendor. |
| Apify actors | API-driven cloud scraping and scheduled jobs | You manage actor cost, input schema, and downstream storage. |
| Python or Scrapy | Custom pipelines and version-controlled extraction code | Requires engineering maintenance and stronger QA discipline. |
| Job search API | Approved production integrations | Availability depends on provider access, terms, coverage, and cost. |
For broader research, browse the full UScraper template library or related tutorials in the UScraper blog.
Frequently asked questions
SEEK listings may be publicly visible, but automated collection can still be limited by SEEK terms, robots rules, copyright, privacy law, database rights, and local regulations. Review the source policies, keep volume modest, do not bypass CAPTCHA or access controls, and get legal advice before using exports commercially.
Next step
Download the SEEK scraper template
Use this tutorial as the runbook and the template page as the download path. Import SEEK Job Scraper by URL, run a one-page smoke test, then expand only after the CSV matches the browser. That gives you a repeatable way to scrape SEEK listings by URL, export SEEK jobs to CSV, and keep the source search context attached to every row.