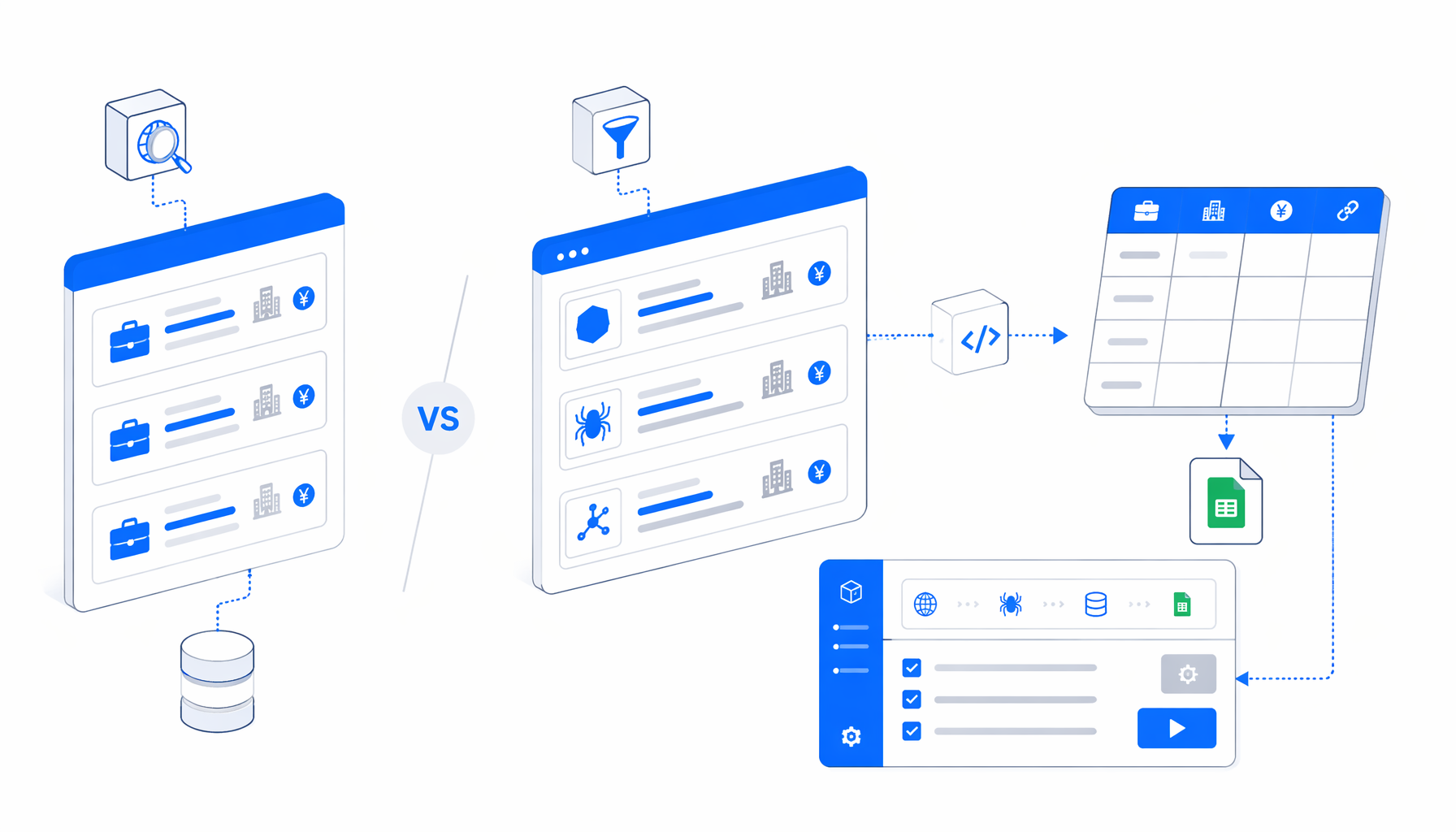
A Rikunabi NEXT scraper can mean a hosted marketplace actor, an Octoparse-style template, a no-code task, a script, or a local desktop workflow. This comparison is for teams that need Rikunabi NEXT job-detail data, especially a reviewed CSV from known job URLs.
The practical short path is the Rikunabi NEXT Job Scraper by URL template. It opens selected /viewjob/ pages, waits for render, extracts visible job and company sections, and appends one CSV row per page.
Decision frame
What Rikunabi NEXT scraper alternatives actually differ on
Most searches for rikunabi scraper alternatives hide a workflow question. Are you discovering jobs, extracting known URLs, feeding an API, or handing analysts a spreadsheet?
For Rikunabi NEXT, that distinction matters. URLs expire, sections vary by employer, and Japanese labels need careful UTF-8 handling. A good demo still fails if it does not fit your input list, hosting, output, and review process.
The useful comparison is not "which scraper is best?" It is "which scraper gives the right custody, output, cost model, and maintenance owner for this batch?"
Side-by-side
Rikunabi NEXT scraper alternatives compared
| Option | Best fit | Hosting | Code needed | Output shape | Pricing shape | Main trade-off |
|---|---|---|---|---|---|---|
| UScraper + Rikunabi NEXT Job Scraper by URL | Reviewed job-detail URLs exported to CSV | Local desktop app | Low | CSV with job, company, salary, benefits, contact, source URL | Free template; app licensing applies | Strong local control, not an unattended cloud crawler |
| Octoparse Rikunabi NEXT template | No-code teams already using Octoparse tasks | Vendor SaaS plus visual builder | Low | Table exports from configured task runs | Plan, task, and cloud-feature limits | Mature no-code environment, less local custody over runs |
| Apify Rikunabi actors | Developers who want hosted actors, APIs, datasets, and schedules | Vendor cloud | Low to medium | JSON, CSV, Excel, dataset API | Platform usage plus actor or result meters | Powerful automation, more billing variables and cloud custody |
| ParseHub or similar visual SaaS tools | Teams that want a general-purpose visual scraper | Vendor or hybrid app workflow | Low to medium | Tables, files, or integrations | SaaS plan limits | Flexible, but you still maintain selectors and task logic |
| Scraper APIs | Production pipelines, retries, proxies, and backend integration | Vendor infrastructure | Medium | HTML, JSON, or API responses | Request, bandwidth, proxy, or contract pricing | Best for scale, overbuilt for a small reviewed CSV |
| Python or JavaScript scripts | Engineering teams that need custom parser ownership | Your environment | High | Whatever your code writes | Developer time plus maintenance | Maximum control, maximum upkeep |
UScraper fit
Where UScraper wins for Rikunabi NEXT job URLs
UScraper wins when the team already has a list of approved Rikunabi NEXT /viewjob/ URLs and needs a visible, repeatable export. The template is intentionally URL-first. It does not promise to crawl the whole job board. It loops through known detail pages, waits for page load and application text, then writes an append-mode CSV.
That shape is useful for recruiting analysts, researchers, and operations teams. If a row is blank, you can watch the browser and find the cause: stale URL, 404, slow page, changed label, verification state, or a missing field.
| UScraper column group | Example fields | Why it matters |
|---|---|---|
| Employer identity | 会社名, company homepage, Rikunabi company page | Keeps the job connected to the hiring organization |
| Job detail | description, required profile, location, salary, hours | Supports role benchmarking and compensation review |
| Work conditions | holidays, benefits, welfare text | Helps compare employer positioning and offer quality |
| Company facts | representative, capital, revenue, headcount, office, industry | Adds context for company research |
| Traceability | ページURL | Lets reviewers reopen the original job page |
The subscription-model advantage is not that UScraper is always cheaper. It is that a bounded local run is easier to reason about: import the workflow, review URLs, choose a CSV folder, run the loop, and inspect the file. Cloud platforms may add actor pricing, compute time, proxies, storage, transfer, or scheduled task volume.
Alternatives
When another Rikunabi scraper alternative is better
Apify is the stronger fit when developers need hosted execution, API access, result datasets, integrations, and repeat schedules. It is also more natural when scraping is part of a backend system rather than an analyst-operated desktop workflow.
Checklist
How to choose the right Rikunabi NEXT job scraper
Before choosing a tool, write down five answers. They decide the category faster than feature lists.
- Input: Do you have approved job-detail URLs, or do you need search discovery?
- Output: Do you need CSV for analysts, JSON for engineers, or a live API feed?
- Hosting: Should the run happen locally, in a vendor cloud, or in your own infrastructure?
- Maintenance: Who fixes stale URLs, changed selectors, blank rows, and expired postings?
- Compliance: Have you reviewed Rikunabi NEXT terms, privacy pages, robots directives, and internal data-use rules?
If the answers are "known URLs, CSV, local, analyst-owned, reviewed batch," start with UScraper. If they are "large discovery, API, cloud, developer-owned, scheduled pipeline," Apify or a scraper API usually fits better.
FAQ
Rikunabi NEXT scraper FAQ
Next step
Try the Rikunabi NEXT by URL workflow
For a bounded comparison project, start with 5 to 10 current Rikunabi NEXT job URLs, import the Rikunabi NEXT Job Scraper by URL, and confirm the CSV columns before scaling. You can also browse the UScraper template library or related UScraper blog guides for other job-board workflows.