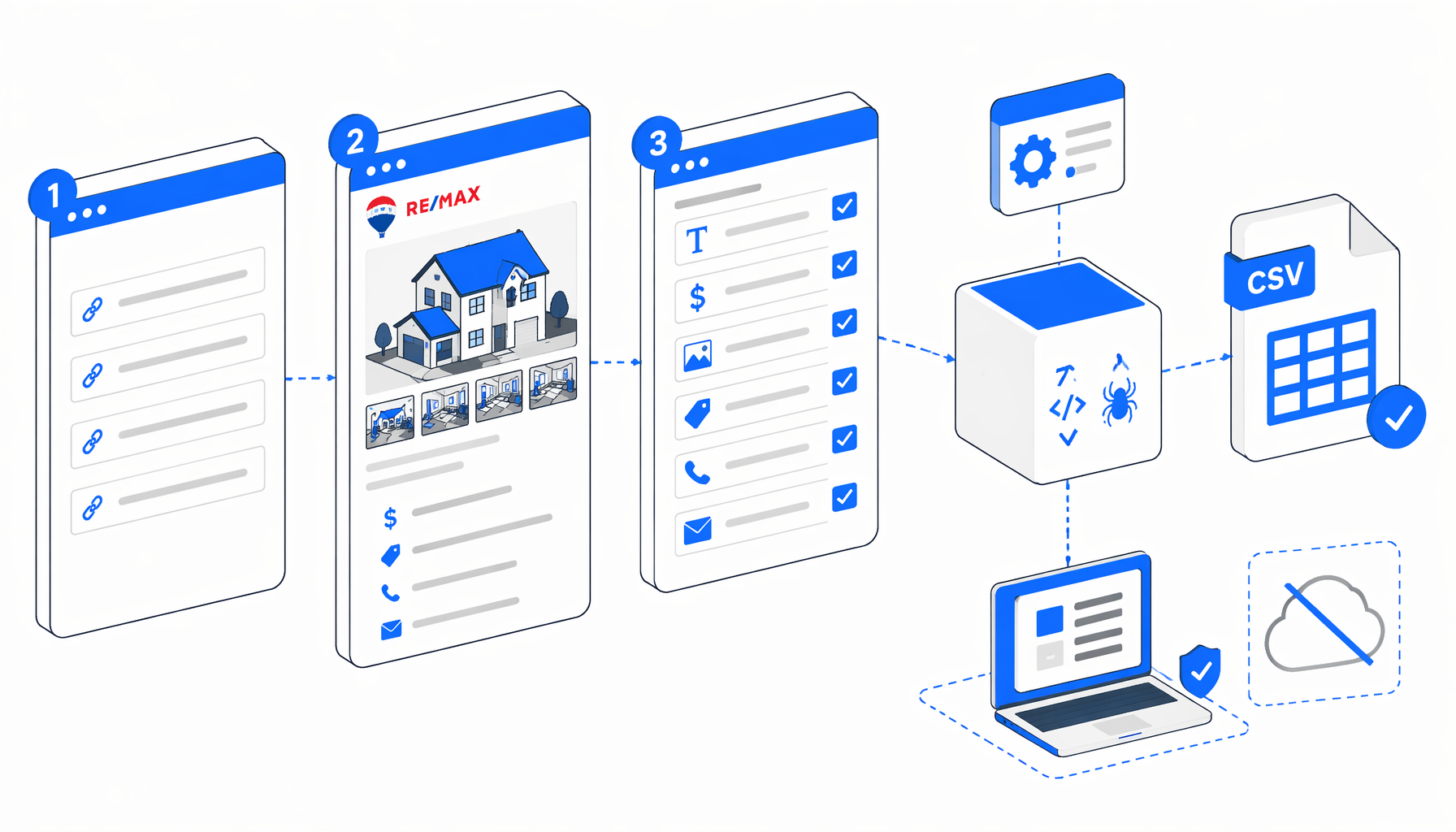
This RE/MAX scraping tutorial shows how to scrape RE/MAX property detail pages into CSV with the RE/MAX Details Scraper template for UScraper. You will import the workflow, replace starter URLs, set the export path, run a validation batch, and audit the final property rows.
Before you start
Prerequisites, scope, and RE/MAX access checks
You need UScraper installed as a local desktop app, the RE/MAX Details Scraper template, a writable export folder, and a short list of RE/MAX property detail URLs you are allowed to process. This detail-page workflow is not meant to discover every listing from the official RE/MAX homes for sale search. For discovery, start with the RE/MAX Listing Scraper, then send approved URLs into this tutorial.
Before running, review the source rules. RE/MAX publishes terms of use and a robots.txt file; Google's robots.txt guide explains that robots.txt controls crawler access, not general permission. Treat those materials as compliance inputs, not legal advice.
Technical access is not permission. Keep first runs small, avoid bypassing access controls, and document why each URL belongs in your research set.
Workflow
What the RE/MAX property details scraper exports
The JSON template is the authoritative workflow definition:
Set Window Size -> Navigate -> Wait for Page Load -> Sleep
-> Wait for Element -> Structured Export -> Loop Continue
Navigate owns the URL list, the waits let each page render, Structured Export appends a row, and Loop Continue advances.
| CSV area | Columns | What to validate |
|---|---|---|
| Identity | titulo, titulo_2, id | Confirm the headline, subtitle or address-like text, and RE/MAX listing ID match the open page. |
| Media | imagen_1 through imagen_5 | Check that image URLs come from the property gallery, not logos, icons, agent photos, or related listings. |
| Commercial detail | precio, condicion | Compare price, currency, monthly labels, lot size, rooms, baths, build area, and other feature text. |
| Long-form detail | descripcion | Confirm the description is the property narrative, not navigation, footer, or unrelated recommendation text. |
| Contact fields | celular, correo | Validate phone and email before using them for CRM import, enrichment, or manual follow-up. |
Runbook
How to scrape RE/MAX property details to CSV
Import the template
Open RE/MAX Details Scraper from the template library, download the JSON workflow, and import it into UScraper.
Replace the sample URLs
Open Navigate and replace the included RE/MAX Paraguay property URLs with detail pages you reviewed. Keep the list short until your export fields look correct.
Confirm browser access
Open one target page manually in the same browser context. If the page shows a consent wall, verification screen, removed listing, or missing detail layout, resolve that state before running.
Set the CSV destination
In Structured Export, confirm remax_detalles_scraper.csv, headers enabled, append mode, and a local folder for the project, market, or client.
Run and compare
Run a short batch while watching the browser. Compare title, price, images, listing ID, condition text, description, phone, and email against the live RE/MAX pages.
If the first rows look right, add URLs in controlled batches. If a row is partial, reopen the original page and check whether the missing section is visible. A blank cell can mean the page omitted that field, rendered late, changed layout, or blocked access.
Validation
Check the CSV before you trust it
The bundle does not include a sample CSV, so the configured export shape is the contract. A healthy row should have a real property title, price, listing ID, and source-specific details where the page exposes them. Optional image, contact, and feature fields can be blank on pages that do not publish those values.
| titulo | titulo_2 | precio | id | condicion | celular | correo |
|---|---|---|---|---|---|---|
Local comercial en alquiler | Luque | USD 2,500 Mensual | 143068006-165 | Total Mts 180 | Banos 2 | +595 981 123 456 | [email protected] |
Duplex en venta | Villa Elisa | Gs. 850.000.000 | 143068006-168 | Dormitorios 3 | Banos 2 | +595 982 456 789 | [email protected] |
For analysis work, keep the original URL list beside the CSV. It lets your team trace any row back to the property page before joining the export with a real estate listings map, real estate property map, valuation model, or CRM list.
Alternatives
RE/MAX scraper alternatives and trade-offs
There is no single best RE/MAX scraper for every team. Hosted actors, scraper APIs, and managed data providers can be useful when you need scheduling, large cloud runs, dashboards, or service guarantees. Custom code can be better when developers need tests and deeper integration.
The UScraper template is a better fit when an analyst already has a reviewed URL list and wants a no-code, local CSV workflow. You can watch pages load, see which block writes each row, and adjust the export path without deploying infrastructure.
Common issues and fixes
Check the live page first. RE/MAX pages can omit phone, email, image, feature, or description sections. If the field is visible but missing from the CSV, rerun one URL and adjust waits or selectors before scaling.
FAQ
Frequently asked questions
Is it legal to scrape RE/MAX property details?
RE/MAX pages can be publicly visible and still be governed by terms of use, robots guidance, broker agreements, copyright, privacy laws, and local real estate rules. Use conservative pacing, do not bypass access controls, and get legal review before commercial reuse.
Do I need a RE/MAX account or API key?
No RE/MAX account or API key is built into this tutorial. The workflow opens supplied detail URLs, waits for the visible page body, and exports fields when the page is accessible.
What does the RE/MAX details scraper export?
The template writes remax_detalles_scraper.csv with titulo, titulo_2, imagen_1 through imagen_5, precio, id, condicion, descripcion, celular, and correo. Headers are enabled, and append mode adds one row per accessible URL.
How many RE/MAX property pages should I run at once?
Start with one to five detail URLs. Validate every field, then expand only when the exported rows match the live pages. Practical batch size depends on permission, pacing, site changes, verification prompts, and page speed.
When should I use a RE/MAX scraper alternative?
Use a hosted actor, managed data provider, API, or custom code when you need scheduling, large cloud runs, service guarantees, proxy management, or licensed data access. Use the UScraper template when local CSV custody matters more.
Next steps
Use RE/MAX Details Scraper as the download path, then browse the UScraper template library and blog for adjacent real estate workflows.