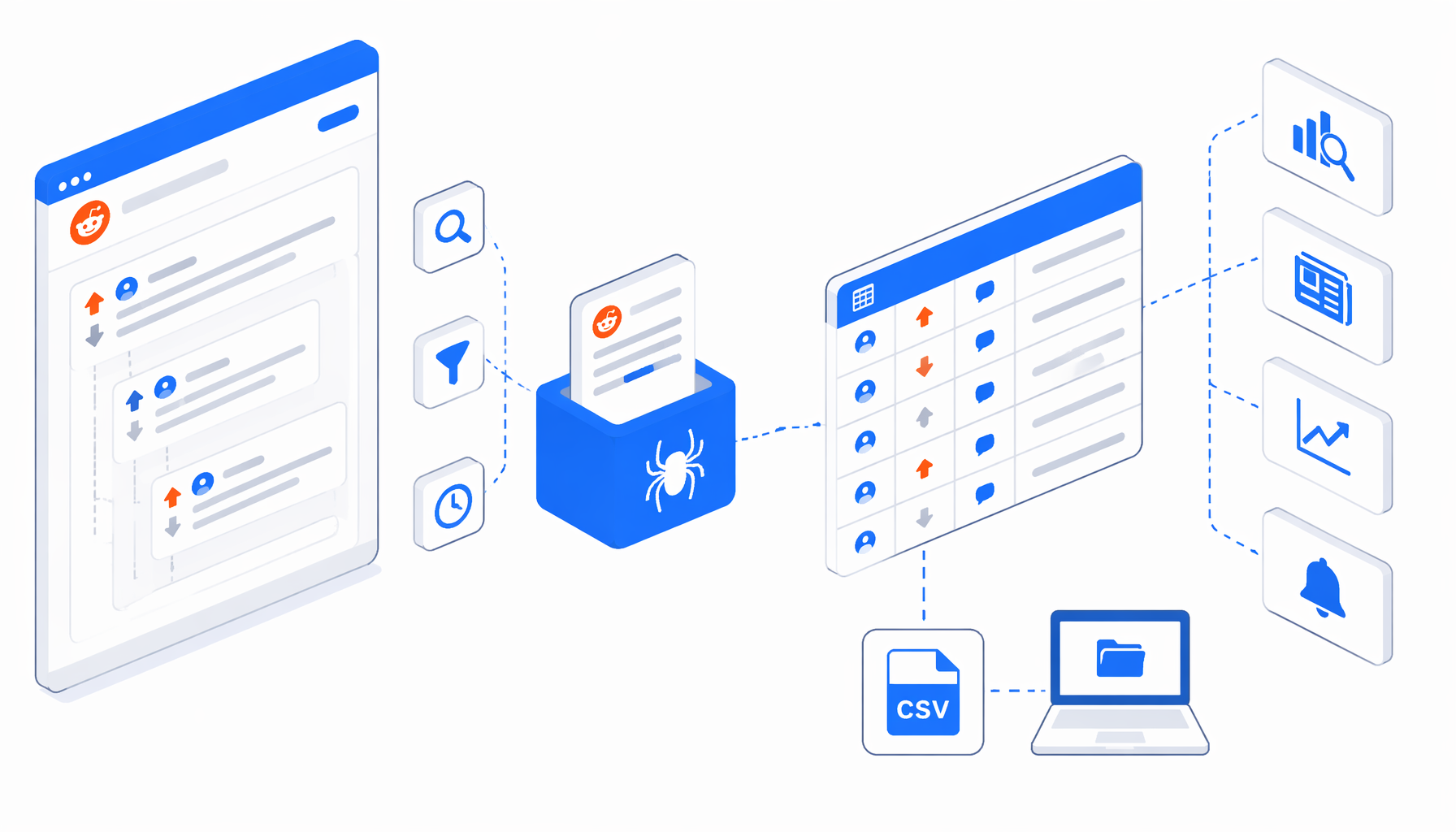
A Reddit post comments scraper is useful when a team already has a focused set of threads and needs a reviewable dataset instead of copied comments. The Reddit Post Comments Scraper template turns accessible Reddit thread responses into a local CSV with post context, main comments, replies, nested comment fields, scores, timestamps, links, and media URLs.
Use-case frame
When Reddit comments become research data
Reddit threads are often where people explain the problem in their own language: complaints, product comparisons, local observations, workarounds, purchase hesitations, and questions that never make it into a survey. That makes Reddit useful for qualitative research, newsroom backgrounding, SEO topic mining, and brand monitoring.
The manual workflow is fragile. Someone opens a post, copies comments into a sheet, loses the source permalink, misses nested replies, and later cannot prove which thread produced which quote. A structured export fixes the shape: one row per main comment, repeated post context, a comment link, first reply fields, deepest nested comment fields, and timestamps.
Treat a Reddit comments export as a working dataset, not a license to republish everything inside it.
Start every project with Reddit's official Data API Wiki, Data API Terms, Developer Terms, and API documentation. If your plan involves a product, recurring pipeline, model training, redistribution, or high-volume collection, get legal review and consider approved API access before choosing any scraper.
Personas
Who uses a Reddit post comments scraper?
| Persona | Pain | CSV outcome |
|---|---|---|
| Social researchers | Comments are rich, but manual coding loses source context. | Export thread title, subreddit, author fields, text, timestamps, and comment links for coding. |
| Newsrooms | Reporters need a documented sample around a public issue. | Preserve source URLs and comment metadata for background review before quoting or publishing. |
| SEO and content teams | Search keyword tools miss the exact words people use in debates. | Extract question phrasing, objections, comparisons, and repeated language from known threads. |
| Product marketers | Competitor mentions and feature complaints are scattered across threads. | Build a review sheet for pains, alternatives, pricing objections, and recurring feature requests. |
| Monitoring analysts | Incident conversations move quickly and branches get deep. | Save a bounded snapshot with main comments, first replies, deepest nested comments, and scores. |
Pew Research Center's Reddit parenting methodology is a good example of disciplined collection design: define the community, date window, source, fields, classification method, and review process before analysis. A scraper template does not replace that research plan; it only helps produce the rows.
Workflows
Concrete Reddit comments scraper use cases
Research datasets for qualitative coding
Researchers can export comments from a small set of relevant posts, then code the CSV for themes such as cost concerns, support needs, buyer language, health questions, or product workarounds. The important fields are main_comment_text, reply_text, last_level_comment_text, comment_link, and the parent post title. That keeps each quote tied to context.
Newsroom and public-interest monitoring
A newsroom might track a public service outage, local policy debate, product recall, or fast-moving community concern. A Reddit comments scraper is useful for background review and lead generation, but reporters still need editorial standards, screenshots where appropriate, source verification, and consent-aware decisions before publishing user comments.
SEO topic mining and content briefs
SEO teams can use Reddit exports to find the questions and objections behind keywords such as how to scrape reddit comments, reddit api vs scraping, or broader product-category searches. Instead of guessing search intent from volume alone, the team can inspect live phrasing, compare repeated questions, and turn useful patterns into briefs.
Product and competitor intelligence
Product marketers can export threads where users compare tools, complain about workflow friction, or describe why they switched. The CSV makes it easier to tag themes, count repeated objections, and separate a single loud comment from a pattern across multiple threads.
AI and NLP review samples
For model evaluation, labeling, or prompt testing, a bounded Reddit comments research dataset can provide realistic messy language. Keep the scope narrow, remove fields you do not need, and review policy requirements before using any user-generated content for training or redistribution.
Template fit
How the UScraper template turns pain into output
The problem
Manual copying loses comment links, timestamps, and post context.
What you do instead
Export a consistent CSV row shape.
The template repeats subreddit, post title, post score, author, comment link, text, reply fields, and nested comment fields in fixed columns.
The problem
Nested replies are hard to audit in a spreadsheet.
What you do instead
Capture first reply and deepest nested comment fields.
Analysts get enough thread structure for fast review without reconstructing the full Reddit comment tree by hand.
The problem
Hosted scraper tools may be more infrastructure than a one-off review needs.
What you do instead
Run a visual workflow in a local desktop app.
The stock workflow writes a local CSV path and keeps the automation graph inspectable before each run.
The problem
Blank or blocked responses can silently pollute analysis.
What you do instead
Validate generated rows before exporting at scale.
The workflow checks for generated rows, and the bundled sample fallback is explicitly marked as an output-shape preview.
The workflow loops through multiple Reddit thread JSON URLs, waits for each response, injects JavaScript to parse accessible Reddit JSON, creates temporary hidden rows, then uses Structured Export to append rows into reddit-post-comments-scraper.csv.
| Export group | Columns to inspect |
|---|---|
| Post context | subreddit, post_title, post_upvote, post_author, post_text, number_of_comments, post_image |
| Main comment | comment_link, main_comment_author, main_comment_post_time, main_comment_upvote, main_comment_text, main_comment_image |
| First reply | reply_user, reply_text, reply_upvote, reply_time, reply_image |
| Deepest nested comment | last_level_commment_author, last_level_comment_text, last_level_upvote, last_level_comment_time |
Operating model
Reddit API vs scraping for real workflows
The Reddit API vs scraping choice depends on the job. PRAW's comment extraction tutorial is the better path when an engineer needs Python control over comment forests, authentication, replacement of more-comment objects, retries, storage, and custom output schemas. A scraper template is better when an analyst needs a supervised CSV from a known list of post URLs.
Use the UScraper Reddit Post Comments Scraper for bounded, no-code exports where the reviewer wants a visual workflow and a local CSV.
Runbook
How to start from the template
Open the template
Go to the Reddit Post Comments Scraper template and import the JSON workflow into UScraper.
Replace sample inputs
Add the Reddit thread JSON URLs your project is allowed to collect. Keep the first test to one or two posts.
Set the CSV folder
Confirm the file name, headers, append mode, and local save location before running a client, newsroom, or research batch.
Validate the first rows
Open the CSV, check several comment links against source threads, and confirm that blank reply fields are expected.
For implementation details, use the companion how-to guide. For buying criteria across best Reddit scraper tools, read the comparison guide or browse the wider template library.
FAQ
Reddit post comments scraper FAQ
Researchers, newsrooms, SEO teams, product marketers, social listening analysts, and data reviewers use it when they have a defined set of Reddit thread URLs and need a structured CSV for review.
CTA
Turn Reddit threads into a reviewable CSV
If your team has a finite list of Reddit threads and needs a spreadsheet-ready dataset, start with the Reddit Post Comments Scraper template. Import the workflow, replace the sample URLs, run one thread, validate the rows, and then expand only as far as your research plan allows. For adjacent tutorials and scraper playbooks, browse the UScraper blog.