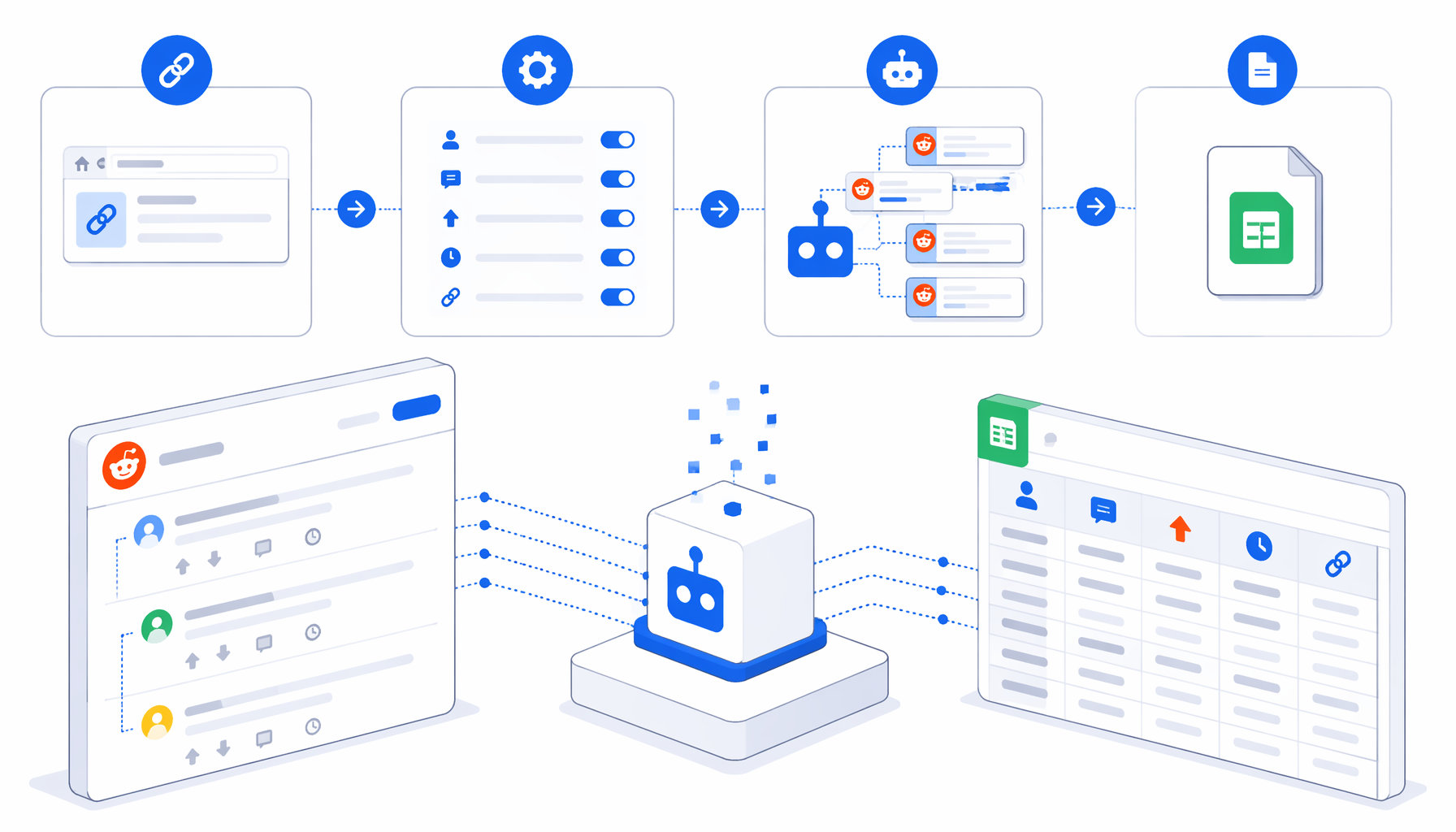
This tutorial shows how to scrape Reddit comments into CSV with the free Reddit Post Comments Scraper template for UScraper. You will import the workflow, replace the sample URLs, set the export folder, run a small batch, and validate authors, replies, scores, timestamps, links, and block diagnostics before collecting more threads.
CSV
25
Multi-URL
Included
Local
Scope
Prerequisites before you scrape Reddit comments
You need UScraper installed as a local desktop app, the free Reddit Post Comments Scraper template, a folder for the CSV, and a short list of Reddit thread or comment URLs you are allowed to process. Start with one to three URLs. Reddit pages can vary by login state, region, rate, age restrictions, subreddit settings, moderation state, and network policy responses, so a small validation run is more useful than a large first batch.
This workflow is for bounded exports from known public discussion URLs. It is not a Reddit crawler for every post in a subreddit, not a CAPTCHA bypass, not a private-message collector, and not a substitute for approved API access. If you are building an app, recurring product, research pipeline, resale dataset, or AI training corpus, start with Reddit's official API documentation, Data API Wiki, Developer Terms, and Data API Terms.
Technical access is not the same as permission. Keep the scope narrow, preserve source URLs, stop at access blocks, and get legal review before commercial reuse.
Workflow
How the free Reddit post comments scraper works
The JSON export is the authoritative sample of the workflow definition. In plain English, the graph follows this path:
Set Window Size -> Navigate URL list -> Wait for Page Load
-> Check block-message text -> Wait for post -> Expand load-more comments
-> Structured Export -> Sleep -> Loop Continue
The important design choice is the blocked branch. During analysis, Reddit returned 403 network-policy blocks for some URLs. The template therefore checks for that message and writes scrape_status=blocked_by_reddit_network_policy with a block_message excerpt. That makes bad URLs visible in the CSV instead of producing an empty file that looks like a scraper bug.
| Workflow block | Purpose | What to verify |
|---|---|---|
| Navigate | Stores the finite list of Old Reddit URLs | Replace the sample URLs with approved thread or comment links. |
| Text Contains | Detects Reddit network-policy block text | Keep the blocked branch connected to the diagnostic export. |
| Element Exists + Click | Expands visible .morecomments links | Watch the browser during the first run to confirm expansion. |
| Structured Export | Writes comment rows to reddit-scraper.csv | Confirm headers, append mode, file name, and save folder. |
| Loop Continue | Moves to the next URL | Keep it at the end of each branch so multi-URL runs finish cleanly. |
Runbook
How to export Reddit comments to CSV
Import the free template
Open Reddit Post Comments Scraper Free, download the JSON template, and import it into UScraper.
Replace the URL list
Edit the Navigate block and paste the Reddit post or comment permalinks you are approved to collect. Keep the first run short so validation is easy.
Set the export path
Open Structured Export and confirm reddit-scraper.csv, headers enabled, append mode, and a project-specific save location.
Run one thread first
Execute one URL while watching the browser. Confirm the post loads, comment rows appear, load-more links expand when present, and no block page replaces the discussion.
Validate before scaling
Compare a few CSV rows against the live thread, check scrape_status, remove test rows if needed, then widen the Navigate list only after the first sample is clean.
Because file mode is append, reruns add rows to the same file. For repeatable research, use a dated CSV name, archive the raw file, and dedupe by source_url, Comment_link, author, timestamp, and comment-text hash.
Output
Reddit comments CSV columns
No CSV sample ships in the bundle, so use the JSON workflow definition and the export shape below as the reference. The template writes post metadata next to comment, reply, deepest-comment, status, and source fields so reviewers can trace every row back to the page that produced it.
| Field group | Columns |
|---|---|
| Post context | Subreddit, Post_title, Post_upvote, Post_author, Post_text, Number_of_comments, Post_image |
| Main comment | Comment_link, Main_comment_author, Main_comment_post_time, Main_comment_upvote, Main_comment_text, Main_comment_image |
| Reply fields | Reply_user, Reply_text, Reply_upvote, Reply_time, Reply_image |
| Deepest visible level | Last_level_commment_author, Last_level_comment_text, Last_level_upvote, Last_level_comment_time |
| Audit fields | source_url, scrape_status, block_message |
reddit-scraper.csvColumn
Subreddit
Subreddit parsed from the page or URL.
Column
Post_title
Visible post title.
Column
Main_comment_author
Top-level comment author for context.
Column
Main_comment_text
Top-level comment text.
Column
Reply_text
Reply text when the row is nested.
Column
Comment_link
Permalink for row-level audit.
Column
scrape_status
ok or blocked_by_reddit_network_policy.
Column
block_message
Excerpt from the block page when access fails.
Troubleshooting
Common Reddit scraper issues
Reddit returned a network-policy block page. Keep the diagnostic row, stop that URL set, and use approved API access, developer credentials, a trusted browser profile, or a smaller permitted scope where appropriate.
Next steps
Download the free Reddit comments scraper template
Use this article as the runbook and the Reddit Post Comments Scraper Free template as the download path. Import the JSON, replace the sample URLs, run one thread, validate reddit-scraper.csv, and keep the diagnostic columns in every export.
For broader tool selection, read the Reddit scraper tools comparison, browse the UScraper template library, or continue through the UScraper blog for more no-code scraping tutorials.